Mini DALL·E 3— 北京理工联合上海 AI Lab等高校推出的交互式文生图框架
时间:2025-04-04 | 作者: | 阅读:0mini dall·e 3:一款强大的交互式文本到图像生成框架
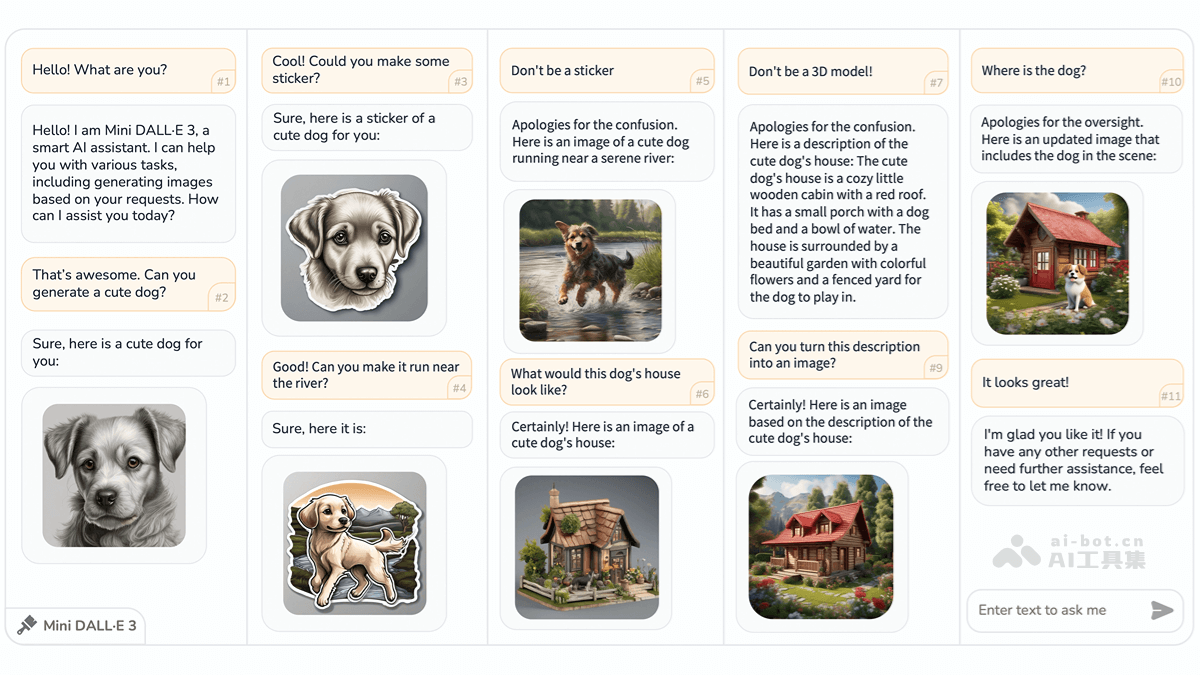
Mini DALL·E 3是由北京理工大学、上海AI Lab、清华大学和香港中文大学联合开发的创新型交互式文本到图像(iT2I)框架。它通过自然语言与用户进行多轮对话,实现高质量图像的生成、编辑和优化。用户只需使用简单的指令逐步完善图像需求,系统便能基于大型语言模型(LLM)和预训练的文本到图像模型(如 Stable Diffusion),在无需额外训练的情况下生成与文本描述高度吻合的图像。 此外,系统还具备问答功能,提供更流畅、便捷的人机交互体验,显著提升图像生成质量。
核心功能:
- 交互式图像创作: 用户以自然语言表达需求,系统即刻生成匹配的图像。
- 灵活的图像编辑与优化: 支持用户修改图像,系统根据反馈迭代优化。
- 内容连贯性: 多轮对话中,图像主题和风格保持一致。
- 问答功能: 用户可随时询问图像细节,系统会结合上下文给出答案。
技术架构:
Mini DALL·E 3 巧妙地结合了大型语言模型 (LLM) 和文本到图像模型 (T2I)。LLM (例如 ChatGPT 或 LLAMA) 负责解析用户的自然语言指令,并生成相应的图像描述。 通过提示工程技术,系统引导 LLM 生成符合要求的文本描述,并利用
T2I 模型则负责将 LLM 生成的图像描述转化为实际图像。系统会根据描述的复杂度和内容变化幅度,选择合适的 T2I 模型,以确保图像质量和生成效率。 一个层次化的内容一致性控制机制,通过运用不同层次的 T2I 模型,灵活处理细微的风格调整或大幅度的场景重构。 系统利用前一次生成的图像作为上下文输入,确保多轮生成中图像内容的一致性。
整个系统架构包含 LLM、路由器 (router)、适配器 (adapter) 和 T2I 模型四个主要组件。路由器负责解析 LLM 的输出,识别图像生成需求并将其传递给适配器。适配器则将图像描述转换为 T2I 模型可接受的格式,最终由 T2I 模型生成图像。
资源链接:
- 项目官网: https://www.php.cn/link/7b6ce75e5d95acc103465e3522f9d2fd
- GitHub 仓库: https://www.php.cn/link/7b6ce75e5d95acc103465e3522f9d2fd
- arXiv 技术论文: https://www.php.cn/link/7b6ce75e5d95acc103465e3522f9d2fd
应用前景:
Mini DALL·E 3 在创意设计、故事创作、概念设计、教育教学以及娱乐互动等领域拥有广泛的应用前景,例如:
- 创意内容生成: 生成艺术作品、插画、海报等。
- 故事插图创作: 为小说、童话、剧本等生成配套插图。
- 概念原型设计: 在产品设计和建筑设计中快速生成概念图和原型。
- 教育辅助工具: 提供直观的图像辅助学习,帮助理解抽象概念。
- 互动娱乐体验: 在游戏和社交媒体中生成个性化图像,增强用户体验。

来源:https://www.php.cn/faq/1271612.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- SBTI人格测试类型解析与分类指南
- 时间:2026-06-20
-

- 听番FM播放速度调节教程
- 时间:2026-06-20
-

- 书痴app如何导入书源详细步骤与技巧
- 时间:2026-06-20
-

- C++ STL multiset使用教程与指南
- 时间:2026-06-20
-

- 腹腔镜操作入门练习技巧详解
- 时间:2026-06-20
-

- 软碟通保存时重新编译ISO文件的方法
- 时间:2026-06-20
-

- podo漫画搜索教程:快速找到你想看的漫画
- 时间:2026-06-20
-

- eMule设置繁体中文语言的方法
- 时间:2026-06-20
精选合集
更多大家都在玩
热门话题
大家都在看
更多-

- 《PUBG:黑域撤离》二测将于6月26日至29日进行
- 时间:2026-06-21
-

- 《龙之信条2》大型DLC"黑暗觉者"将于10月9日正式发售
- 时间:2026-06-21
-

- 蚂蚁庄园今日答案最新6.21 6月21日庄园每日答题答案
- 时间:2026-06-21
-

- 《碧蓝幻想Relink?无尽黄昏》试玩版现已上线!
- 时间:2026-06-21
-

- 全新动作冒险游戏《地狱之刃:塞娜》将于2027年推出
- 时间:2026-06-21
-
- 中国科学家提出AI专用语言BabelTele 文本压缩至27.9%仍保持99.5%语义
- 时间:2026-06-21
-

- 24岁日本游客为免票岳阳楼景区全文背诵《岳阳楼记》:将挑战《蜀道难》
- 时间:2026-06-21
-

- 鸣潮3.5前瞻直播什么时候
- 时间:2026-06-21