个人实现的反向文心(无需训练的AI看图说话,你不心动?)
时间:2025-07-16 | 作者: | 阅读:0本文介绍ZeroCap的中文Paddle迁移实现,这是一个零样本图像描述模型。项目用Ernie-VIL替换原论文的CLIP,GPT采用中文版,涉及GPTChineseTokenizer、GPTLMHeadModel等模型。代码包含安装库、模型初始化、定义相关函数及生成文本等内容,还展示了效果示例,适合想了解深度学习Image Caption的新手,可参考相关B站科普视频。
_wishdown.com")
ZeroCap:zero shot的image caption模型paddle迁移实现(中文版)
论文:ZeroCap: Zero-Shot Image-to-Text Generation for Visual-Semantic Arithmetic ,2022.3.31
代码: https://github.com/YoadTew/zero-shot-image-to-text
英文Paddle实现(对于zerpcap论文个人讲解也可参考该AI Studio项目) :?ZeroCap
对深度学习 Image Caption 什么都不太了解 但是很想去了解学习 的同学可以看看我做的这个B站视频:
用大白话讲Paper之Image caption ZeroCap,科普视频,不想学的请直接划走
这个视频我真的尽可能用大白话去把一个个概念用最朴素的语言讲了出来,麻烦各位看官动动你们的小手为我可怜的视频增加点播放量,谢谢大家
超级 超级 推荐新手观看上面这个B站视频!!!!
本项目使用以下模型:
GPTChineseTokenizer,GPTLMHeadModel,ErnieViLProcessor, ErnieViLModel. Ernie-VIL替换原论文英文版的CLIP,然后GPT使用中文版
from paddlenlp.transformers import GPTChineseTokenizer,GPTLMHeadModelfrom paddlenlp.transformers import ErnieViLProcessor, ErnieViLModel登录后复制
效果展示:
- input:
_wishdown.com")
output: 这张图片讲的故事是猫躲帐
- input:
_wishdown.com")
output: 这张图片讲的故事是小狗Jack在草地上.
- input:
_wishdown.com")
output: 这张图片讲的故事是梅西在运球的时候
In [?]#安装库!pip install --upgrade pip!pip uninstall paddlenlp -y!pip install paddlenlp==2.4.1!pip install regex!pip install fastcore登录后复制In [2]
import paddlenlp.transformers.clip as clipfrom paddlenlp.transformers import GPTLMHeadModel as GPT2LMHeadModel,GPTTokenizer as GPT2Tokenizerimport paddleimport paddle.nn as nnfrom paddlenlp.transformers import CLIPProcessor, CLIPModelfrom PIL import Imageimport numpy as npimport collectionsfrom paddlenlp.data import Padfrom paddlenlp.transformers import ErnieViLTokenizer#测试ErnieViLTokenizer使用tokenizer = ErnieViLTokenizer.from_pretrained('ernie_vil-2.0-base-zh')print(tokenizer('我爱你宝贝'))登录后复制
[2023-01-29 03:28:12,985] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/ernie_vil/ernie_vil-2.0-base-zh/vocab.txt and saved to /home/aistudio/.paddlenlp/models/ernie_vil-2.0-base-zh[2023-01-29 03:28:12,989] [ INFO] - Downloading vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/ernie_vil/ernie_vil-2.0-base-zh/vocab.txt100%|██████████| 182k/182k [00:00<00:00, 3.23MB/s][2023-01-29 03:28:13,209] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie_vil-2.0-base-zh/tokenizer_config.json[2023-01-29 03:28:13,212] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie_vil-2.0-base-zh/special_tokens_map.json登录后复制
{'input_ids': [1, 75, 329, 226, 707, 1358, 2]}登录后复制登录后复制In [3]
import paddlenlp.transformers.clip as clipfrom paddlenlp.transformers import GPTChineseTokenizer,GPTLMHeadModelimport paddle# from paddlenlp.transformers import ErnieForGenerationimport paddle.nn as nnfrom paddlenlp.transformers import ErnieViLProcessor, ErnieViLModelfrom PIL import Imageimport numpy as npimport collectionsfrom paddlenlp.data import Padfrom paddlenlp.transformers import ErnieViLTokenizertokenizer = ErnieViLTokenizer.from_pretrained('ernie_vil-2.0-base-zh')print(tokenizer('我爱你宝贝'))from fastcore.all import *@patch_to(GPTChineseTokenizer)def convert_ids_to_tokens(self, ids, skip_special_tokens=False): if not isinstance(ids, (list, tuple)): return self._convert_id_to_token(ids) tokens = [self._convert_id_to_token(_id) for _id in ids] if skip_special_tokens: return [ token for token in tokens if token not in self.all_special_tokens ] return tokensdef add_context0(x, y): return (x[0] + y[0], x[1] + y[1])def add_context(x, y): a = x.__class__(k=(x.k+y[0]),v = (x.v+y[1])) return afrom datetime import datetimeimport sysdef log_info(text, verbose=True): if verbose: dt_string = datetime.now().strftime(”%d/%m/%Y %H:%M:%S“) print(f'{dt_string} | {text}') sys.stdout.flush()# def add_context(x, y):# # print(x.__class__,x)# Cache = collections.namedtuple(”Cache“,”k,v“)# a = Cache(k=(x.k+y[0]).mean(axis = 2,keepdim = True),v = (x.v+y[1]).mean(axis = 2,keepdim = True))# return aclass CLIPTextGenerator: def __init__(self, seed=0, lm_model='gpt-2', forbidden_tokens_file_path='./forbidden_tokens.npy', clip_checkpoints='./clip_checkpoints', target_seq_length=50, reset_context_delta=True, num_iterations=5, clip_loss_temperature=0.01, clip_scale=1., ce_scale=0.2,#0.2 stepsize=0.3, grad_norm_factor=0.9, fusion_factor=0.99, repetition_penalty=1., end_token='。', end_factor=1.01, forbidden_factor=20, **kwargs): # set Random seed paddle.seed(seed) np.random.seed(seed) # Initialize Language model self.context_prefix = '' self.lm_tokenizer = GPTChineseTokenizer.from_pretrained('gpt-cpm-large-cn') self.lm_model = GPTLMHeadModel.from_pretrained(”gpt-cpm-large-cn“) # self.context_prefix = self.lm_tokenizer.bos_token self.lm_model.eval() self.forbidden_tokens = np.load(forbidden_tokens_file_path) # # Freeze LM weights for param in self.lm_model.parameters(): param.requires_grad = False # # Initialize CLIP self.clip = ErnieViLModel.from_pretrained(”ernie_vil-2.0-base-zh“) self.clip_preprocess = ErnieViLProcessor.from_pretrained(”ernie_vil-2.0-base-zh“) # # convert_models_to_fp32(self.clip) # # Init arguments self.target_seq_length = target_seq_length self.reset_context_delta = reset_context_delta self.num_iterations = num_iterations self.clip_loss_temperature = clip_loss_temperature self.clip_scale = clip_scale self.ce_scale = ce_scale self.stepsize = stepsize self.grad_norm_factor = grad_norm_factor self.fusion_factor = fusion_factor self.repetition_penalty = repetition_penalty # self.end_token = self.lm_tokenizer.encode(end_token)[0] self.end_token = self.lm_tokenizer.encode(end_token)[”input_ids“][0] self.end_factor = end_factor self.ef_idx = 1 self.forbidden_factor = forbidden_factor def get_img_feature(self, img_path, weights = None): imgs = [Image.open(x) for x in img_path] # print(”imgs“,imgs) clip_imgs = [self.clip_preprocess(images = x,return_tensors=”pd“)[”pixel_values“] for x in imgs] with paddle.no_grad(): image_fts = [self.clip.get_image_features(x) for x in clip_imgs] # print(”image_fts“,image_fts) if weights is not None: image_features = sum([x * weights[i] for i, x in enumerate(image_fts)]) else: image_features = sum(image_fts) image_features = image_features / image_features.norm(axis=-1, keepdim=True) return image_features.detach() def get_txt_features(self, text): # print(”text“,text) clip_texts = tokenizer(text) clip_texts = Pad(pad_val=0)(clip_texts[”input_ids“]) clip_texts = paddle.to_tensor(clip_texts) # clip_texts = clip.tokenize(text) # print(”clip_text“,clip_texts) with paddle.no_grad(): text_features = self.clip.get_text_features(clip_texts) text_features = text_features / text_features.norm(axis=-1, keepdim=True) return text_features.detach() def run(self, image_features, cond_text, beam_size): self.image_features = image_features context_tokens = self.lm_tokenizer.encode(self.context_prefix + cond_text) # print(”context_tokens0“,context_tokens) output_tokens, output_text = self.generate_text(context_tokens[”input_ids“], beam_size) return output_text def generate_text(self, context_tokens, beam_size): context_tokens = paddle.to_tensor(context_tokens).unsqueeze(0) print(”158context_tokens“,context_tokens) gen_tokens = None scores = None seq_lengths = paddle.ones([beam_size]) is_stopped = paddle.zeros([beam_size], dtype=paddle.bool) for i in range(self.target_seq_length): # print(”146行“) probs = self.get_next_probs(i, context_tokens) logits = probs.log() if scores is None: scores, next_tokens = logits.topk(beam_size, -1) context_tokens = context_tokens.expand([beam_size, *context_tokens.shape[1:]]) # print(next_tokens.shape) next_tokens, scores = next_tokens.transpose([1, 0]), scores.squeeze(0) if gen_tokens is None: gen_tokens = next_tokens else: gen_tokens = gen_tokens.expand(beam_size, *gen_tokens.shape[1:]) gen_tokens = paddle.concat((gen_tokens, next_tokens), axis=1) else: # print(”logits“,logits.shape) # print(”is_stopped“,is_stopped) # print(”i“,i) logits[is_stopped] = -float(np.inf) logits[is_stopped, 0] = 0 scores_sum = scores[:, None] + logits seq_lengths[~is_stopped] += 1 scores_sum_average = scores_sum / seq_lengths[:, None] scores_sum_average, next_tokens = scores_sum_average.reshape([-1]).topk( beam_size, -1) next_tokens_source = next_tokens // scores_sum.shape[1] seq_lengths = seq_lengths[next_tokens_source] next_tokens = next_tokens % scores_sum.shape[1] next_tokens = next_tokens.unsqueeze(1) gen_tokens = gen_tokens[next_tokens_source] gen_tokens = paddle.concat((gen_tokens, next_tokens), axis=-1) context_tokens = context_tokens[next_tokens_source] scores = scores_sum_average * seq_lengths # print(”is_stopped“,is_stopped,”next_tokens_source“,next_tokens_source) # is_stopped = is_stopped[next_tokens_source] is_stopped = is_stopped[list(map(int,list(next_tokens_source.numpy())))] context_tokens = paddle.concat((context_tokens, next_tokens), axis=1) # print(”next_tokens“,next_tokens) # print(”is_stopped“,is_stopped) temp_a = next_tokens.equal(paddle.full_like(next_tokens,self.end_token)).astype(”float32“).squeeze() # print(temp_a) # is_stopped = is_stopped + next_tokens.equal(self.end_token).astype(”float32“).squeeze() # is_stopped = is_stopped + next_tokens.equal(paddle.full_like(next_tokens,self.end_token)).astype(”float32“).squeeze() is_stopped = paddle.any(paddle.stack([is_stopped.astype(”float32“),temp_a],axis=0).astype(”bool“),axis=0) # print(”is_stopped“,is_stopped) #### tmp_scores = scores / seq_lengths tmp_output_list = gen_tokens.numpy() tmp_output_texts = [self.lm_tokenizer.convert_ids_to_string(list(map(int,list(tmp_output)))) for tmp_output, tmp_length in zip(tmp_output_list, seq_lengths)] tmp_order = tmp_scores.argsort(descending=True) tmp_output_texts = [tmp_output_texts[i] + ' %% ' + str(tmp_scores[i].numpy()) for i in tmp_order] log_info(tmp_output_texts, verbose=True) #### if is_stopped.all(): break scores = scores / seq_lengths output_list = gen_tokens.numpy() output_texts = [ self.lm_tokenizer.convert_ids_to_string(list(map(int,list(output[: int(length)])))) for output, length in zip(output_list, seq_lengths) ] order = scores.argsort(descending=True) output_texts = [output_texts[i] for i in order] return context_tokens, output_texts def get_next_probs(self, i, context_tokens): last_token = context_tokens[:, -1:] if self.reset_context_delta and context_tokens.shape[1] > 1: # print(context_tokens[:, :-1]) # print(self.lm_model(context_tokens[:, :-1],use_cache=True)) context = self.lm_model(context_tokens[:, :-1],use_cache=True)[1] #得到k v # print(”context180“,context) # Logits of LM with unshifted context logits_before_shift = self.lm_model(context_tokens) # print(”220row“,logits_before_shift.shape) logits_before_shift = logits_before_shift[:, -1, :] probs_before_shift = nn.functional.softmax(logits_before_shift, axis=-1).detach() if context: context = self.shift_context(i, context, last_token, context_tokens, probs_before_shift) lm_output = self.lm_model(last_token, cache=context,use_cache=True) logits, past = ( lm_output[0], lm_output[1], ) logits = logits[:, -1, :] # logits = self.update_special_tokens_logits(context_tokens, i, logits) probs = nn.functional.softmax(logits, axis=-1) probs = (probs ** self.fusion_factor) * (probs_before_shift ** (1 - self.fusion_factor)) probs = probs / probs.sum() return probs def shift_context(self, i, context, last_token, context_tokens, probs_before_shift): context_delta = [tuple([np.zeros(x.shape).astype(”float32“) for x in p]) for p in context] # context_delta = [ for p in context] window_mask = paddle.ones_like(context[0][0]) for i in range(self.num_iterations): curr_shift = [tuple([paddle.to_tensor(x,stop_gradient = False) for x in p_]) for p_ in context_delta] # for p0, p1 in curr_shift: # # p0.retain_grad() # # p1.retain_grad() # print(”context220“,len(cond_text),context) shifted_context = list(map(add_context, context, curr_shift)) # print(last_token,len(shifted_context)) # print(shifted_context) shifted_outputs = self.lm_model(last_token, cache=shifted_context,use_cache = True) # logits = shifted_outputs[”logits“][:, -1, :] logits = shifted_outputs[0][:, -1, :] probs = nn.functional.softmax(logits, axis=-1) loss = 0.0 # CLIP LOSS clip_loss, clip_losses = self.clip_loss(probs, context_tokens) loss += self.clip_scale * clip_loss # CE/Fluency loss if isinstance(self.ce_scale,float): ce_loss = self.ce_scale * ((probs * probs.log()) - (probs * probs_before_shift.log())).sum(-1) else: a = self.ce_scale[0] b = self.ce_scale[1] ce_loss = (b - (b-a)/self.num_iterations*i) * ((probs * probs.log()) - (probs * probs_before_shift.log())).sum(-1) loss += ce_loss.sum() loss.backward() # print(”loss finish“) # ---------- Weights ---------- combined_scores_k = -(ce_loss) combined_scores_c = -(self.clip_scale * paddle.stack(clip_losses)).squeeze(1) # print(295,”combined_scores_k“,combined_scores_k.shape,”combined_scores_c“,combined_scores_c.shape) # minmax if combined_scores_k.shape[0] == 1: tmp_weights_c = tmp_weights_k = paddle.ones(combined_scores_k.shape) else: tmp_weights_k = ((combined_scores_k - combined_scores_k.min())) / (combined_scores_k.max() - combined_scores_k.min()) tmp_weights_c = ((combined_scores_c - combined_scores_c.min())) / (combined_scores_c.max() - combined_scores_c.min()) # print(tmp_weights_k) tmp_weights = 0.5 * tmp_weights_k + 0.5 * tmp_weights_c # print(”305 tmp_weights“,tmp_weights.shape) tmp_weights = tmp_weights.reshape([tmp_weights.shape[0], 1, 1, 1]) factor = 1 # --------- Specific Gen --------- sep_grads = None for b in range(context_tokens.shape[0]): tmp_sep_norms = [[(paddle.norm(x.grad[b:(b + 1)] * window_mask[b:(b + 1)]) + 1e-15) for x in p_] for p_ in curr_shift] # normalize gradients tmp_grad = [tuple([-self.stepsize * factor * ( x.grad[b:(b + 1)] * window_mask[b:(b + 1)] / tmp_sep_norms[i][ j] ** self.grad_norm_factor).numpy() for j, x in enumerate(p_)]) for i, p_ in enumerate(curr_shift)] if sep_grads is None: sep_grads = tmp_grad else: for l_index in range(len(sep_grads)): sep_grads[l_index] = list(sep_grads[l_index]) for k_index in range(len(sep_grads[0])): sep_grads[l_index][k_index] = np.concatenate( (sep_grads[l_index][k_index], tmp_grad[l_index][k_index]), axis=0) sep_grads[l_index] = tuple(sep_grads[l_index]) final_grads = sep_grads # --------- update context --------- context_delta = list(map(add_context0, final_grads, context_delta)) # print(”curr_shift“,len(curr_shift),curr_shift[0]) for p0, p1 in curr_shift: # print(p0.grad) p0.stop_gradient = True p1.stop_gradient = True p0.grad.zero_() p1.grad.zero_() p0.stop_gradient = False p1.stop_gradient = False # with paddle.no_grad(): # for p0, p1 in curr_shift: # p0.grad.zero_() # p1.grad.zero_() new_context = [] for p0, p1 in context: # new_context.append((p0.detach(), p1.detach())) new_context.append(shifted_outputs[1][0].__class__(p0.detach(), p1.detach())) context = new_context context_delta = [tuple([paddle.to_tensor(x,stop_gradient = False) for x in p_]) for p_ in context_delta] context = list(map(add_context, context, context_delta)) new_context = [] for p0, p1 in context: p0 = p0.detach() p0.stop_gradient = False p1 = p1.detach() p1.stop_gradient = False # new_context.append((p0, p1)) new_context.append(shifted_outputs[1][0].__class__(p0, p1)) context = new_context return context def update_special_tokens_logits(self, context_tokens, i, logits): for beam_id in range(context_tokens.shape[0]): for token_idx in set(context_tokens[beam_id][-4:].tolist()): factor = self.repetition_penalty if logits[beam_id, token_idx] > 0 else (1 / self.repetition_penalty) logits[beam_id, token_idx] /= factor if i >= self.ef_idx: factor = self.end_factor if logits[beam_id, self.end_token] > 0 else (1 / self.end_factor) logits[beam_id, self.end_token] *= factor if i == 0: start_factor = 1.6 factor = start_factor if logits[beam_id, self.end_token] > 0 else (1 / start_factor) logits[beam_id, self.end_token] /= factor for token_idx in list(self.forbidden_tokens): factor = self.forbidden_factor if logits[beam_id, token_idx] > 0 else (1 / self.forbidden_factor) logits[beam_id, token_idx] /= factor return logits def clip_loss(self, probs, context_tokens): for p_ in self.clip.text_model.parameters(): if p_.grad is not None: p_.grad.data.zero_() top_size = 512 _, top_indices = probs.topk(top_size, -1) # print(”417“,context_tokens[0]) # print(”418“,self.lm_tokenizer.decode(context_tokens[0])) # prefix_texts = [self.lm_tokenizer.decode(x).replace(self.lm_tokenizer.bos_token, '') for x in context_tokens] prefix_texts = [self.lm_tokenizer.convert_ids_to_string(list(map(int,list(x.numpy())))) for x in context_tokens] # print(422,prefix_texts) clip_loss = 0 losses = [] for idx_p in range(probs.shape[0]): top_texts = [] prefix_text = prefix_texts[idx_p] for x in top_indices[idx_p]: top_texts.append(prefix_text + self.lm_tokenizer.convert_ids_to_string(list(map(int,list(x.numpy()))))) text_features = self.get_txt_features(top_texts) with paddle.no_grad(): similiraties = (self.image_features @ text_features.T) target_probs = nn.functional.softmax(similiraties / self.clip_loss_temperature, axis=-1).detach() # print(”target_probs“,target_probs) target_probs = target_probs.astype(paddle.float32) target = paddle.zeros_like(probs[idx_p]) target.stop_gradient = True # print(”target_probs“,target_probs.shape,target_probs.stop_gradient) # print(”top_indices“,top_indices.stop_gradient,”idx_p“,idx_p) # print(”target“,target.stop_gradient) target[top_indices[idx_p]] = target_probs[0] target = target.unsqueeze(0) cur_clip_loss = paddle.sum(-(target * paddle.log(probs[idx_p:(idx_p + 1)]))) clip_loss += cur_clip_loss losses.append(cur_clip_loss) return clip_loss, losses # text_generator = CLIPTextGenerator()# image_features = text_generator.get_img_feature([”微信图片_20221026225709.jpg“])# cond_text = ”Image of a“# beam_size = 5# text_generator.run(image_features,cond_text,beam_size)登录后复制
[2023-01-29 03:28:13,274] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie_vil-2.0-base-zh/vocab.txt[2023-01-29 03:28:13,302] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie_vil-2.0-base-zh/tokenizer_config.json[2023-01-29 03:28:13,305] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie_vil-2.0-base-zh/special_tokens_map.json登录后复制
{'input_ids': [1, 75, 329, 226, 707, 1358, 2]}登录后复制登录后复制In [?]
image_path = ”微信图片_20221026225709.jpg“ #请修改对应图片路径text_generator = CLIPTextGenerator(ce_scale=0.2)image_features = text_generator.get_img_feature([image_path])#输入图片路径地址cond_text = ”这张图片讲的故事是“# cond_text = ”这张图片描述的是(详细描述):“beam_size = 5captions = text_generator.run(image_features,cond_text,beam_size)encoded_captions = [text_generator.clip.get_text_features(paddle.to_tensor(tokenizer(c)[”input_ids“]).unsqueeze(0)) for c in captions]encoded_captions = [x / x.norm(axis=-1, keepdim=True) for x in encoded_captions]best_clip_idx = (paddle.concat(encoded_captions) @ image_features.t()).squeeze().argmax().item()print(captions)print('best clip:', cond_text + captions[best_clip_idx])登录后复制
来源:https://www.php.cn/faq/1409981.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- nef 格式图片降噪处理用什么工具 效果如何
- 时间:2025-07-29
-

- 邮箱长时间未登录被注销了能恢复吗?
- 时间:2025-07-29
-

- Outlook收件箱邮件不同步怎么办?
- 时间:2025-07-29
-

- 为什么客户端收邮件总是延迟?
- 时间:2025-07-29
-

- 一英寸在磁带宽度中是多少 老式设备规格
- 时间:2025-07-29
-

- 大卡和年龄的关系 不同年龄段热量需求
- 时间:2025-07-29
-

- jif 格式是 gif 的变体吗 现在还常用吗
- 时间:2025-07-29
-

- hdr 格式图片在显示器上能完全显示吗 普通显示器有局限吗
- 时间:2025-07-29
大家都在玩








大家都在看
更多-
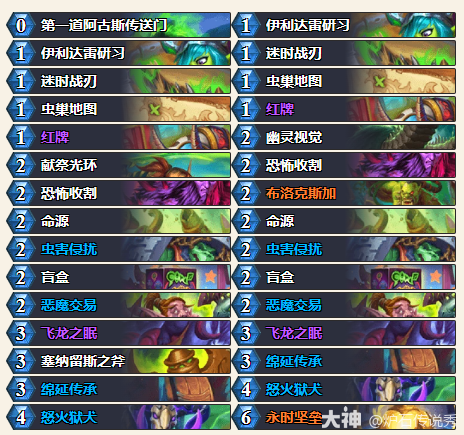
- 炉石传说CTTlabarashh永时奇闻瞎卡组代码分享
- 时间:2025-11-06
-
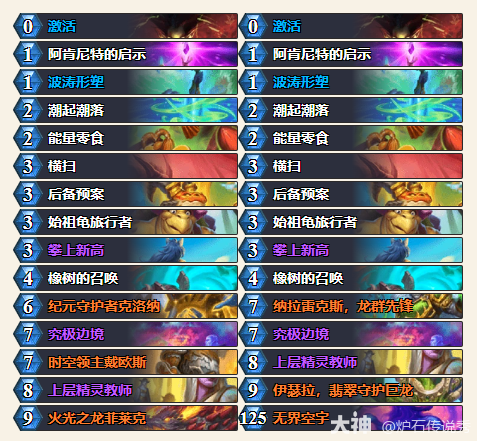
- 炉石传说CTThomiwas火龙德卡组代码分享
- 时间:2025-11-06
-

- 炉石传说CTTAlexander爆发贼卡组代码分享
- 时间:2025-11-06
-
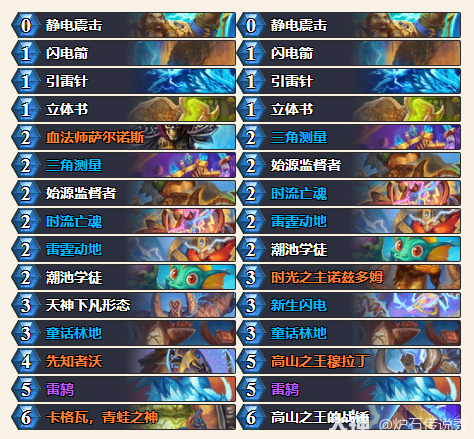
- 炉石传说CTThomi自然萨卡组代码分享
- 时间:2025-11-06
-
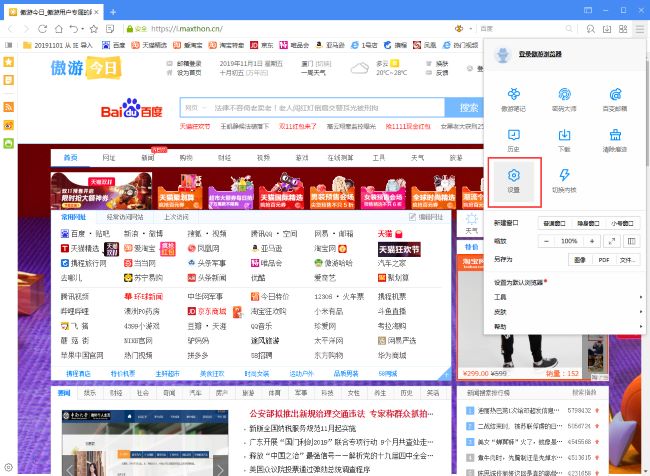
- 傲游浏览器怎么设置自定义主页
- 时间:2025-11-06
-

- 好听两个字情侣网名 唯美2字的游戏名
- 时间:2025-11-06
-

- 2?2?/??.????一种很新的十一月朋友圈
- 时间:2025-11-06
-

- 笔记本Fn键失灵修复小技巧
- 时间:2025-11-06