



















Llama 4 刷榜作弊引热议,20 万显卡集群就做出了个这?
时间:2025-04-23 | 作者: | 阅读:0昨天一早,meta 了放出自家用了 20 万显卡集群训练出的 llama 4 系列模型,其中包括 llama 4 scout、llama 4 maverick 和 llama 4 behemoth。消息一出,直接引爆了大模型圈。
Meta 还特意强调,这些模型都经过了大量未标注的文本、图像和视频数据的训练,视觉理解能力已经到了 Next level,有种在大模型领域一骑绝尘的既视感。

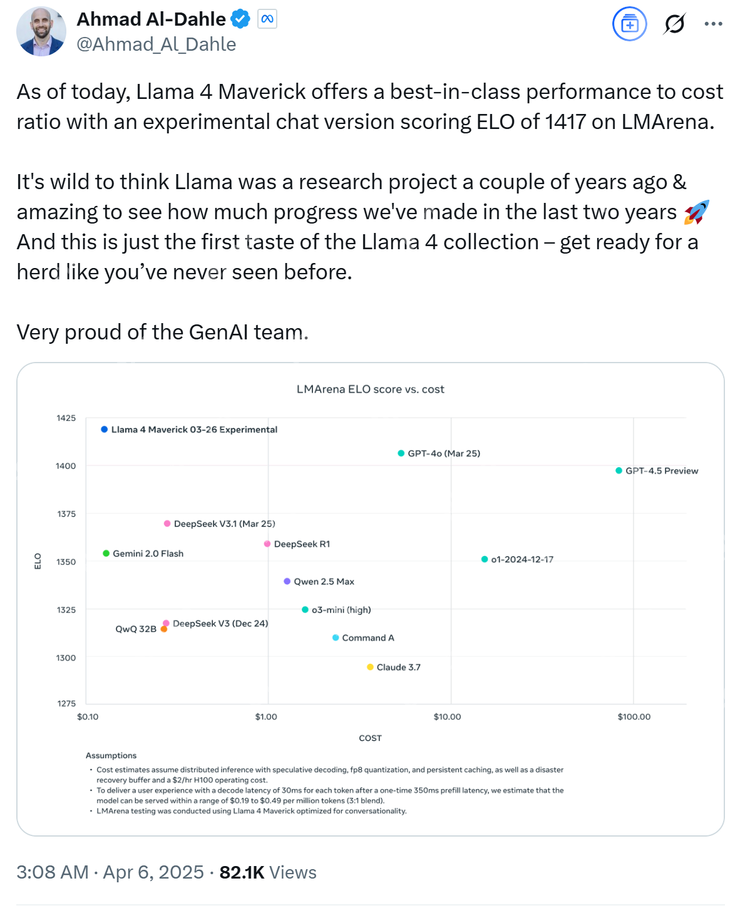
Meta GenAI 负责人 Ahmad Al-Dahle 也表示:“我们的开放系统将产出最好的小型、中型和即将出现的前沿大模型。”并附上了一张 Llama 4 的性能对比测试图。
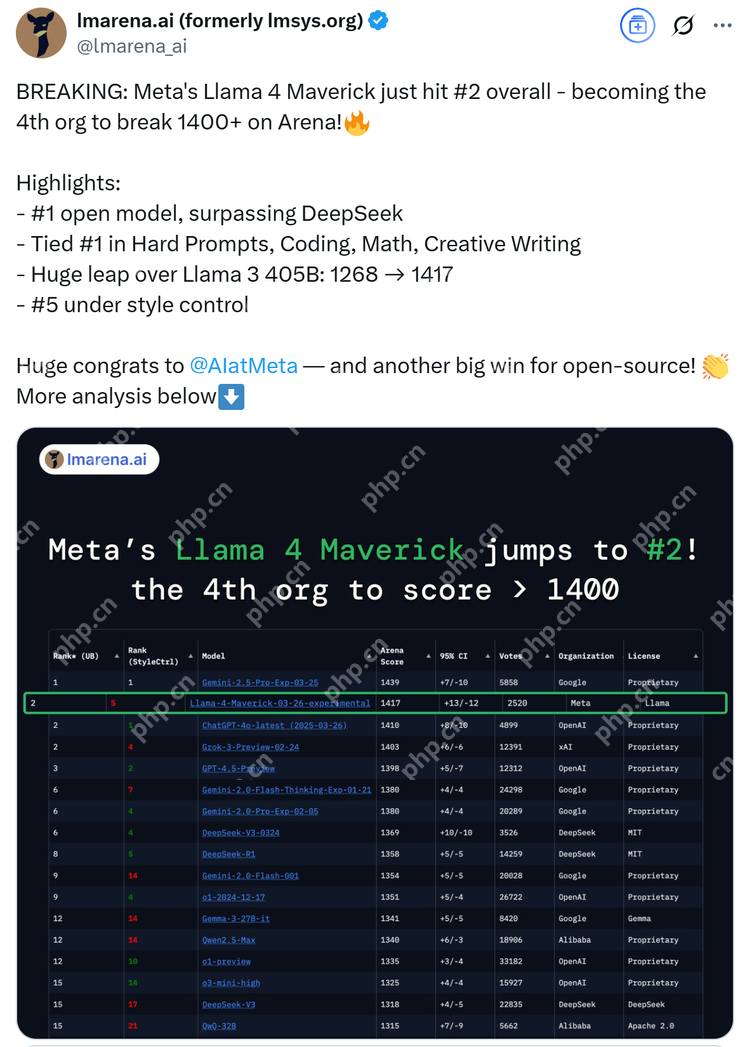
紧接着,在大模型竞技场中 Llama 4 Maverick 的排名直接跃升到第二名,成为了第 4 个突破 1400 分的大模型。在开放模型排行榜上更是超越了 DeepSeek,直接上桌坐“主座”。
“首次采用 MoE 架构”、“千万 token 上下文”...一时间 Llama 4 就被贴满了各种 Title。
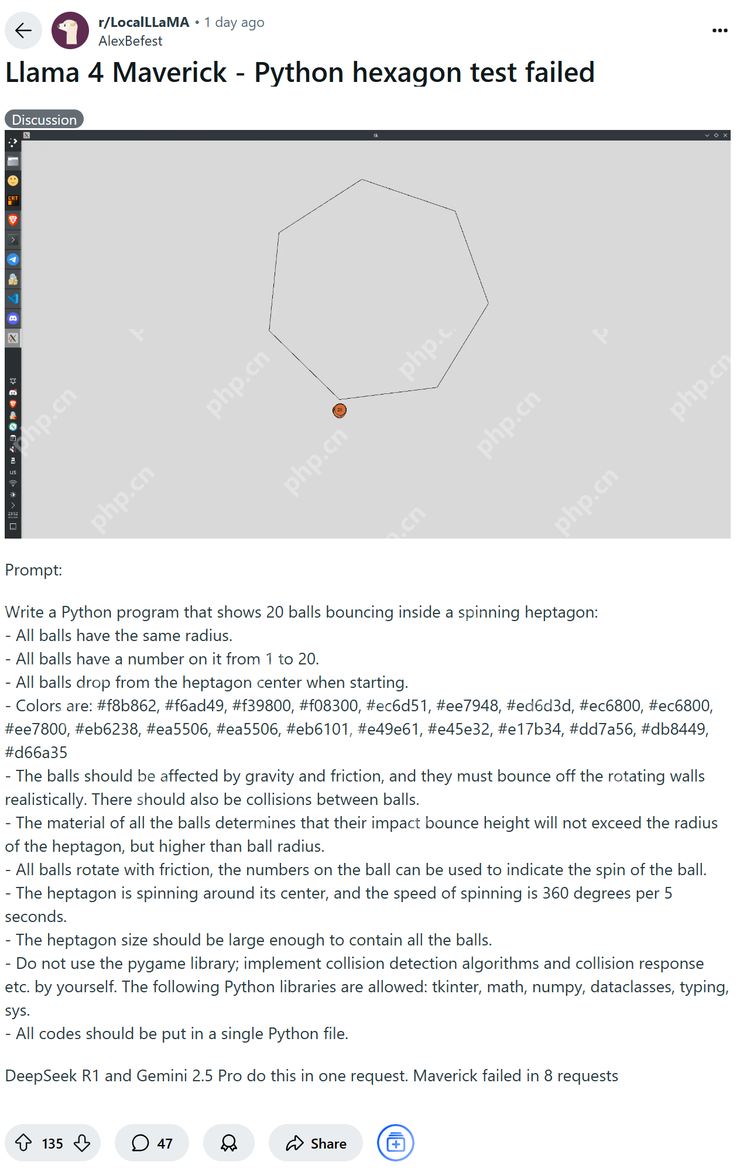
但在一片赞美和吹捧声中,很快就有心细的网友发现了不对劲。这位网友用头段时间在 ? 上很火的让模型直出几何程序的方式来测试 Llama 4,但最终的结果是在画六角形内含一个受重力影响球的集合图像时,Llama 4 试了 8 次也错了 8 次,而反观 DeepSeek R1 和 Gemini 2.5 pro 则是一次正确。
也有网友表示对 Llama 4 的表现感到非常失望。按照以往惯例,更新了版本号的模型在性能上应该有很大的突破,而 Meta 憋了这么久才舍得放出来的 Llama 4 非但没有进步,在测试中的表现还不如一些现有的大模型。

还有网友非常贴心的给出 Llama 4 系列的模型能力找了个参照物:“Llama 4 maverick 这个 402B 的大模型,大概跟 Qwen QwQ 32B 写代码水平一致,而 Llama 4 scout 则近似于 Grok2 或者 文心 4.5。”

Llama 4:超级刷榜选手
在官方给出的数据中,Llama 4 的能力妥妥碾压了一众大模型,但在网友们的实际测试中,Llama 4 却显得很拉跨,越测越觉得离谱的网友们不由得怀疑,扎克伯格是不是给自家模型偷偷刷榜了?
经过网友们的多方证实,最后发现,嘿!还真是刷的。
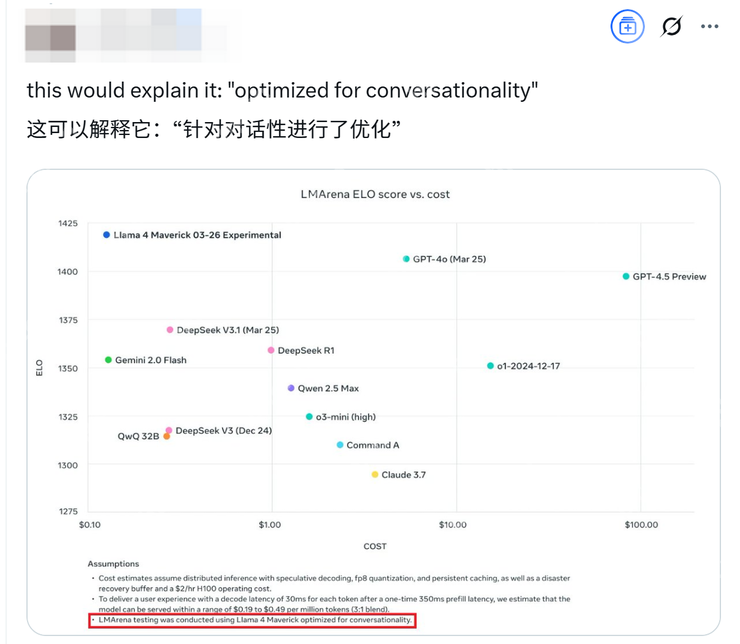
其实如果认真看 Ahmad Al-Dahle 发布的 Llama 性能对比测试图最下面一行的小字,你就会发现上面写着“Llama 4 Maverick 针对对话进行了优化”,而 Meta 其实早就给自己留了个“图片仅供参考,一切以实物为准”的心眼。
除了破解 Meta 官方的字谜游戏外,网友们也带着 Llama 4 进出于各大测试榜单中。
他们先是把 Llama 4 拉到了著名的 code 测试榜单 Aider ployglot 中,最终的得分比 qwen-32B还低。
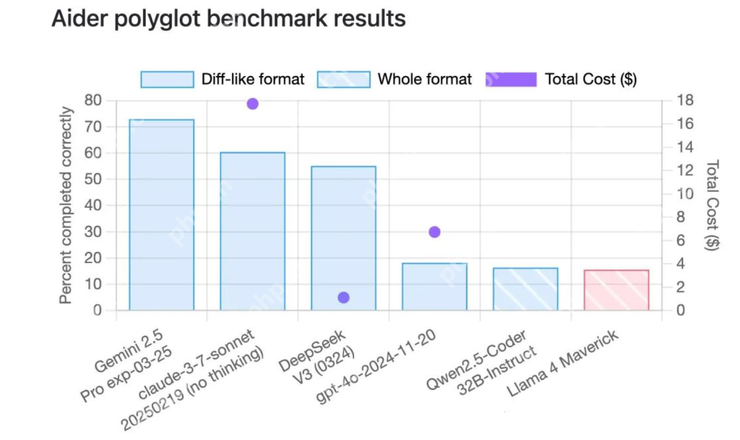
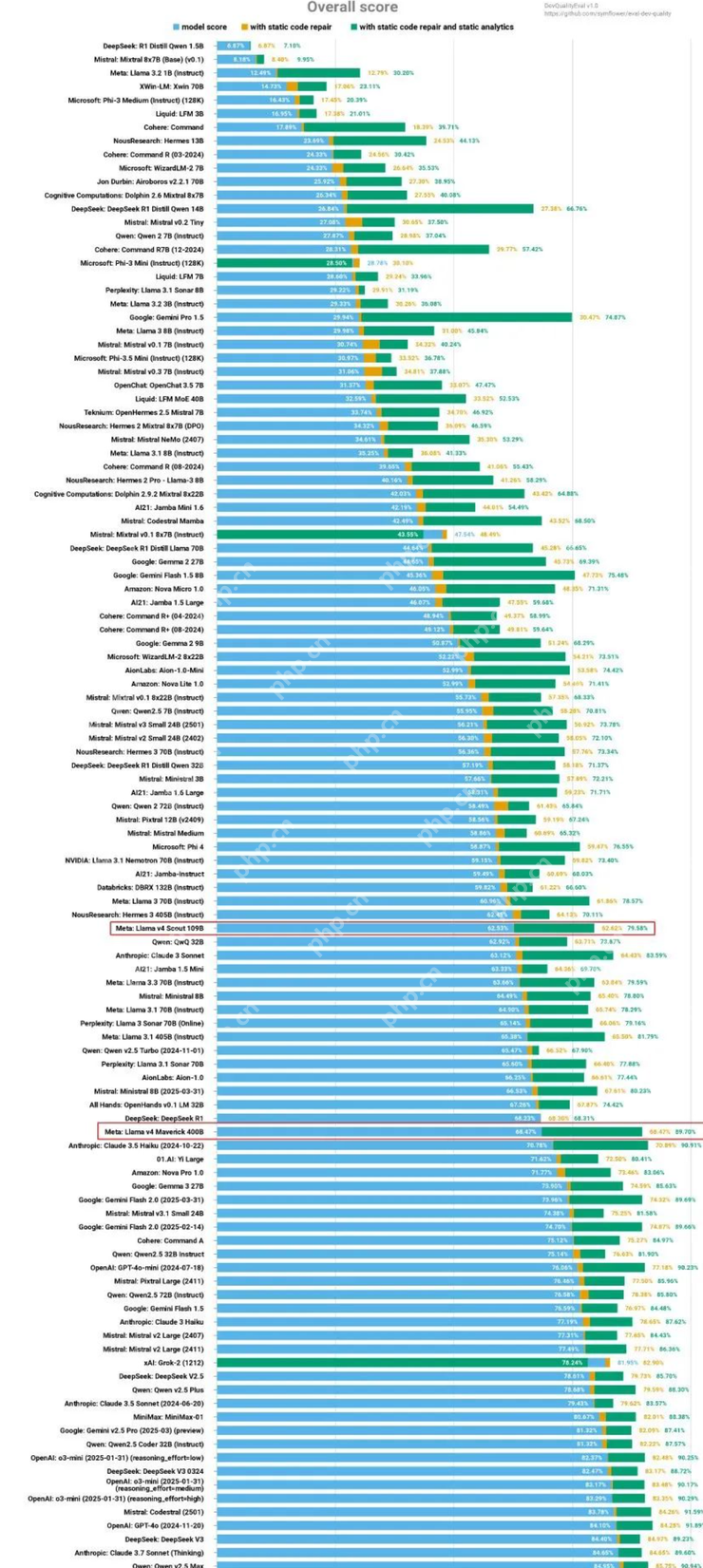
在另一个代码评测榜单中,Llama 4 的成绩也只能排在中间位置。
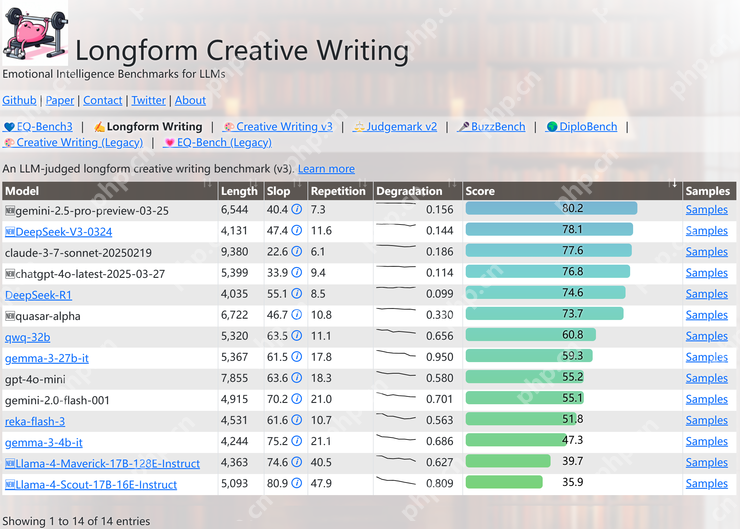
除此之外,网友们发现在 EQBench 测评基准的长文章写作榜上,Llama 4 系列也是直接垫底。
而即使是最基础的翻译任务,网友们也表示 Llama 4 的表现也是比 3.3 的 70b 还要差得多,甚至还不如 Gemma 3 的 27B。
混乱的 Meta
正在网友们风风火火测评 Llama 4 的真实成绩时,一则发布在海外的求职平台一亩三分地上的内容更是直接给Llama 4 的作弊传闻填了一把柴。
文中提到 Llama 4 的训练存在严重问题,并且内部模型的表现仍然未能达到开源 SOTA,甚至与之相差甚远,而 Llama 4 的高分也确实是领导层为了能够在各项指标上交差所做出的“努力”。而这个则消息的爆料者,很可能来自 Meta 公司内部。

除此之外也有其他的 AI 从业者在线吐槽,表示“我们都被耍了,Llama 4 不过是一个早早被设计好的实验版本。”
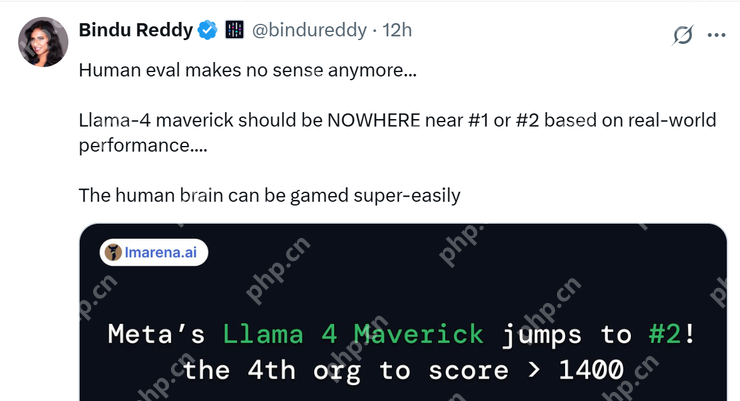
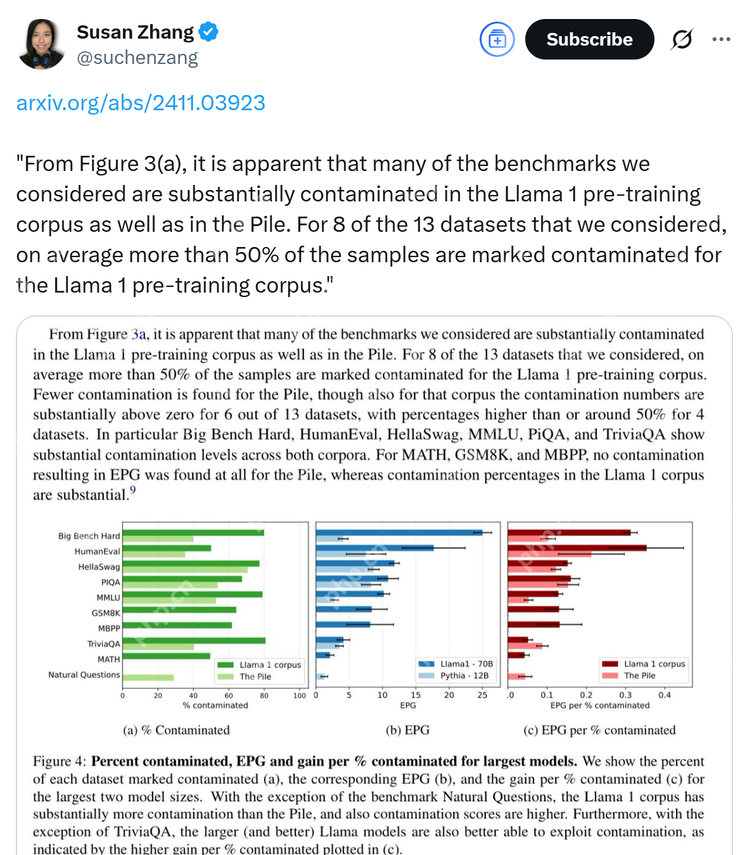
还有前 Meta 员工站出来指出公司在产品研发方面存在巨大漏洞,并表示 Llama 系列模型的信息泄露问题其实从 Llama 1 就已经存在了。
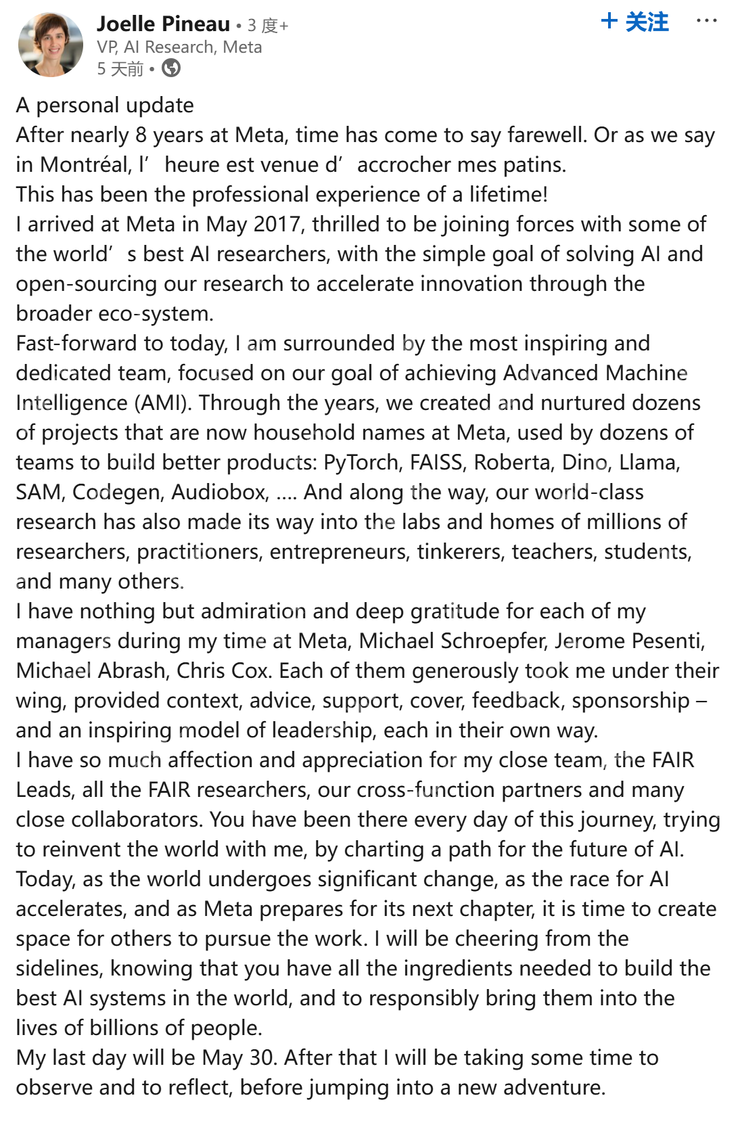
而在 Llama 4 发布的几天前,Meta AI 研究副总裁 Joelle Pineau 就在 Linkedin 发文称自己已经申请将在 5 月份离职,不由得让人们将这件事与 Llama 4 作弊刷榜的事情联系到一起。
不少人疑惑,为什么一向崇尚“大力出奇迹”的 Meta 这次的翻车力度这么大,明明有钱、有卡、有数据,但模型创新能力依旧不足,还要靠作弊刷榜来找存在感?
一个坊间流传的观点是,Meta内部研究人员压力过大,因为他们需要做出成果,给公司一个好的交代,因此会求稳,更加偏向于更能做出成果的事情,而真正重要的内容,比如基础设施的迭代、新算法的实验,这些需要大量时间去做出成果的内容,却往往没有人愿意去做。
这也导致了 Meta 很难在大模型市场上继续做出向 DeepSeek R1 这样轰动整个 AI 领域的东西,而还没有发布的超大杯 2T 参数模型也应证着这个观点:Meta 其实还没有更好的想法。
反观以研究为导向的 DeepSeek,其实一直在探索新的架构。DeepSeek 团队先是提出了强化学习里的神奇算法 GRPO,紧接着在 DeepSeek v2 时提出的 MLA 原理直接沿用到了 DeepSeek V3 和 DeepSeek R1 版本上,后来发布的全新注意力架构 NSA 更是实现了超高速长上下文训练与推理。
回到 Llama 4 这边,根据AI科技评论的了解,对大模型架构有研究的专业人士认为,Llama 4 非常缺乏技术创新,比如说,在后训练阶段还在死守DPO。而此前的一系列理论和实验都表明 DPO 的泛化能力,“比PPO差得远”。PPO在实际使用中需要调的细节很多,不易上手。在DeepSeek提出GRPO以后,越来越多的研究者开始使用GRPO及其改版。 Meta 还继续坚持用着 DPO 而不选择创新,这么来看 Llama 4 做成如此也属于意料之中。
常人没法用,专家用不着
而最让人失望的是,Llama 4 系列的模型都无法放入家用电脑,并且 Llama 4 除了一直在宣传的 10M 上下窗口外,貌似已经没有任何优势,而这一点对于大多数人来说其实并不是必需的内容。
除此之外,GPT 4o, Gemini 2.5 Pro 这些拥有生图能力的模型型号已经正式推出,而 Grok3、Gemini 2 Flash 等多模态模型也已经开始广泛开放,这也意味着更多的人没有再用 Llama 4 的理由,或者说,Llama 4 本身没有太强的市场竞争力。

反观这次 Llama 4 的翻车事件,不难看出其实 Llama 4 系列模型很可能是 Meta 在追赶大模型潮流的战略布局中的一枚重要棋子,但却因为太过于“急功近利”而选择作弊,导致直接失去了社区的支持,进而失去了自身的竞争优势。
并且 Llama 2、Llama 3 的时代已经过去,选择 Llama 作为基座的开源模型只会越来越少,PHP中文网(公众号:PHP中文网)认为对于 Meta 来说,与其选择作弊刷榜博眼球,不如想想如何创新,如何提高社区适用度,能不能追上最前端的技术暂且放一边,最重要的是先把口碑先赚回来。

福利游戏
相关文章
更多-

- 穿越火线空白名字代码复制2023大全
- 时间:2025-04-23
-

- 刺客信条影弦之丞恋爱剧情达成条件
- 时间:2025-04-23
-

- 大航海时代传说主线航海士选什么-大航海时代传说主线航海士选择攻略
- 时间:2025-04-23
-

- 王者荣耀五五开黑节何时开启-王者荣耀五五开黑节开启时间
- 时间:2025-04-23
-

- 桃源记2石灰石获取方法攻略分享
- 时间:2025-04-23
-

- 阴阳师初音未来霜冬千曲特效如何展示-阴阳师初音未来霜冬千曲特效展示方法
- 时间:2025-04-23
-

- 怎样使用即梦ai制作对口型视频
- 时间:2025-04-23
-

- 2025上海车展今日开幕 近千家企业参展 超百款新车迎首发
- 时间:2025-04-23
精选合集
更多大家都在玩












大家都在看
更多-

- 天地劫幽城再临新手开服第一天怎么玩
- 时间:2025-04-23
-

- 巴基斯坦航天员选拔工作正在进行:以专家身份参与联合飞行
- 时间:2025-04-23
-

- 天地劫幽城再临资源有哪些
- 时间:2025-04-23
-
- 两年巨变!上海车展韩法系“消失” 比亚迪成车圈“顶流” 小米首次亮相
- 时间:2025-04-23
-

- AVAX是不是崩盘了
- 时间:2025-04-23
-

- 比亚迪全新超跑腾势Z亮相上海车展:用上云辇-M专属车身控制
- 时间:2025-04-23
-
- 小米辟谣小米YU7推迟发布:6-7月上市不变
- 时间:2025-04-23
-

- 天地劫幽城再临海捕令怎么解锁
- 时间:2025-04-23