



















什么是多模态AI 多模态技术原理与应用解析
时间:2025-06-29 | 作者: | 阅读:0多模态ai是指能同时处理多种信息类型的智能系统,其核心在于融合不同模态的数据进行综合理解。它通过早期、中期或晚期融合方式,结合图像、语音、文本等信息实现更接近人类的认知能力。1. 工作原理是先用适合的模型提取特征再进行联合分析;2. 应用场景包括智能助手、内容审核、医疗诊断和教育学习;3. 面临数据对齐难、信息冲突、训练成本高和评估标准不统一等挑战。随着深度学习的发展,多模态ai正逐步成熟并广泛应用于实际场景中。

多模态AI,简单来说,就是能同时处理多种类型信息的人工智能系统。比如,它不仅能“看”图片,还能“听”声音、“读”文字,甚至结合这些不同形式的信息一起理解内容。传统AI通常专注于单一模态,比如语音识别只处理音频,图像识别只处理视觉信息,而多模态AI的目标是像人一样综合感知和理解世界。

多模态AI是怎么工作的?
多模态AI的核心在于“融合”。它并不是简单地把不同数据拼在一起,而是要让不同模态之间产生联系。常见的做法是先分别用各自适合的模型(比如CNN处理图像、RNN或Transformer处理文本)提取特征,然后在某个阶段把这些特征合并起来进行联合分析。
举个例子:如果你上传一张图片并问“这张照片里是什么颜色的车?”,多模态AI会先识别图片中的物体,再理解文字中关于“颜色”和“车”的问题,最后将两者结合起来回答你。
实现上一般有几种方式:

- 早期融合:直接把原始数据或低层特征拼接在一起处理
- 中期融合:在特征提取之后、决策之前进行融合
- 晚期融合:各自模态独立处理完后再综合判断
哪种方式更好要看具体任务,没有绝对优劣。
多模态技术的实际应用场景
现在越来越多的应用开始用到多模态AI,因为它更接近人类的自然认知方式。
1. 智能助手与聊天机器人现在的语音助手不仅听你说话,还能结合上下文、甚至摄像头看到的画面来提供帮助。比如你指着一张图问“这个牌子写的是什么?”它就能识别图像里的文字并告诉你。
2. 内容审核与推荐系统视频平台不仅要分析字幕和语音,还要看画面内容才能准确判断是否违规。同样,在推荐内容时,结合用户看过的视频、听过的声音和搜索记录,推荐会更精准。
3. 医疗辅助诊断医生可以上传X光片、病历描述和病人自述录音,系统会综合这些信息给出初步建议,比单靠影像或文字判断更全面。
4. 教育与交互式学习学生在做题时上传图片、打字提问,甚至语音口述,AI都能理解,并给出对应的讲解,提升互动体验。
多模态AI面临哪些挑战?
虽然听起来很强大,但多模态AI也并不完美,目前还存在几个关键难点。
- 数据对齐难:不同模态的数据节奏不一样,比如视频帧和语音的时间点不完全同步,需要精确对齐。
- 信息冗余与冲突:有时候不同模态提供的信息可能互相矛盾,或者某些模态信息质量差,会影响整体判断。
- 训练成本高:多模态模型通常更大,训练所需的数据量和计算资源也更多。
- 评估标准不统一:如何衡量一个模型是否真的“理解”了多个模态的关联,目前还没有统一的标准。
这些问题目前还在持续研究中,但随着大模型的发展,多模态能力正变得越来越成熟。
基本上就这些。多模态AI不是什么新概念,但在最近几年才真正开始落地,主要是因为深度学习的发展让模型具备了更强的跨模态理解能力。它的潜力很大,但也要注意合理使用,避免过度依赖。
福利游戏
相关文章
更多-
- 死亡搁浅2怎么回墨西哥
- 时间:2025-07-24
-
- 王于兴师自爆短弓流玩法攻略分享
- 时间:2025-07-24
-

- 幻兽帕鲁漂流者海滨从哪收集 帕鲁漂流者海滨地点收集攻略
- 时间:2025-07-24
-

- 如何用豆包AI写竞品分析报告 豆包AI智能调研实战方案
- 时间:2025-07-24
-

- 使用PaddleX实现的智慧农业病虫检测项目
- 时间:2025-07-24
-

- 中概股与硬科技共振 长鑫科技IPO催化半导体本土化浪潮
- 时间:2025-07-24
-

- 【飞桨黑客松-AIGC - DreamBooth LoRA】HomeTown
- 时间:2025-07-24
-

- 基于Paddle工具链:ROS目标检测部署方案
- 时间:2025-07-24
大家都在玩








热门话题

大家都在看
更多-

- 腾讯客服回应微信实时对讲功能:已下线 暂无重新上线计划
- 时间:2025-07-23
-
- GAT币投资指南:深度分析未来潜力
- 时间:2025-07-23
-
- 网友爆料尊界S800自动泊车撞了:车主就在旁边看着 承担全责
- 时间:2025-07-23
-

- 3万级纯电代步小车!全新奔腾小马官图发布:7月27日正式上市
- 时间:2025-07-23
-

- 妖怪金手指石矶娘娘图鉴及对应克制神将
- 时间:2025-07-23
-

- 比特币交易所排行:全球顶级平台及选择指南
- 时间:2025-07-23
-

- 一高速出现断头路却无提醒:引流线导向隔离墙 汽车险些撞上
- 时间:2025-07-23
-
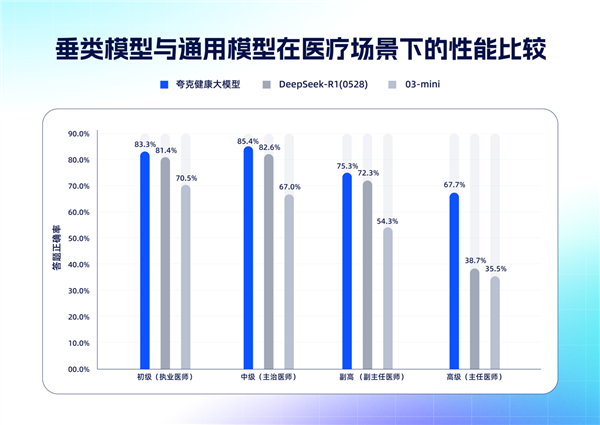
- 国内首个!夸克健康大模型通过12门主任医师考试
- 时间:2025-07-23