



















在Golang项目中使用vLLM 实现高并发LLM推理指南
时间:2025-06-28 | 作者: | 阅读:0在golang项目中利用vllm实现高并发llm推理的核心在于构建高效的并发模型并优化数据传输和资源管理。1. 选择合适的并发模型,如worker pool处理独立请求、fan-out/fan-in并行处理子任务、基于context的并发控制管理生命周期和超时;2. 优化数据传输,使用grpc提升序列化效率、批量请求减少网络开销、流式api支持实时反馈;3. 强化资源管理,通过连接池减少连接开销、缓存降低重复推理、监控保障资源合理分配;4. 完善错误处理机制,包括重试应对临时错误、熔断防止雪崩效应、日志与监控辅助排查问题与健康检查。

在Golang项目中利用vLLM实现高并发LLM推理,核心在于构建高效的并发模型,并优化数据传输和资源管理,以充分利用vLLM的推理能力。

解决方案

选择合适的并发模型: Golang的并发模型基于goroutine和channel。可以选择以下几种并发模式:
立即学习“go语言免费学习笔记(深入)”;
Worker Pool: 创建一个goroutine池,用于处理并发的推理请求。每个worker从channel接收请求,调用vLLM进行推理,并将结果返回。

Fan-out/Fan-in: 将一个推理请求拆分成多个子任务,每个子任务由一个goroutine处理,最后将所有子任务的结果合并。适用于可以并行处理的复杂推理任务。
基于Context的并发控制: 使用context.Context控制goroutine的生命周期和超时,防止goroutine泄漏。
优化数据传输: vLLM通常通过gRPC或REST API提供服务。
使用gRPC: gRPC基于Protocol Buffers,可以实现高效的数据序列化和反序列化。Golang对gRPC的支持良好,可以方便地生成gRPC客户端代码。
批量请求: 将多个推理请求打包成一个批量请求,可以减少网络延迟和服务器开销。vLLM通常支持批量推理。
使用流式API: 对于长文本或需要实时反馈的推理任务,可以使用流式API。Golang的gRPC客户端支持流式API。
资源管理: LLM推理需要大量的计算资源,包括CPU、GPU和内存。
连接池: 维护一个到vLLM服务器的连接池,避免频繁地创建和销毁连接。可以使用第三方库,如go-sql-driver/mysql中的连接池实现。
缓存: 对于频繁请求的相同输入,可以使用缓存来减少推理次数。可以使用sync.Map或第三方缓存库,如ristretto。
监控: 监控CPU、GPU和内存的使用情况,及时调整资源分配。可以使用go-metrics或prometheus等监控工具。
错误处理: 完善的错误处理机制可以提高系统的稳定性和可靠性。
重试机制: 对于 transient 错误,如网络超时或服务器繁忙,可以进行重试。可以使用github.com/cenkalti/backoff等库实现指数退避重试。
熔断机制: 当vLLM服务器出现故障时,可以熔断请求,防止雪崩效应。可以使用github.com/afex/hystrix-go等库实现熔断。
日志: 记录详细的日志,方便排查问题。可以使用logrus或zap等日志库。
代码示例 (Worker Pool + gRPC)
package mainimport ( ”context“ ”fmt“ ”log“ ”sync“ ”time“ ”google.golang.org/grpc“ ”google.golang.org/grpc/credentials/insecure“ pb ”your_vllm_protobuf_package“ // 替换为你的vLLM protobuf包)const ( address = ”localhost:50051“ // 替换为你的vLLM服务器地址 numWorkers = 10 // worker数量 requestQueueSize = 100 // 请求队列大小)type InferenceRequest struct { Prompt string Response chan string}func main() { // 1. 连接到gRPC服务器 conn, err := grpc.Dial(address, grpc.WithTransportCredentials(insecure.NewCredentials())) if err != nil { log.Fatalf(”did not connect: %v“, err) } defer conn.Close() client := pb.NewVLLMServiceClient(conn) // 2. 创建请求队列 requestQueue := make(chan InferenceRequest, requestQueueSize) // 3. 启动worker pool var wg sync.WaitGroup for i := 0; i < numWorkers; i++ { wg.Add(1) go worker(client, requestQueue, &wg) } // 4. 模拟发送推理请求 go func() { for i := 0; i < 20; i++ { prompt := fmt.Sprintf(”Translate to French: Hello, world! (%d)“, i) responseChan := make(chan string, 1) // Buffered channel to prevent blocking requestQueue <- InferenceRequest{Prompt: prompt, Response: responseChan} // 异步接收结果,防止阻塞发送 go func(i int, responseChan chan string) { select { case result := <-responseChan: fmt.Printf(”Request %d: %sn“, i, result) case <-time.After(5 * time.Second): // 超时处理 fmt.Printf(”Request %d: Timeoutn“, i) } }(i, responseChan) time.Sleep(100 * time.Millisecond) // 模拟请求间隔 } close(requestQueue) // 关闭请求队列,通知worker退出 }() // 5. 等待所有worker完成 wg.Wait() fmt.Println(”All requests processed.“)}func worker(client pb.VLLMServiceClient, requestQueue <-chan InferenceRequest, wg *sync.WaitGroup) { defer wg.Done() for req := range requestQueue { // 6. 调用vLLM进行推理 ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second) // 超时控制 defer cancel() r, err := client.Generate(ctx, &pb.GenerateRequest{Prompt: req.Prompt}) if err != nil { log.Printf(”could not generate: %v“, err) req.Response <- ”Error: “ + err.Error() // 发送错误信息 continue } req.Response <- r.GetText() // 发送推理结果 close(req.Response) // 关闭channel } fmt.Println(”Worker exiting.“)}登录后复制
- your_vllm_protobuf_package: 需要替换成你实际的vLLM服务生成的protobuf包的导入路径。
- 超时控制: context.WithTimeout 用于控制每个请求的超时时间,防止goroutine长时间阻塞。
- 错误处理: 在worker中捕获gRPC调用错误,并将错误信息通过channel返回给发送方。
- Channel关闭: 确保在使用完channel后关闭它们,避免goroutine泄漏。
- Buffered Channel: responseChan 使用 buffered channel, 避免发送方goroutine阻塞。
- 异步结果接收: 使用 goroutine 异步接收结果,防止发送方阻塞。
- 请求队列关闭: 在所有请求发送完毕后,关闭 requestQueue channel, 通知 worker goroutine 退出。
- sync.WaitGroup: 使用 sync.WaitGroup 等待所有 worker goroutine 完成。
如何选择合适的并发模型?
选择合适的并发模型取决于你的具体需求。如果推理任务之间没有依赖关系,可以使用Worker Pool。如果推理任务可以分解成多个子任务并行处理,可以使用Fan-out/Fan-in。如果需要控制goroutine的生命周期和超时,可以使用基于Context的并发控制。
如何优化vLLM服务器的性能?
优化vLLM服务器的性能可以从以下几个方面入手:
选择合适的硬件: LLM推理需要大量的计算资源,建议使用高性能的CPU和GPU。
优化模型: 使用量化、剪枝等技术优化模型,可以减少模型的大小和计算量。
使用缓存: 对于频繁请求的相同输入,可以使用缓存来减少推理次数。
调整并发参数: 根据服务器的硬件配置和负载情况,调整并发参数,如线程数、批量大小等。
如何处理vLLM推理过程中的错误?
处理vLLM推理过程中的错误需要从以下几个方面入手:
重试机制: 对于 transient 错误,如网络超时或服务器繁忙,可以进行重试。
熔断机制: 当vLLM服务器出现故障时,可以熔断请求,防止雪崩效应。
日志: 记录详细的日志,方便排查问题。
监控: 监控vLLM服务器的健康状况,及时发现和处理问题。
福利游戏
相关文章
更多-

- 电脑音箱有电流声,该怎么消除?
- 时间:2025-07-23
-

- exr 格式图片在影视后期中常用吗 与 hdr 有何不同
- 时间:2025-07-23
-

- 电脑的键盘输入时出现重复字符,如何解决?
- 时间:2025-07-23
-

- 一文搞懂Paddle2.0中的优化器
- 时间:2025-07-23
-

- 基于Ghost Module的生活垃圾智能分类算法
- 时间:2025-07-23
-

- 第29周新势力车型销量TOP10公布:小米SU7有挑战者了
- 时间:2025-07-23
-

- 从零实现深度学习框架 基础框架的构建
- 时间:2025-07-23
-

- 基于PaddlePaddle2.0-构建残差网络模型
- 时间:2025-07-23
大家都在玩








热门话题

大家都在看
更多-

- 腾讯客服回应微信实时对讲功能:已下线 暂无重新上线计划
- 时间:2025-07-23
-
- GAT币投资指南:深度分析未来潜力
- 时间:2025-07-23
-
- 网友爆料尊界S800自动泊车撞了:车主就在旁边看着 承担全责
- 时间:2025-07-23
-

- 3万级纯电代步小车!全新奔腾小马官图发布:7月27日正式上市
- 时间:2025-07-23
-

- 妖怪金手指石矶娘娘图鉴及对应克制神将
- 时间:2025-07-23
-

- 比特币交易所排行:全球顶级平台及选择指南
- 时间:2025-07-23
-

- 一高速出现断头路却无提醒:引流线导向隔离墙 汽车险些撞上
- 时间:2025-07-23
-
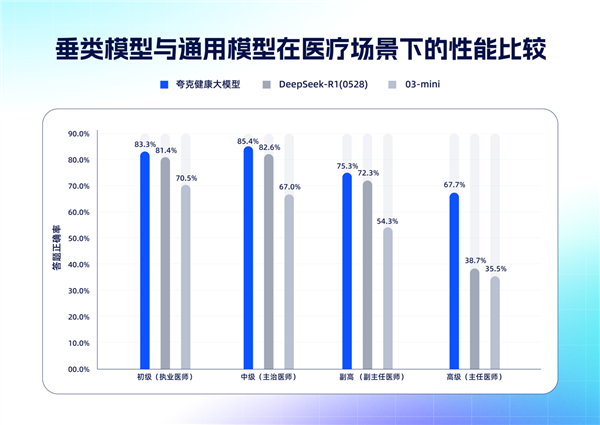
- 国内首个!夸克健康大模型通过12门主任医师考试
- 时间:2025-07-23