Piece it Together— Bria AI等机构推出的图像生成框架
时间:2025-03-28 | 作者: | 阅读:0piece it together (pit):一款革命性的图像生成框架
Bria AI 等机构推出的 Piece it Together (PiT) 是一款突破性的图像生成框架,能够基于部分视觉组件生成完整的概念图像。它利用特定领域的先验知识,将用户提供的碎片化视觉元素巧妙地整合到一个连贯的整体中,并智能地补充缺失部分,最终生成完整且富有创意的概念图像。PiT 采用 IP-Adapter+ 和 IP+ 空间,并训练轻量级流匹配模型 IP-Prior,从而实现高质量的图像重建和语义操作。通过 LoRA 微调策略,PiT 显著提升了文本遵循性,使其能够更好地适应各种场景,成为创意设计和概念探索的强大工具。
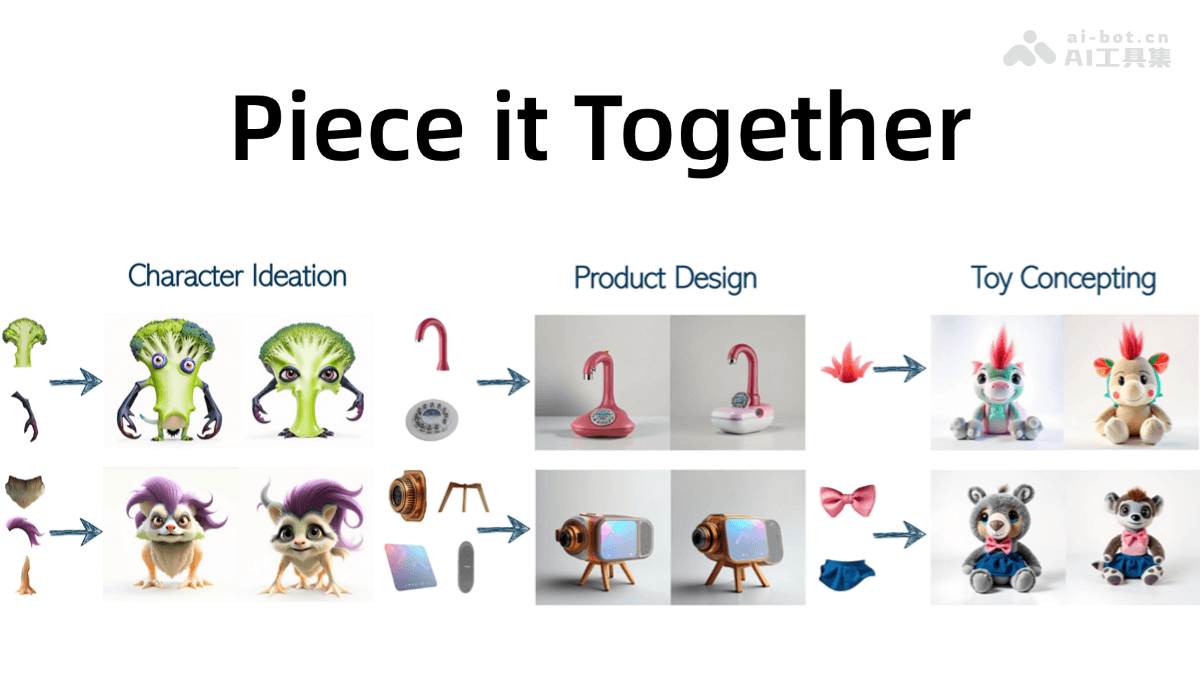 PiT 的核心功能:
PiT 的核心功能:
- 碎片化视觉元素的整合: 将用户提供的零散视觉组件(例如独特的翅膀、特殊的发型等)无缝融合到完整的图像构图中。
- 缺失部分的智能补充: 在整合现有元素的同时,自动生成缺失的部分,使图像完整。
- 多样化概念生成: 针对同一组输入元素,能够生成多种不同的概念图像变体。
- 语义操作与编辑: 在 IP+ 空间中支持语义操作,允许用户对生成的图像进行进一步的编辑和调整。
- 增强文本遵循性: 通过 LoRA 微调,提升了对文本提示的遵循能力,使生成的图像更符合用户的文本描述,并增强图像的多样性和适用性。
PiT 的技术原理:
- IP+ 空间: 基于 IP-Adapter+ 的内部表示空间(IP+ 空间),相比传统的 CLIP 空间,IP+ 空间在保留复杂概念和细节方面表现更优,并支持语义操作,为高质量的图像重建和概念编辑奠定了基础。
- IP-Prior 模型: 一个轻量级的流匹配模型,利用特定领域的先验知识,根据输入的部分视觉组件生成完整的概念图像。该模型能够根据目标领域的分布动态适应用户输入,并生成缺失的部分。
- 数据生成与训练: 利用 FLUX-Schnell 等预训练的文本到图像模型生成训练数据,并通过添加随机形容词和类别来增强数据多样性。采用分割方法提取目标图像的语义部分,形成训练数据对,训练 IP-Prior 模型以完成目标任务。
- LoRA 微调策略: 采用 LoRA 微调策略来改进 IP-Adapter+ 在文本遵循性方面的不足。通过少量样本训练 LoRA 适配器,恢复文本控制能力,确保生成的图像更好地遵循文本提示,同时保持视觉保真度。
PiT 的项目信息:
- 项目官网: https://www.php.cn/link/6ed459ea169d96c38c7167d4cf471013
- GitHub 仓库: https://www.php.cn/link/6ed459ea169d96c38c7167d4cf471013
- arXiv 技术论文: https://www.php.cn/link/6ed459ea169d96c38c7167d4cf471013
PiT 的应用领域:
- 角色设计: 快速生成奇幻生物、科幻角色等完整角色设计,探索各种创意方向。
- 产品设计: 提供产品组件,生成完整概念图,验证设计思路并探索多种设计方案。
- 玩具设计: 输入玩具部分元素,激发创意,生成多种玩具概念,用于市场测试。
- 艺术创作: 提供艺术元素,生成完整作品,探索不同艺术风格,激发创作灵感。
- 教育培训: 应用于设计和艺术教学,快速生成创意概念,培养学生的创新思维和设计技能。

来源:https://www.php.cn/faq/1266246.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- 罗马拓荒录资源收集太肝?自动采集工具助你轻松管理帝国
- 时间:2026-05-26
-

- 我的世界中文版网页登录入口存档同步在线游玩
- 时间:2026-05-26
-

- 中国裁判文书网企业版官网登录入口与使用指南
- 时间:2026-05-26
-

- 灰烬之国电脑配置要求详解最低与推荐配置一览
- 时间:2026-05-26
-

- 零度空间全阵营兵种建筑与技能详解图鉴
- 时间:2026-05-26
-
- 零度空间游戏模式详解与玩法攻略
- 时间:2026-05-26
-
- 零度空间联机教程 详细步骤图文详解
- 时间:2026-05-26
-

- 零度空间试玩评测 这款RTS游戏为何被称为年度野心之作
- 时间:2026-05-26
精选合集
更多大家都在玩

大家都在看
更多-

- 原神妮露角色强度解析与培养攻略
- 时间:2026-05-26
-

- 王者荣耀世界游戏设置优化指南
- 时间:2026-05-26
-

- 三角洲行动M7战斗步枪最佳改装方案推荐
- 时间:2026-05-26
-

- 卡厄思梦境卢克卡牌技能效果详解
- 时间:2026-05-26
-
- 异环无名医院快速通关攻略与实用技巧
- 时间:2026-05-26
-
- 王者荣耀世界体力高效规划指南与技巧
- 时间:2026-05-26
-

- 烹饪青菜时,以下哪种做法更能保持营养和口感 蚂蚁庄园今日答案5.25
- 时间:2026-05-26
-

- 光遇5月26日每日任务怎么做 图文攻略详解
- 时间:2026-05-26