



















OmniGen2— 智源研究院开源的多模态生成模型
时间:2025-07-01 | 作者: | 阅读:0omnigen2 是由北京智源人工智能研究院开发的开源多模态生成模型。该模型能够依据文本提示生成高质量图像,并支持通过指令进行图像编辑,例如调整背景或人物特征等。omnigen2 采用了双组件架构,融合了视觉语言模型(vlm)与扩散模型,从而实现对多种生成任务的统一处理。其优势在于开源免费、性能优越以及具备强大的上下文生成能力,适用于商业应用、创意设计及科研开发等多个领域。

- 文本生成图像:可以根据文字描述生成高清晰度且美观的图像,在多个评测基准中表现优异,如在 GenEval 和 DPG-Bench 上分别获得 0.86 和 83.57 的分数。
- 指令驱动图像修改:支持复杂指令下的图像编辑操作,包括局部更改(如更换服装颜色)和整体风格变换(如将照片转换为漫画风格)。在图像编辑任务中,OmniGen2 在多个测试中实现了编辑精准性与图像质量之间的良好平衡。
- 上下文相关生成:可处理并灵活结合多种输入元素(如人物、参考对象和场景),产生新颖且连贯的视觉效果。在 OmniContext 基准测试中,OmniGen2 在视觉一致性方面比现有开源模型高出15%以上。
- 图像理解能力:继承自 Qwen-VL-2.5 基础模型,具有出色的图像内容解析和分析能力。
技术原理
- 双路径结构:OmniGen2 设计了独立的文本与图像解码路径,分别负责处理各自模态的数据。文本部分基于 Qwen2.5-VL-3B 多模态语言模型(MLLM),而图像生成则由一个单独的扩散 Transformer 模块完成,避免了文本生成过程对图像质量的影响。
- 扩散 Transformer 技术:图像生成模块使用了一个包含 32 层的扩散 Transformer,隐藏维度为 2520,总参数量约为 40 亿。该模块采用修正流(Rectified Flow)方法以提升图像生成效率。
- Omni-RoPE 位置嵌入:引入了一种创新的多模态旋转位置编码机制(Omni-RoPE),将位置信息拆分为序列标识符、模态类型、二维坐标等要素,实现对图像每个位置的精确编码,并支持多图空间定位和身份识别。
- 自我优化机制:设计了专门的反思机制,用于提高图像生成的质量与一致性,使模型能够在多轮生成中不断优化输出结果。
- 分阶段训练策略:首先在文字转图像任务上预训练扩散模型,随后引入混合任务进行联合训练,最终实施端到端训练以增强反思能力。
- 数据筛选流程:训练数据来源于视频提取,经过多重过滤步骤,包括 DINO 相似性筛选和 VLM 一致性验证,确保训练集的高质量。
项目地址
- 官方网站:https://www.php.cn/link/368afd895ea0487a5a2691fe08a05513
- GitHub 仓库:https://www.php.cn/link/e7d12fcc90af55f987e5f7017880e9c1
- 论文链接(arXiv):https://www.php.cn/link/38df353da59fb1e8073e120c9c0f9482
应用场景
- 概念设计辅助:设计师可通过简单文字描述快速获取设计草图和概念图。
- 故事内容可视化:创作者可根据故事情节和角色设定生成相应图像。
- 视频素材制作:可用于生成各类场景、角色动作及特效图像,作为动画、特效视频或实拍视频的补充材料。
- 游戏资源创建:开发者可利用文本描述快速构建游戏中的角色与场景。
- 教学资料生成:教育工作者可根据课程内容生成相关图像和示意图,例如讲解历史事件时,生成对应的古代战争场景或历史人物图像。
福利游戏
相关文章
更多-
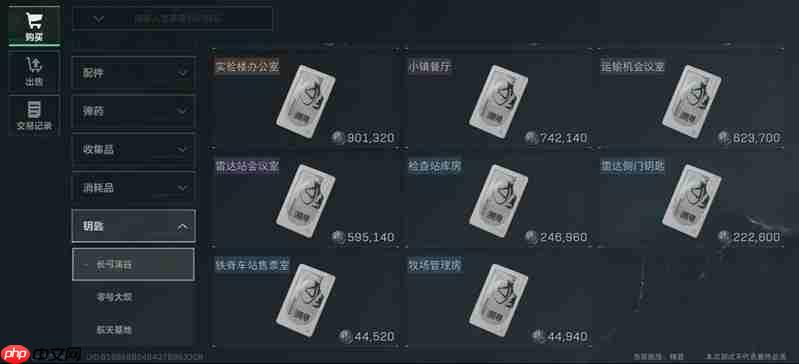
- 三角洲行动长弓溪谷钥匙房怎么刷 长弓溪谷钥匙房速刷方法
- 时间:2025-07-25
-

- 豆包AI怎样生成Markdown文档?技术文章排版自动化
- 时间:2025-07-25
-
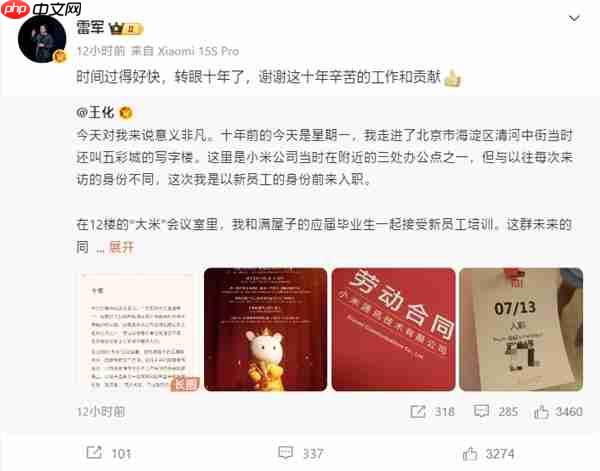
- 王化晒入职小米10周年纪念:雷军亲自感谢
- 时间:2025-07-25
-
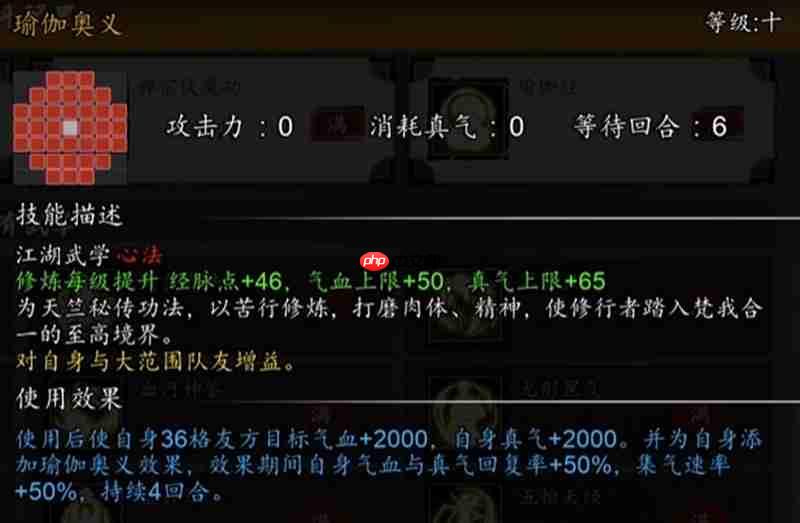
- 逸剑风云决秘籍怎么获取 秘籍获取方式详细介绍
- 时间:2025-07-25
-

- 时光大爆炸蛮族入侵怎么玩 蛮族入侵玩法详细攻略
- 时间:2025-07-25
-

- 明日之后半感染者怎么变身 明日半感染者变身教程
- 时间:2025-07-25
-

- 奥特曼超时空英雄隐藏角色有哪些 隐藏英雄获取方法
- 时间:2025-07-25
-
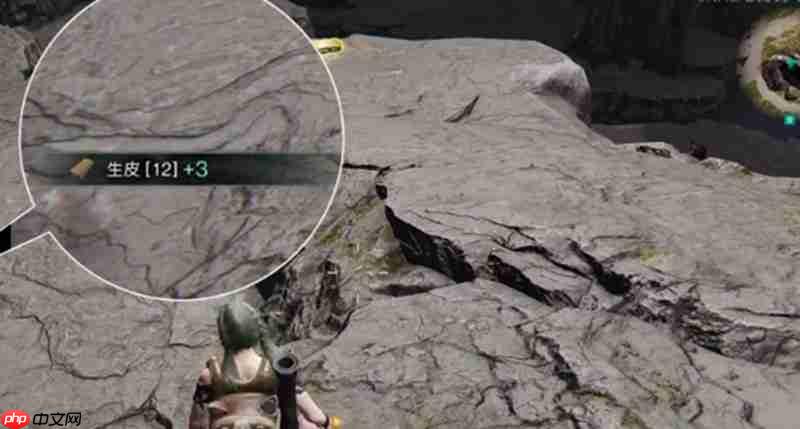
- 七日世界哪里刷皮最多七日 熊洞高效刷皮地点分享
- 时间:2025-07-25
大家都在玩








热门话题

大家都在看
更多-
- 新币上线暴跌原因 越南货币为何不换?
- 时间:2025-07-26
-

- 阿里巴巴首款!夸克AI眼镜正式亮相:深度融合支付宝生态、通义千问大模型
- 时间:2025-07-26
-

- 余承东:享界S9有7个遮阳帘 比任何防晒霜都管用
- 时间:2025-07-26
-

- AI教父辛顿最新警告:人类用AI就像养老虎 要么训好它 要么摆脱它
- 时间:2025-07-26
-

- 豆瓣8.5高分!南京照相馆票房破2亿 有观众哭了4次
- 时间:2025-07-26
-

- 古今2风起蓬莱风元素回返流阵容攻略
- 时间:2025-07-26
-
- Open Campus币投资前景:值得买吗?
- 时间:2025-07-26
-
- 比特币:国家新价值储存首选
- 时间:2025-07-26