



















最新!告别DeepSeek卡顿,直接提速11倍多
时间:2025-04-23 | 作者: | 阅读:0长文本处理的新突破:deepseek 的 nsa 原生稀疏注意力机制
最近,DeepSeek 在提升大语言模型处理长文本的能力上取得了重大进展。
传统模型在处理长篇小说或庞大代码库时,常因计算量巨大而出现卡顿。
DeepSeek 推出的 NSA(原生稀疏注意力机制)就像为模型配备了“智能滤网”,不仅能捕捉到关键信息,还大大减轻了计算负担,使速度提升了 11.6 倍。
一、问题:为何长文本处理如此费力?传统的注意力机制(Full Attention)要求模型在处理每个词时,都要与之前的所有词进行关联计算。
想象一下,如果一篇文章有 6 万个词,模型需要进行近 36 亿次计算!这种“全员参与”的模式虽然全面,但效率极低。特别是在实际应用中,解码一段长文本可能有 70%的时间用于注意力计算(图 1 右)。
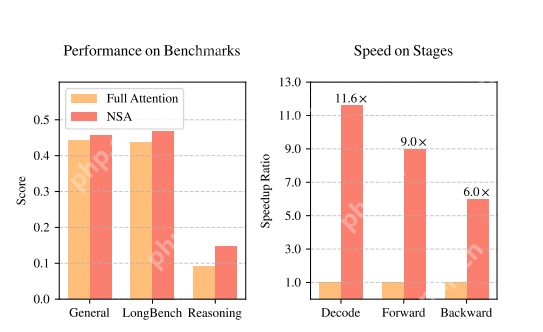 ▲ 图 1 | 左:NSA 在各项任务中的表现不逊于全注意力模型;右:处理 6.4 万长度文本时,NSA 解码速度提升 11.6 倍。▲ 图 1 | 左:NSA 在各项任务中的表现不逊于全注意力模型;右:处理 6.4 万长度文本时,NSA 解码速度提升 11.6 倍。
▲ 图 1 | 左:NSA 在各项任务中的表现不逊于全注意力模型;右:处理 6.4 万长度文本时,NSA 解码速度提升 11.6 倍。▲ 图 1 | 左:NSA 在各项任务中的表现不逊于全注意力模型;右:处理 6.4 万长度文本时,NSA 解码速度提升 11.6 倍。
二、解决方案:模仿人类阅读的“抓重点”方式人类在阅读长文时会自然跳过不相关的段落,只关注关键部分。
NSA 模仿这一机制,设计了三层注意力筛选网络(图 2):
- 压缩层:将每 32 个词压缩成一个“段落梗概”2. 精选层:动态筛选出 64 个最重要的词块3. 滑动窗:始终关注最近的 512 个词,以防止漏掉局部信息
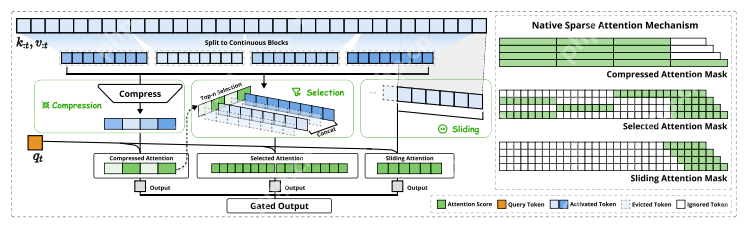 ▲ 图 2 | 三种注意力模式分工合作,绿色区域代表实际计算部分▲ 图 2 | 三种注意力模式分工合作,绿色区域代表实际计算部分
▲ 图 2 | 三种注意力模式分工合作,绿色区域代表实际计算部分▲ 图 2 | 三种注意力模式分工合作,绿色区域代表实际计算部分
这种设计使得计算量大幅减少——原本需要处理 6 万个词,现在只需关注约 5 千个关键点,同时通过硬件级优化(如连续内存读取、Tensor Core 加速),让理论上的速度提升得以实现。
三、实际表现:速度与智能兼具的“双料冠军”DeepSeek 在 270 亿参数模型上进行了全面测试:
? 常规任务:在数学推理(GSM8K)、代码生成(HumanEval)等 9 项测试中,NSA 在 7 项中领先。? 长文本检索:在 6.4 万字的“大海捞针”测试中,NSA 实现了 100% 的准确率(图 5) ▲ 图 5 | 64k 上下文长度的上下文位置上的“大海捞针”检索准确率▲ 图 5 | 64k 上下文长度的上下文位置上的“大海捞针”检索准确率
▲ 图 5 | 64k 上下文长度的上下文位置上的“大海捞针”检索准确率▲ 图 5 | 64k 上下文长度的上下文位置上的“大海捞针”检索准确率
? 推理能力:经过专项训练后,NSA 在解决美国数学竞赛题的正确率上比传统模型高出 60%更重要的是速度优势:
? 训练提速:处理 6.4 万长度文本时,前向计算提速 9 倍,反向传播提速 6 倍? 解码飞跃:生成相同内容时,内存读取量减少 90%,实际响应速度提升 11.6 倍四、创新突破:从“事后补救”到“原生设计”现有方案多在模型训练完成后才启用稀疏计算,相当于给已建好的房子拆墙开窗。
而 NSA 从一开始就让模型学习如何高效分配注意力:
? 硬件对齐:像拼乐高一样设计计算模块,完美匹配 GPU 的 Tensor Core 特性? 动态学习:每个词块的筛选标准由模型自主调整,确保重要信息不会遗漏? 端到端训练:支持从预训练到微调的全流程,避免后期的“水土不服”五、应用前景:这项技术能做什么?试想以下场景:
? 程序员上传整个项目代码,AI 能在秒级内理解架构并生成新功能? 上传上百页的 PDF,AI 可以快速提取关键信息? 游戏 NPC 能够记住玩家上千条对话历史,并做出连贯反应NSA 已在这些方向上初步验证成功(表 2)
 ▲ 表 2 | NSA 与 LongBench 上的基线之间的性能比较▲ 表 2 | NSA 与 LongBench 上的基线之间的性能比较
▲ 表 2 | NSA 与 LongBench 上的基线之间的性能比较▲ 表 2 | NSA 与 LongBench 上的基线之间的性能比较
未来,NSA 可能成为处理长文本的“标准配置”技术,让大模型真正突破上下文长度的限制。
福利游戏
相关文章
更多-

- 快手极速版的扫一扫在哪里 扫一扫位置揭秘
- 时间:2025-06-02
-

- 抖音极速版怎么设置自动刷视频 抖音极速版自动刷视频设置方法
- 时间:2025-06-02
-
- 怎么用高德地图步行导航 高德地图步行导航使用教程分享
- 时间:2025-06-02
-

- 天眼怎么查资质 企业资质证书查询方法大全
- 时间:2025-06-02
-

- 迅雷网盘怎么解压 压缩包解压详细步骤教学
- 时间:2025-06-02
-

- 手机1688成品网站入口 成品1688网站首页进入
- 时间:2025-06-02
-

- 萤石云分享后怎么查看 接收查看分享内容的方法
- 时间:2025-06-02
-

- 成品ppt网站大片免费观看 100成品免费ppt网站入口
- 时间:2025-06-02
精选合集
更多大家都在玩








大家都在看
更多-

- 《有书》设置定时方法
- 时间:2025-06-02
-

- 燕云十六声清河第一大善人怎么达成
- 时间:2025-06-02
-
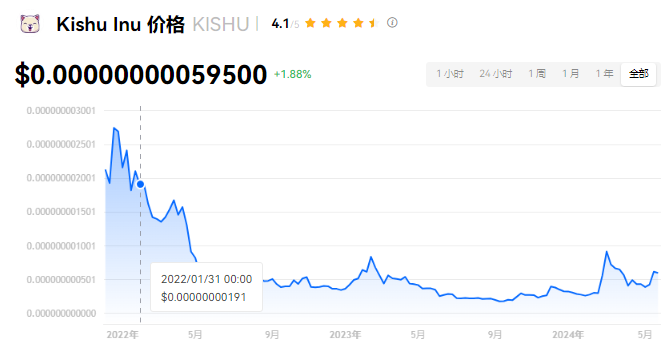
- KISHU币投资价值:长期持有分析
- 时间:2025-06-02
-

- 燕云十六声江无浪徽章在哪买
- 时间:2025-06-02
-

- 比特币交易所app推荐:十大平台全解析
- 时间:2025-06-02
-

- 《绝区零》扳机突破材料介绍
- 时间:2025-06-02
-
- 燕云十六声三月折音券怎么获得
- 时间:2025-06-02
-
- 十公分等于多少厘米 十公分厘米换算公式
- 时间:2025-06-02