如何在项目中使用DeepSeek开源推理引擎?
时间:2025-04-15 | 作者: | 阅读:0使用 DeepSeek 开源推理引擎的步骤包括:1. 安装依赖,如 CUDA 和 Python 库;2. 从官方渠道下载引擎并安装配置;3. 获取或转换模型文件;4. 导入模块、配置引擎、加载模型并执行推理;5. 进行性能优化和错误调试,以提高效率和解决问题。

环境准备
- 安装依赖:根据 DeepSeek 推理引擎的要求,安装相应的依赖库和软件,可能包括 CUDA(如果需要使用 GPU 加速)、Python 相关的科学计算库等。
- 下载引擎:从 DeepSeek 的官方开源代码库(如 GitHub 等)获取推理引擎的源代码或下载预编译的二进制文件。按照官方文档的说明进行安装和配置,确保引擎能够在本地环境中正常运行。
模型准备
- 获取模型:如果项目中使用的是 DeepSeek 提供的预训练模型,需要从其官方指定的渠道下载模型文件。如果是自己训练的模型,要确保模型的格式与 DeepSeek 推理引擎兼容。
- 模型转换(如有需要):有些情况下,模型可能需要进行格式转换或预处理,以便能够被推理引擎正确加载和使用。例如,将模型权重转换为特定的量化格式等,具体操作参考 DeepSeek 的文档说明。
代码集成
- 导入模块:在项目的代码中,导入 DeepSeek 推理引擎的相关模块,以便能够调用其功能。
- 配置引擎:根据项目需求,对推理引擎进行配置,如设置推理的参数(如批处理大小、精度要求等)、指定使用的设备(CPU 或 GPU)等。
- 加载模型:使用推理引擎提供的接口,将准备好的模型加载到内存中,以便进行推理计算。
- 执行推理:在项目中需要进行推理的地方,将输入数据按照引擎要求的格式进行整理,然后调用推理引擎的推理函数,传入输入数据,获取推理结果。推理结果可能是文本、图像、数值等不同类型,根据具体的任务和模型进行相应的处理和解析。
优化与调试
- 性能优化:根据项目的实际运行情况,对推理过程进行性能优化。这可能包括调整批处理大小、优化模型参数、利用硬件特性(如 GPU 的并行计算能力)等,以提高推理的速度和效率。
- 错误处理与调试:在使用过程中,可能会遇到各种错误和问题。通过查看推理引擎的日志信息、错误提示等,进行调试和问题排查。同时,对输入数据进行检查和验证,确保其符合模型的要求,以避免因数据问题导致的错误。

来源:https://www.php.cn/faq/1278794.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-
- 美团内部限用豆包 此前已限制阿里云Qwen
- 时间:2026-07-02
-
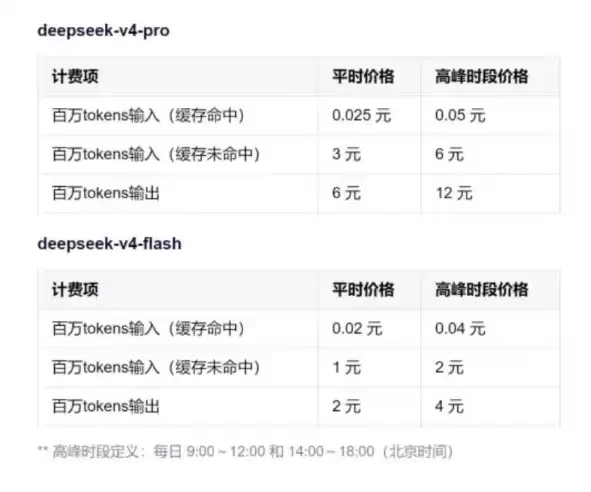
- 7月上线!DeepSeek V4正式版官宣:将引入峰谷定价机制
- 时间:2026-06-30
-

- DeepSeek专家模式使用指南
- 时间:2026-06-28
-

- 当贝智能鱼缸搭载全球首创双AI DeepSeek技术
- 时间:2026-06-26
-

- 极空间如何一步步本地部署DeepSeek模型
- 时间:2026-06-23
-

- 急缺人才!DeepSeek Harness负责人坦言每日不停面试招人
- 时间:2026-06-23
-

- DeepSeek导出Word文档的详细操作步骤
- 时间:2026-06-20
-

- DeepSeek文本分类任务实战指南与技巧
- 时间:2026-06-19
精选合集
更多大家都在玩
大家都在看
更多-

- 高考志愿填报模板完整版附表格填写示例
- 时间:2026-07-04
-
- 2026好玩的挂机手游推荐
- 时间:2026-07-04
-

- 高考志愿填报规划师职业前景与报考指南
- 时间:2026-07-04
-
- 高考志愿填报实用指导与技巧
- 时间:2026-07-04
-
- 高考志愿填报时间安排
- 时间:2026-07-04
-
- 高考志愿填报系统使用技巧与注意事项
- 时间:2026-07-04
-

- 高考志愿填报模拟系统指南
- 时间:2026-07-04
-
- 高考志愿填报方法与技巧详解
- 时间:2026-07-04