



















使用腾讯 HAI 5 分钟内部署一个私人定制的 DeepSeek
时间:2025-04-22 | 作者: | 阅读:0由于某些原因,在春节期间,deepseek 遭受了恶意的攻击,导致在撰写本文时,deepseek api 控制台仍未恢复访问。
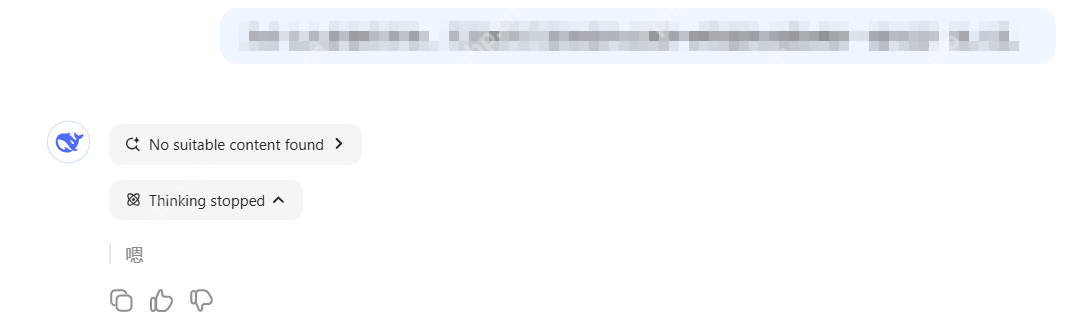
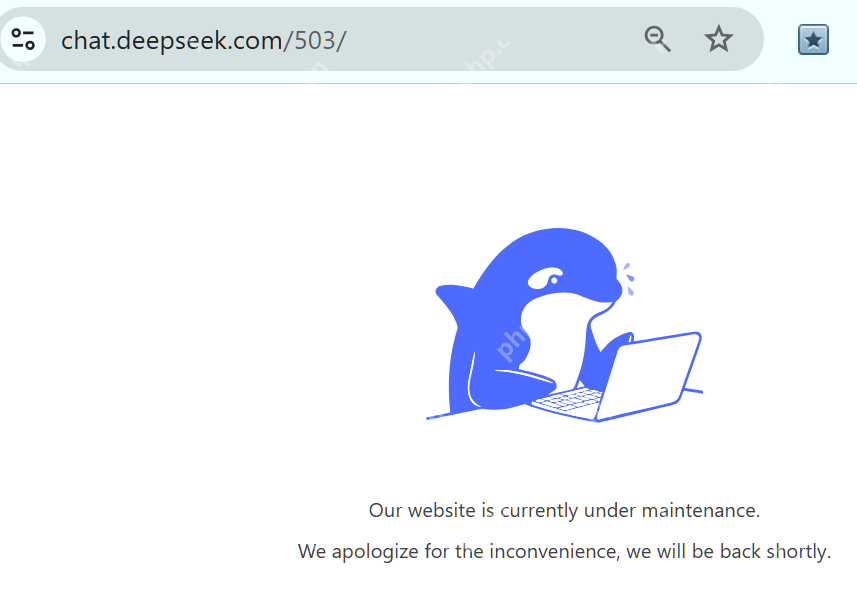 笔者在实际使用过程中也常常遇到 DeepSeek 无法按预期生成有意义的回复,或者服务器繁忙的情况。
笔者在实际使用过程中也常常遇到 DeepSeek 无法按预期生成有意义的回复,或者服务器繁忙的情况。
 我们知道,DeepSeek 是一个开源的大型模型,其开源性质最显著的表现是完整公开的模型架构设计。
我们知道,DeepSeek 是一个开源的大型模型,其开源性质最显著的表现是完整公开的模型架构设计。
与闭源模型的黑箱特性形成鲜明对比的是,DeepSeek 的 GitHub 仓库不仅包含模型权重文件,还详细披露了 transformer 架构的具体实现细节:
https://www.php.cn/link/75124f25b1db7620476f6d70697fec61
项目中公开的 data_curation 模块展示了从原始网页数据到高质量训练数据的完整处理流程。
这一切使得 DeepSeek 模型非常容易在本地电脑或任何主流云端进行部署。
以腾讯 HAI 为例,在腾讯 HAI 上部署并运行 DeepSeek R1 模型,整个过程不会超过 5 分钟。
腾讯 HAI,全称 Hyper Application Inventor,是一款面向 AI 和科学计算的高性能 GPU 应用服务产品,提供即插即用的强大算力和常见环境。
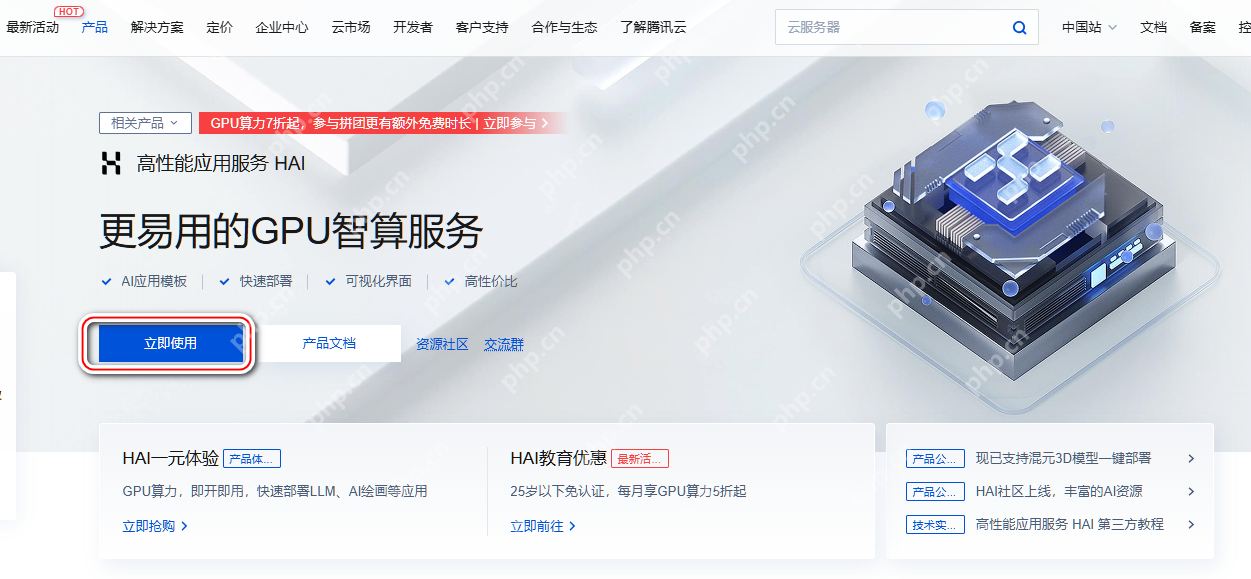
HAI 的访问入口:
https://www.php.cn/link/d06ea3741c03e92e0e5f2f4ba8c288b0
点击“立即使用”:
 新建算力资源:
新建算力资源:
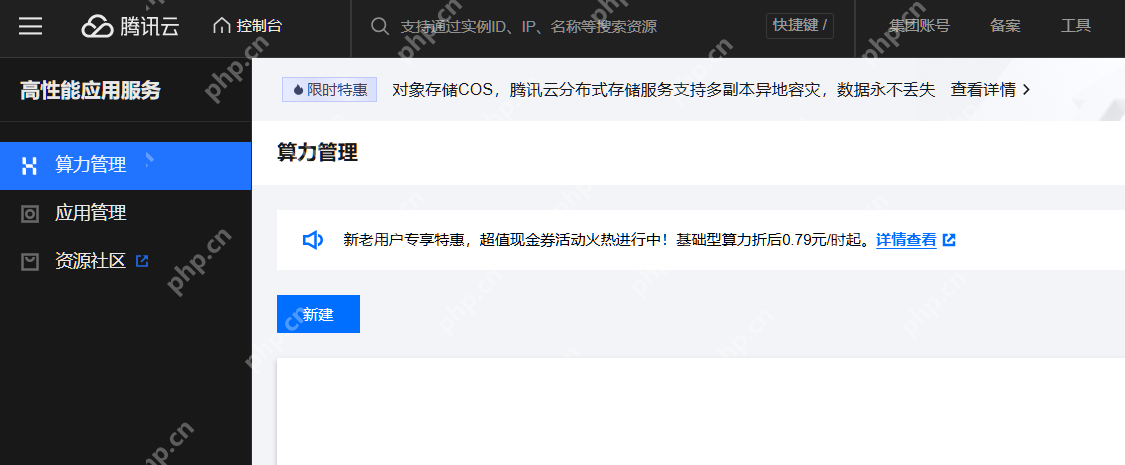 在算力资源列表中,选择“社区应用”,排名第一的就是 DeepSeek-R1:
在算力资源列表中,选择“社区应用”,排名第一的就是 DeepSeek-R1:
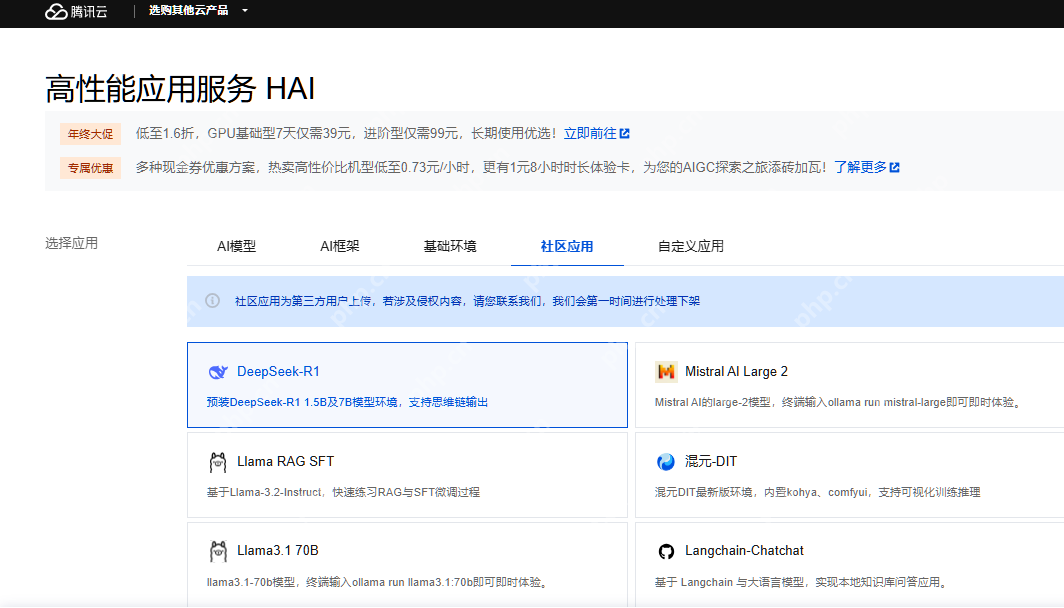 选择最基础的“GPU 基础型”算力,这种规格的算力为 8+ TFlops SP,其中 Flops 是 Floating Point Operations Per Second 的缩写,代表计算机每秒可以执行的浮点运算次数。
选择最基础的“GPU 基础型”算力,这种规格的算力为 8+ TFlops SP,其中 Flops 是 Floating Point Operations Per Second 的缩写,代表计算机每秒可以执行的浮点运算次数。
T 代表 10 的 12 次方,即一万亿,8 TFlops 即每秒 8 万亿次浮点运算,SP 即 Single Precision,单精度运算,表示计算机使用 32 位(4 字节)的浮点数进行计算。
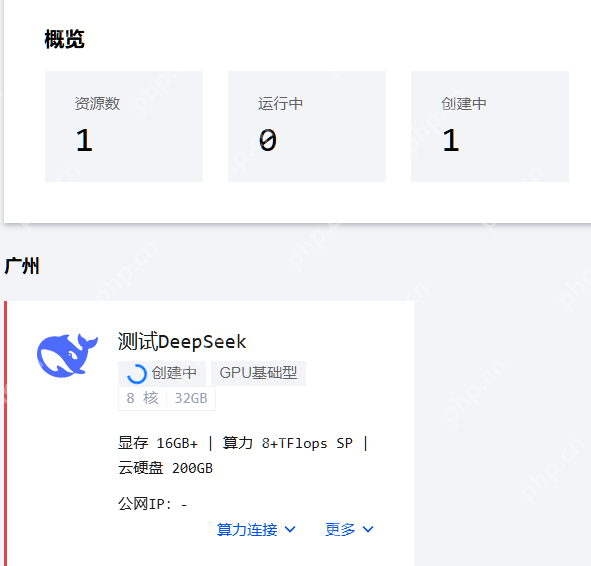 算力资源只需两三分钟即可自动创建完成。
算力资源只需两三分钟即可自动创建完成。
在创建好的实例中,预置了通过 Web 浏览器和终端命令行访问 DeepSeek R1 模型的“ChatbotUI”和“JupyterLab”。
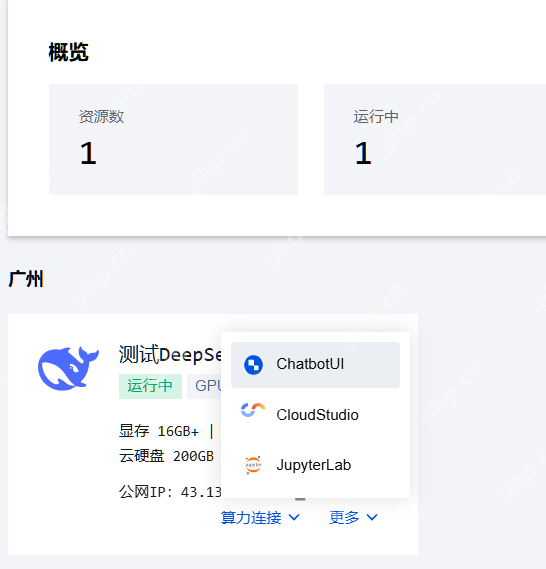 ChatbotUI,即 Chatbot Ollama,是一个开源的聊天用户界面,专门为 Ollama 模型设计,基于 chatbot-ui 项目。
ChatbotUI,即 Chatbot Ollama,是一个开源的聊天用户界面,专门为 Ollama 模型设计,基于 chatbot-ui 项目。
它旨在为用户提供一个简洁、高效的交互平台,以便更好地与 Ollama 管理的模型进行互动。
Ollama 是一个开源框架,专为在本地运行大型语言模型而设计,其主要特点是将模型权重、配置和数据捆绑到一个包中,从而优化了设置和配置细节,包括 GPU 使用情况,简化了在本地运行大型模型的过程。
腾讯 HAI 将 Ollama 的安装和配置工作完全隐藏起来,只需在上图展示的 HAI 算力资源创建页面新建算力,就能立即得到“开箱即用”的 DeepSeek R1 模型应用。
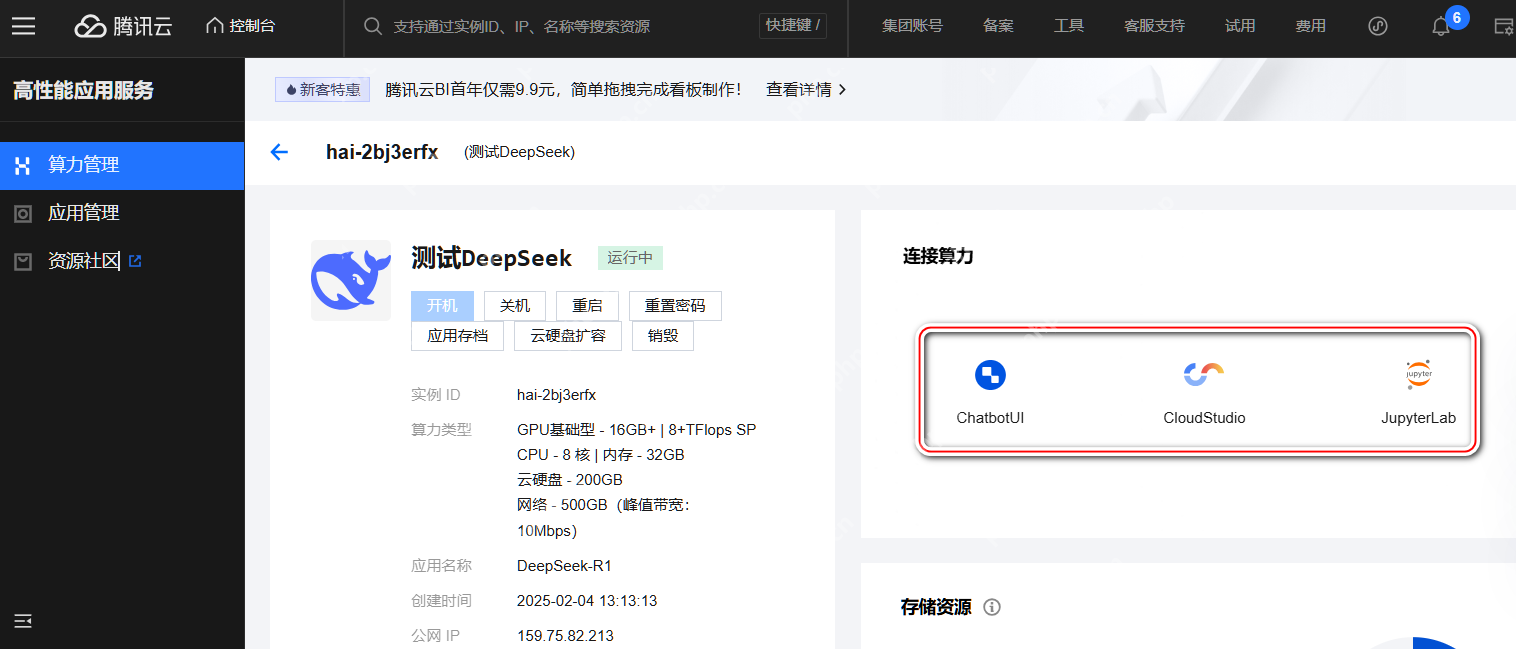 点击“ChatbotUI”,会自动打开一个浏览器窗口,我们就可以在这个窗口里与 DeepSeek 进行对话了。
点击“ChatbotUI”,会自动打开一个浏览器窗口,我们就可以在这个窗口里与 DeepSeek 进行对话了。
在 Ollama Model 下拉菜单中,可以选择预置的 1.5b 或 7b 模型。
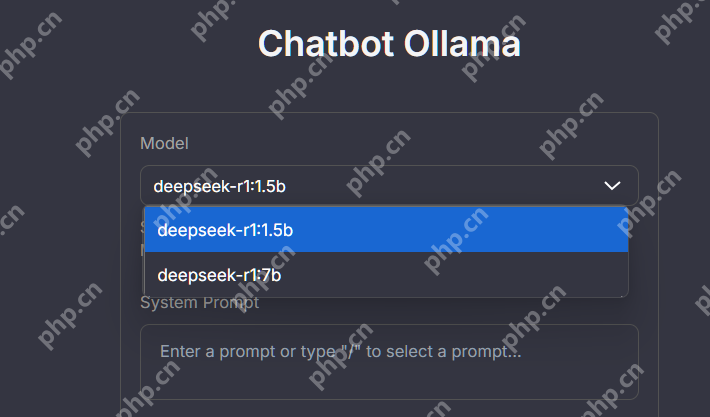 b 即 billion,1.5b 代表模型参数为 15 亿个,7b 则代表 70 亿个模型参数。
b 即 billion,1.5b 代表模型参数为 15 亿个,7b 则代表 70 亿个模型参数。
7b 模型由于拥有更多的参数,能够捕捉到更复杂的特征,因此在处理复杂任务时,通常比 1.5b 模型表现更优异。比如在需要深度理解和推理的任务中,7b 模型可以提供更准确详细的回答。
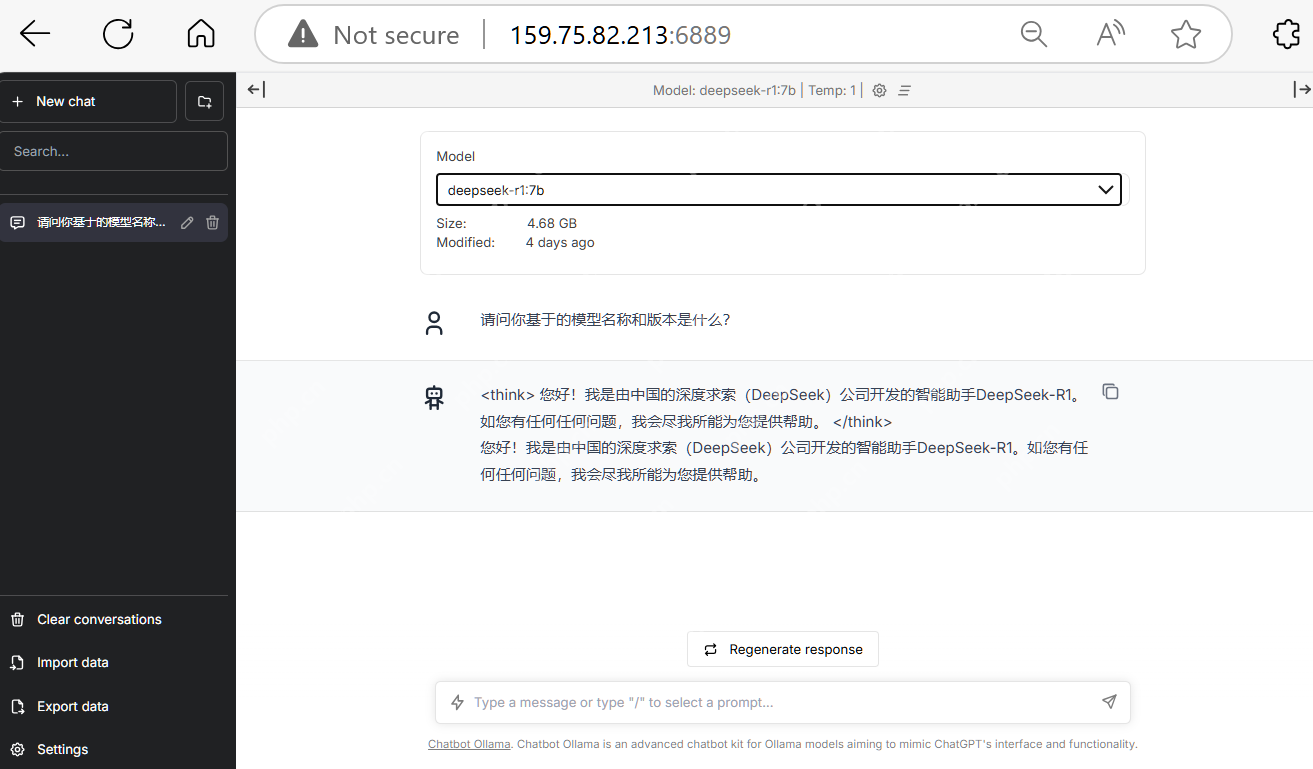
另一方面,由于参数数量的增加,7b 模型对硬件配置的要求更高,在运行时需要更多的计算资源。根据 Ollama 官方提供的信息,7b 模型的大小约为 4.68 GB,而 1.5b 模型约为 1.1 GB。
当然,因为我们使用了 PHP 中文网端的 HAI,使用这些模型不会给本地电脑浏览器端产生任何额外的负载。
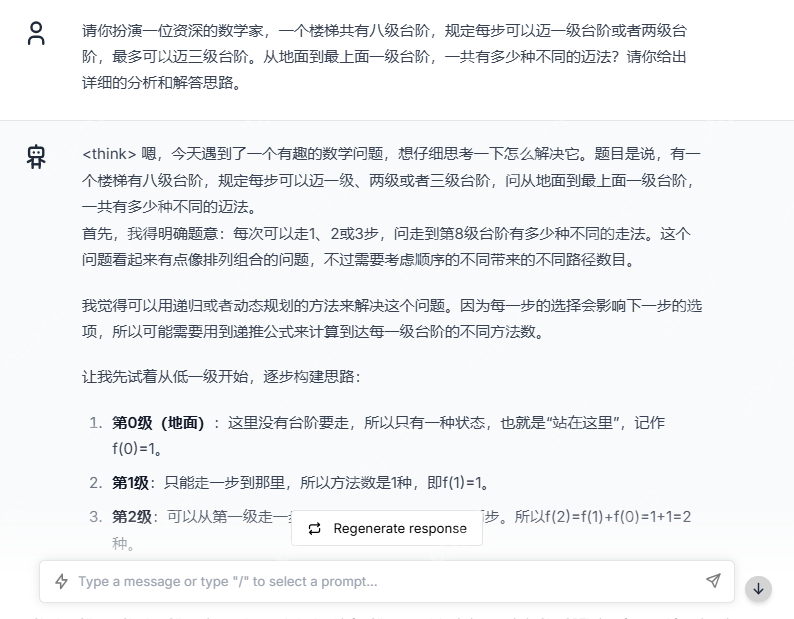
 用一些稍微复杂的题目来测试:
用一些稍微复杂的题目来测试:
DeepSeek 给出了令人满意的回答:
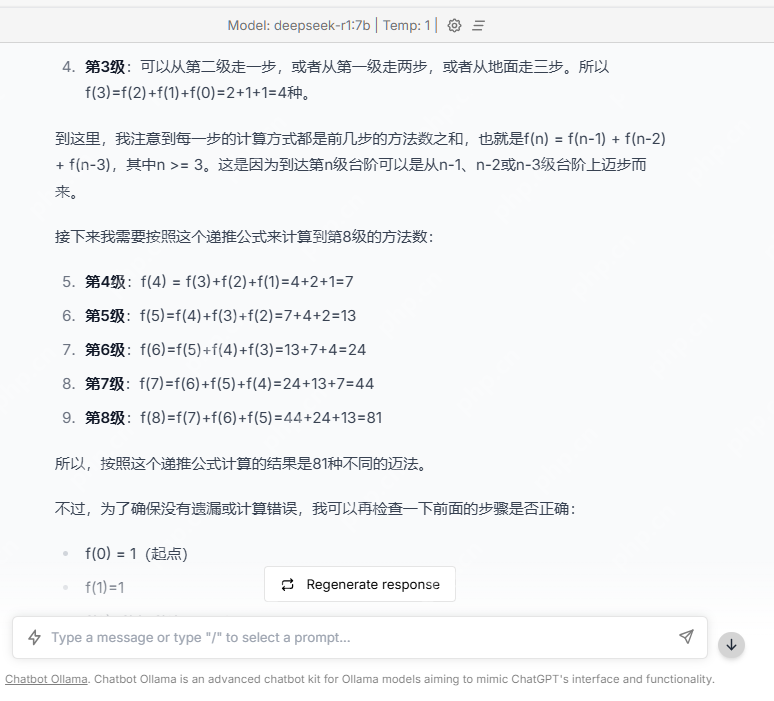 当然,腾讯 HAI 结合 DeepSeek 的本地部署场景,还有一些更高级的玩法,比如上传本地文件打造个人知识库,本公众号后续将继续介绍。
当然,腾讯 HAI 结合 DeepSeek 的本地部署场景,还有一些更高级的玩法,比如上传本地文件打造个人知识库,本公众号后续将继续介绍。
福利游戏
相关文章
更多-

- 美团外卖怎么看下单几次 掌握个人下单数据的途径
- 时间:2025-05-31
-

- 萤石云视频家庭分享怎么用 家人共享功能设置
- 时间:2025-05-31
-

- 怎么查芒果tv有没有自动续费 芒果tv自动续费状态查询方法
- 时间:2025-05-31
-

- 今日头条看新闻能赚钱吗 今日头条看新闻赚钱真相
- 时间:2025-05-31
-

- b站怎么看黑名单 黑名单管理及查看方法
- 时间:2025-05-31
-

- ios支付宝自动续费怎么关闭 iOS端支付宝自动续费关闭指南
- 时间:2025-05-31
-

- 今日头条怎么发视频 今日头条视频发布教程
- 时间:2025-05-31
-

- 起点作家助手app如何查看总稿费
- 时间:2025-05-31
精选合集
更多大家都在玩









大家都在看
更多-
- 区块链合约平台:开启全球交易新纪元
- 时间:2025-05-31
-

- 魔兽世界索罗夫宝藏获取方法
- 时间:2025-05-31
-
- Venom币起源:解决交易痛点
- 时间:2025-05-31
-

- 《金铲铲之战》三冠冕无限爆金币攻略
- 时间:2025-05-31
-

- 魔兽世界博学者的罩衫怎么获取
- 时间:2025-05-31
-

- Smittix预售筹1430万,瞄准跨境支付
- 时间:2025-05-31
-

- 鸣潮2.2幽夜幻梦任务流程
- 时间:2025-05-31
-
- 《幸福里》查看收藏记录方法
- 时间:2025-05-31