



















SmolVLA— Hugging Face开源的轻量级机器人模型
时间:2025-06-13 | 作者: | 阅读:0smolvla 是 hugging face 推出的一款轻量级视觉-语言-行动(vla)模型,专为资源受限的机器人平台设计。该模型参数规模约为4.5亿,具备较高的计算效率,可在cpu上运行,使用单个消费级gpu即可完成训练,并且能够部署在macbook等设备上。smolvla 完全依赖于开源数据集进行训练,其训练数据集标签为“lerobot”。
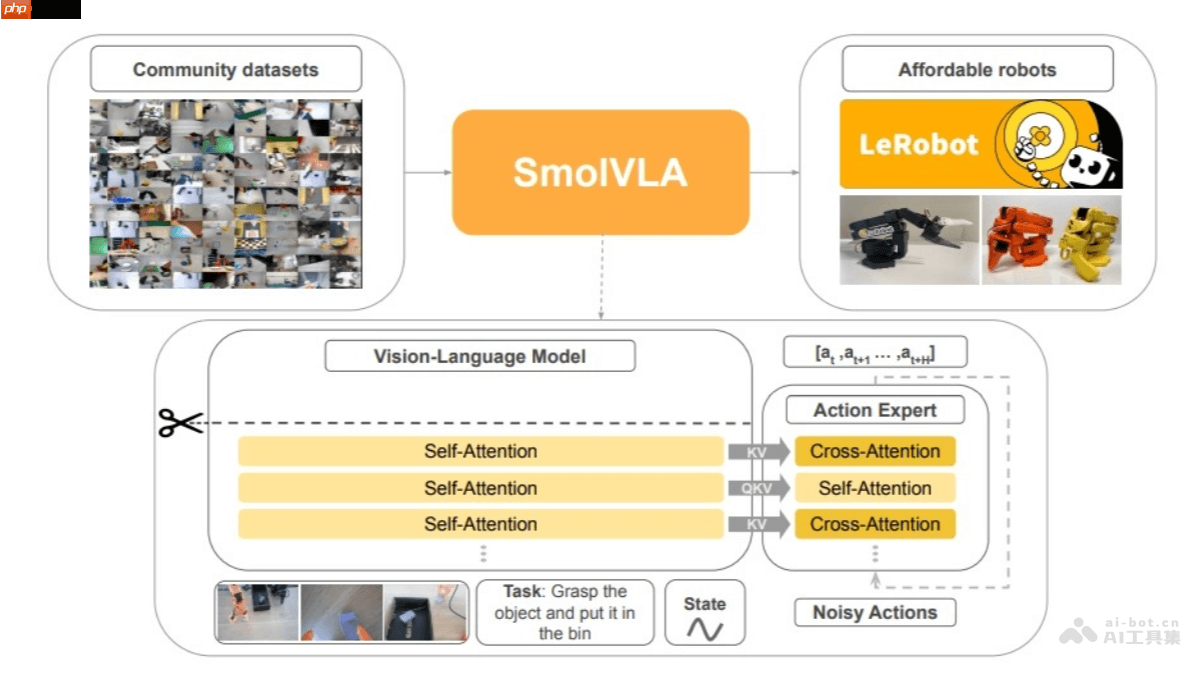
- 多模态输入处理能力:SmolVLA 支持多种输入方式,包括图像、语言指令和机器人本体状态信息。图像通过视觉编码器提取特征,语言指令则被转换为标记输入解码器,机器人的传感运动状态通过线性层映射为与语言标记维度一致的表示。
- 动作序列生成机制:该模型内置一个动作专家模块,是一个轻量级 Transformer 结构,基于视觉-语言模型(VLM)输出的信息生成机器人未来的动作序列块。采用流匹配方法进行训练,通过引导噪声样本回归真实数据分布来实现高精度动作预测。
- 高效推理与异步执行架构:SmolVLA 引入了异步推理机制,将动作执行与感知和预测过程分离,从而提升响应速度和任务处理效率,使机器人在动态环境中具备更强的适应能力。
SmolVLA的技术细节
- 视觉-语言模型(VLM)结构:SmolVLA 基于 SmolVLM2 构建核心视觉-语言处理模块,经过优化后可支持多图输入。其结构包含 SigLIP 视觉编码器和 SmolLM2 语言解码器。图像特征由视觉编码器提取,语言指令经分词处理后送入解码器,而机器人状态信息则通过线性层转化为统一维度标记。解码器整合这些信息后,将结果传递给动作专家模块。
- 动作专家模块:该模块是一个小型 Transformer 网络(约1亿参数),负责根据 VLM 的输出生成机器人动作序列。同样采用流匹配方式进行训练,以实现精准的动作控制。
- 视觉 Token 数量优化:为了提升计算效率,SmolVLA 将每帧图像的视觉 Token 数量限制为64,显著降低了计算开销。
- 层跳跃策略:SmolVLA 在推理过程中跳过了 VLM 中的一半网络层,使得计算成本降低一半,同时保持了良好的性能表现。
- 交错注意力机制:不同于传统 VLA 架构,SmolVLA 在注意力机制中交替使用交叉注意力(CA)和自注意力(SA)层,提升了多模态信息融合效率并加快推理速度。
- 异步推理机制:SmolVLA 实现了异步推理流程,使得机器人可以一边执行当前动作,一边开始处理新的观察信息并预测下一步动作,从而消除延迟,提高控制频率。
SmolVLA的项目资源
- HuggingFace模型页面:https://www.php.cn/link/e4b868e56d6409924b97560bf2758cd2
- arXiv技术文档:https://www.php.cn/link/1e632c3db5602c1e2639897989497ca5
SmolVLA的实际应用
- 物体抓取与定位操作:SmolVLA 能够驱动机械臂完成复杂的抓取和放置任务。例如,在制造业场景中,机器人可根据图像和语言指令准确识别零件并完成定位操作。
- 家庭服务任务:SmolVLA 可用于开发家用服务机器人,协助完成日常家务。例如,根据语音指令识别房间内的物品并进行整理或清洁。
- 仓储物流搬运:在仓库环境中,SmolVLA 可指导机器人完成货物搬运任务。机器人可通过视觉识别货物位置和形态,结合语言指令生成最优搬运路径和动作序列,提升作业效率。
- 教育科研用途:SmolVLA 还可用于机器人教学与研究,帮助学生和研究人员深入理解智能机器人系统的工作原理与开发流程。
福利游戏
相关文章
更多-
- 诡道修真记太初地境怎么过-诡道修真记太初地境通关介绍
- 时间:2025-06-13
-

- 原神5.7上半角色抽哪个好 丝柯克和申鹤抽取建议
- 时间:2025-06-13
-

- 原神多谢惠顾成就怎么完成-多谢惠顾成就完成攻略
- 时间:2025-06-13
-
- 龙息神寂S2燃烧流怎么玩 燃烧流阵容搭配
- 时间:2025-06-13
-

- 小米YU7已进入全国317家门店 7月上市 预计售25万+
- 时间:2025-06-13
-

- 日月光CEO吴田玉当选SEMI主席
- 时间:2025-06-13
-

- 微容科技受邀出席TrendForce高层论坛,共探AI算力时代技术革新与产业机遇
- 时间:2025-06-13
-
- 浪漫餐厅兑换码5.30-浪漫餐厅5月30日兑换码分享
- 时间:2025-06-13
大家都在玩












大家都在看
更多-

- 区块链虚拟货币全球交易平台top10推荐
- 时间:2025-06-13
-
- 以太坊挖矿视频:探秘未来石头的年份
- 时间:2025-06-13
-

- 卢伟冰:REDMI K Pad对标iPad mini!做4K以内体验最豪华的小平板
- 时间:2025-06-13
-

- 雷克萨斯LX 700h同款3.5T V6混动下放!丰田兰德酷路泽HEV官图发布
- 时间:2025-06-13
-

- 通车进入倒计时!在建世界最高桥成功拆除猫道
- 时间:2025-06-13
-

- 2025币圈十大DAI交易所app排行榜
- 时间:2025-06-13
-

- 25.68万元!创维新增HT-i高原版车型:搭载1.5T插混动力
- 时间:2025-06-13
-

- 我国自研水陆两栖大飞机!AG600“鲲龙”完成高高原测试飞行
- 时间:2025-06-13