



















0528版本发布,DeepSeek-R1 迎来重大升级:数学、编程、逻辑能力大幅跃升,更强推理,更少“幻觉”!
时间:2025-07-02 | 作者: | 阅读:0亲爱的读者朋友们,国产大模型佼佼者?deepseek-r1?近日完成了重要版本升级——deepseek-r1-0528?正式发布!
这次升级绝非小修小补,而是带来了推理能力、代码能力、数学能力、工具使用体验以及可靠性的全面提升。简单来说,就是你的 DeepSeek 助手变得更聪明、更靠谱、更能干了!
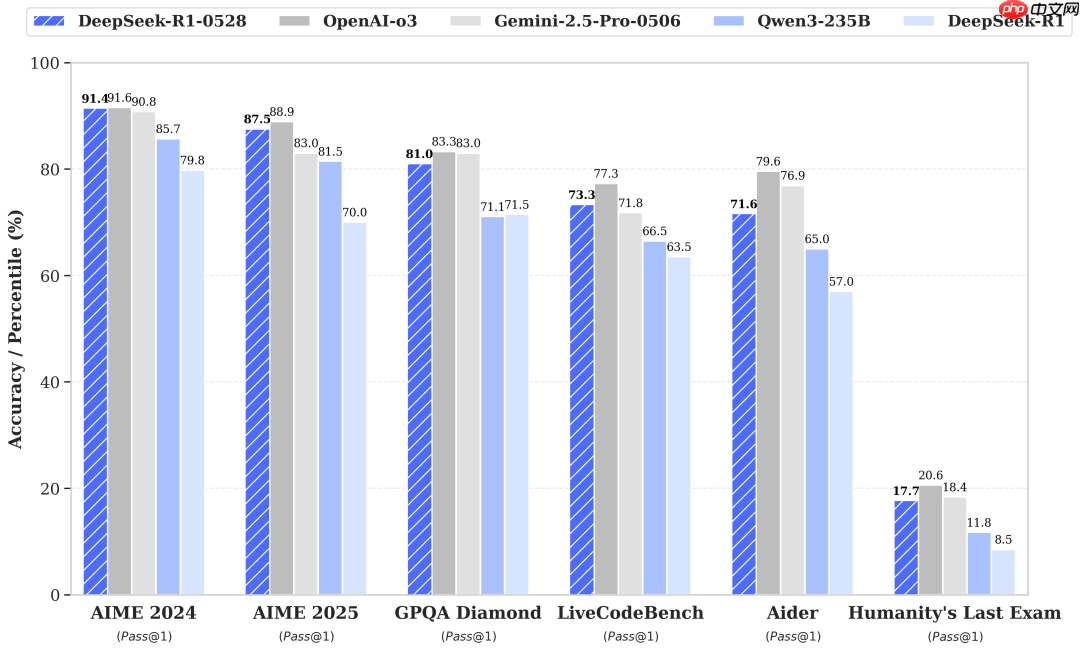
对于开发者或编程爱好者来说,这次升级是重大利好:
LiveCodeBench (2408-2505):?衡量最新编程能力的基准,新版本 Pass@1 从?63.5%?提升至 **73.3%**,能力大幅增强。Codeforces-Div1:?模拟算法竞赛环境,新版本评分从?1530?跃升至?1930,解决难题的能力显著提升。SWE Verified (软件工程验证):?在模拟真实软件工程任务中,新版本解决率从?49.2%?提升至 **57.6%**。Aider-Polyglot (多语言编程):?准确率从?53.3%?提升至 **71.6%**,对多种编程语言的理解和运用更加得心应手。? 数学能力:解题高手再进化DeepSeek-R1 本就以数学见长,0528版本更是锦上添花:
AIME 2024:?Pass@1 从?79.8%?提升至 **91.4%**。AIME 2025:?如前所述,从?70.0%?跃升至 **87.5%**。HMMT 2025 (哈佛-麻省理工数学锦标赛风格):?进步最为惊人,Pass@1 从?41.7%?大幅提升至 **79.4%**,几乎翻倍!CNMO 2024 (中国数学奥林匹克风格):?也从?78.8%?提升至 **86.9%**。?? 工具与使用体验:更智能,更顺手增强函数调用支持: 模型理解和执行函数调用的能力更强,与外部工具或API的交互更顺畅。改进的代码编写体验:?生成代码的质量、可读性和实用性进一步提升。强大的工具使用能力:?在新引入的?Tau-Bench?多工具使用基准测试中,新版本在航空和零售领域分别取得了?53.5%?和?63.9%?的 Pass@1 成绩,展现了利用工具解决复杂任务的能力。更好的系统提示支持:?现在官方应用/网页支持更有效地使用系统提示词(System Prompt)来引导模型行为。使用更便捷:?不再需要在输出开头添加特定字符(如?n)来强制模型进入“思考模式”,交互更自然。以下是图片中的表格内容,已转换为Markdown格式:
Category
Benchmark (Metric)
DeepSeek?R1
DeepSeek?R1 0528
General
MMLU-Redux (EM)
92.9
93.4
MMLU-Pro (EM)
84.0
85.0
GPQA-Diamond (Pass@1)
71.5
81.0
SimpleQA (Correct)
30.1
27.8
FRAMES (Acc.)
82.5
83.0
Humanity's Last Exam (Pass@1)
8.5
17.7
Code
LiveCodeBench (2408-2505) (Pass@1)
63.5
73.3
Codeforces-Div1 (Rating)
1530
1930
SWE Verified (Resolved)
49.2
57.6
Aider-Polyglot (Acc.)
53.3
71.6
Math
AIME 2024 (Pass@1)
79.8
91.4
AIME 2025 (Pass@1)
70.0
87.5
HMMT 2025 (Pass@1)
41.7
79.4
CNMO 2024 (Pass@1)
78.8
86.9
Tools
BFCL_v3_MultiTurn (Acc)
-
37.0
Tau-Bench (Pass@1)
-
53.5(Airline)/63.9(Retail)
? 开源贡献:思维链的力量此次升级还带来了一个重要的副产品:DeepSeek-R1-0528-Qwen3-8B。
这是将 DeepSeek-R1-0528 强大的“思维链”(Chain-of-Thought)提炼出来,用于训练通义千问(Qwen)的 80 亿参数基础模型(Qwen3-8B Base)的结果。这个仅?8B?参数的小模型表现惊人!在?AIME 2024?测试上达到了?86.0%?的 Pass@1,**超越了原版 Qwen3-8B 高达 10%,甚至媲美了经过特殊优化的 235B 超大模型 (Qwen3-235B-thinking)**!这证明了 DeepSeek-R1-0528 思维链的巨大价值,为研究更高效的小规模推理模型提供了宝贵资源。? 如何体验升级版 DeepSeek-R1-0528?官方网站/App 聊天:?访问 **chat.deepseek.com**,打开聊天界面上的?“DeepThink”按钮,即可体验最强推理模式!系统提示已自动设置为当前日期。API 接入:?开发者可通过?platform.deepseek.com?提供的?OpenAI 兼容 API,轻松将强大的 DeepSeek-R1-0528 集成到您的应用中。本地运行:?技术爱好者可参考 DeepSeek 官方仓库获取模型,在本地运行体验(需注意使用建议的变化)。? 总结DeepSeek-R1-0528?是一次质的飞跃。它通过算法优化和增加计算投入,显著提升了核心的深度推理能力,在数学、编程、逻辑等硬核任务上取得了突破性进展,性能直逼全球顶尖模型。同时,幻觉减少、函数调用增强、代码体验优化等改进也让日常使用更可靠、更顺手。
福利游戏
相关文章
更多-
- “剧本杀主持人”需要具备哪种能力 蚂蚁新村7月27日答案
- 时间:2025-07-27
-
- 猫相较于人类而言,夜视能力大约是几倍 蚂蚁庄园7月28日答案最新
- 时间:2025-07-27
-
- 猜一猜:猫的夜视能力大约是人类的几倍 蚂蚁庄园7月28日答案早知道
- 时间:2025-07-27
-

- 夸克高清国产片免费观看 夸克影院国产大片在线入口
- 时间:2025-07-26
-

- 夸克高清资源在线观看 夸克免费国产大片播放入口
- 时间:2025-07-26
-

- UC高清大片免费在线观看入口 免费观看国产大片地址uc浏览器
- 时间:2025-07-26
-

- UC免费国产大片播放地址 高清国产视频UC浏览器在线观看入口
- 时间:2025-07-26
-
- 我国古代计时法中的“丑时”指的是 蚂蚁庄园7月27日答案早知道
- 时间:2025-07-26

大家都在玩












大家都在看
更多-
- 李楠:别再问我魅族22了
- 时间:2025-07-28
-

- 全球首款多模态梦境脑机接口发布:枕头形态 可缓解焦虑、改善睡眠
- 时间:2025-07-28
-

- 以太币(ETH)价格:623枚ETH价值几何?
- 时间:2025-07-28
-

- 再次刷新安全成绩!特斯拉Model Y获“最高安全车型”认证
- 时间:2025-07-28
-

- 大卡与运动强度的关系 心率与热量消耗
- 时间:2025-07-28
-

- 这种瓜正上市 一旦发苦千万别吃!有毒
- 时间:2025-07-28
-
- 欧翼交易所注册攻略:简单易上手
- 时间:2025-07-28
-

- 鸣潮弗洛洛阵容搭配
- 时间:2025-07-28