DataFountain 产品评论观点提取「0.70230547」
时间:2025-07-17 | 作者: | 阅读:0随着互联网的不断深入普及,越来越多的用户在体验企业提供的产品和服务时,会将其感受和评论分享在互联网上。这些评价和反馈信息对企业针对性地改善产品和服务有极强的指导意义,但互联网的海量信息容量让人工查找并处理评价内容的方案代价高昂。本赛题提供了一个银行业产品评价的场景,探索利用自然语言处理技术来完成评论观点的自动化提取,为行业的进一步发展提高提供参考。

一、竞赛介绍
CCF大数据与计算智能大赛(CCF Big Data & Computing Intelligence Contest,简称CCF BDCI)由中国计算机学会于2013年创办。大赛由国家自然科学基金委员会指导,是大数据与人工智能领域的算法、应用和系统大型挑战赛事。大赛面向重点行业和应用领域征集需求,以前沿技术与行业应用问题为导向,以促进行业发展及产业升级为目标,以众智、众包的方式,汇聚海内外产学研用多方智慧,为社会发现和培养了大量高质量数据人才。
大赛迄今已成功举办八届,累计吸引全球1500余所高校、1800家企事业单位及80余所科研机构的12万余人参与,已成为中国大数据与人工智能领域最具影响力的活动之一,是中国大数据综合赛事第一品牌。
2021年第九届大赛以“数引创新,竞促汇智”为主题,立足余杭、面向全球,于9月至12月举办。大赛将致力于解决来自政府、企业真实场景中的痛点、难点问题,邀请全球优秀团队参与数据资源开发利用,广泛征集信息技术应用解决方案。
1.1 赛题背景
比赛地址:https://www.datafountain.cn/competitions/529
随着互联网的不断深入普及,越来越多的用户在体验企业提供的产品和服务时,会将其感受和评论分享在互联网上。这些评价和反馈信息对企业针对性地改善产品和服务有极强的指导意义,但互联网的海量信息容量让人工查找并处理评价内容的方案代价高昂。本赛题提供了一个银行业产品评价的场景,探索利用自然语言处理技术来完成评论观点的自动化提取,为行业的进一步发展提高提供参考。1.2 赛题任务
观点提取旨在从非结构化的评论文本中提取标准化、结构化的信息,如产品名、评论维度、评论观点等。此处希望大家能够通过自然语言处理的语义情感分析技术判断出一段银行产品评论文本的情感倾向,并能进一步通过语义分析和实体识别,标识出评论所讨论的产品名,评价指标和评价关键词。
因此我们就可以分为命名实体识别和情感分类两个任务来做,然后把这两个任务的结果合并提交到官网就行了。
二、情感分类部分
2.0 方案介绍
2.0.1 基于训练难度划分数据集
在进行 K 折交叉验证时,首先根据样本类别做随机分层抽样,但这样的划分仍会导致模型训练结果波动较大,我们认为这有可能是每折训练数据的难易程度不均衡导致的,因此,我们在原有的数据划分方法上引入了对数据训练难度的考虑。
具体来说,首先使用基线模型对全量标注数据预测,得到预测分数,将其映射至 3 个难度级别,然后与真实标签组合得到共 9 种新的难度标签,之后对其使用随机 K 折分层抽样划分出 K 折训练集和验证集。
下图是使用基线模型进行 10 折交叉验证的训练结果,可以看到基于训练难度对数据集划分能够在很大程度上提升模型的稳定性,从而更好地进行之后的模型融合。
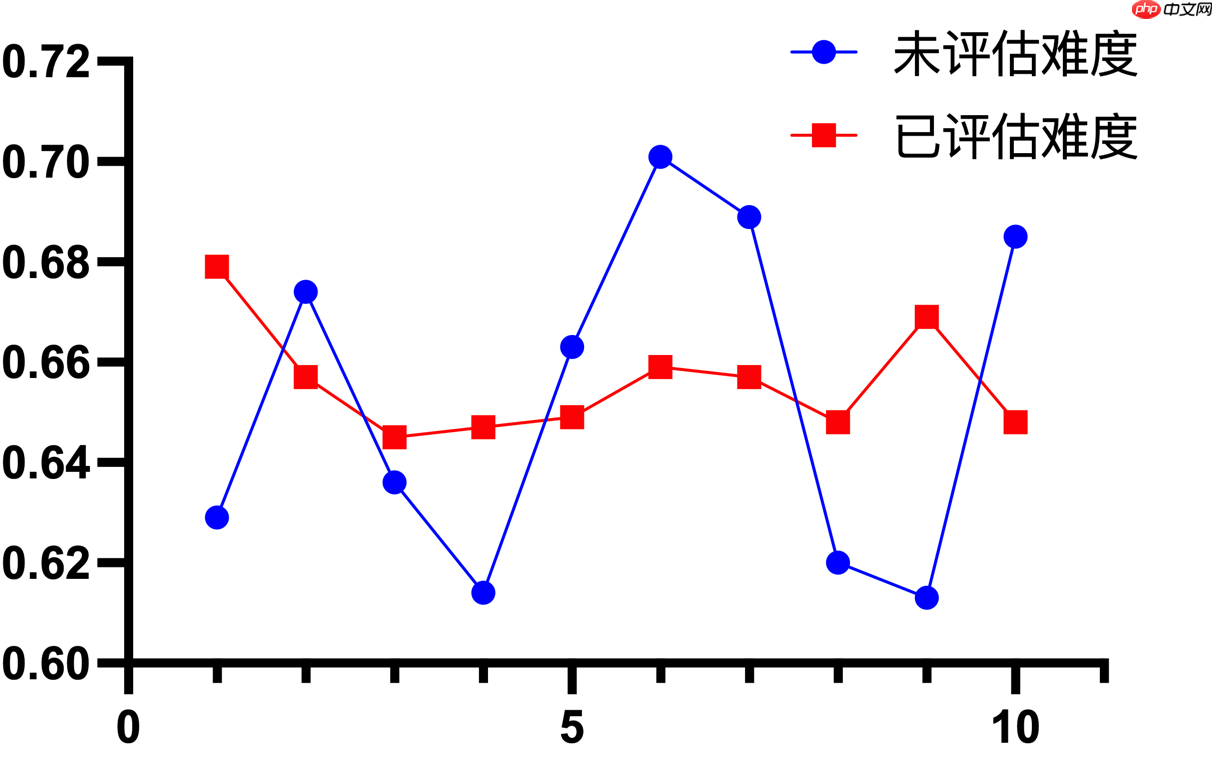
2.0.2 数据增强 & 数据清洗
首先考虑一些通用的文本增强手段,如下:
- 随机同义/近义词替换:不考虑停用词,在句子中随机抽取n个词,然后从同义/近义词词典中随机抽取同义/近义词,并进行替换;
- 随机字删除:句子中的每个词,以概率 p 随机删除,数字、时间不会删除;
- 随机邻近字置换:一定范围内将原句子乱序;
- 等价字替换:如句子中 1、一、壹、① 之间的相互替换;
- 回译:借助百度垂直领域翻译的 API,对原始文本进行中->英->中的翻译。
另外,由于本赛题包括两个任务,NER 任务提供了命名实体的标注结果,因此,为了引入更多的信息,我们设计了一个 NER 实体随机替换的数据增强方式,具体方法如下:
已有的标注标签包括“银行”、“产品”、“评论-名词” 和 “评论-形容词”,考虑到情感分类任务的特点,我们选择对 “银行” 和 “产品” 两种实体进行提取,之后对每条数据的这两种实体以一定概率随机替换,从而得到增强后的样本。
通过对数据观察,由于是评论内容,其中口语化较严重,因此需要对数据进行清洗后再输入模型。首先去除数据的空白字符及首尾标点等多余信息,然后考虑到该数据来自于银行产品评论,对数字比较敏感,因此将 “13K”、“25W” 等数字别名转换成统一格式,方便模型识别,最后,由于数据均为中文,我们还将英文标点全部转换成了中文标点。
上表是使用数据清洗和数据增强后的模型表现效果,首先可以看到数据清洗可以在保证模型稳定性的基础上将分数提升 2 个百分点,因此之后的数据增强实验都是在数据清洗的基础上进行的。
基于表中的实验结果,数据清洗 + 随机邻近字置换 + 标注实体随机替换可以在大幅提升分数的同时,保证模型更好的稳定性。需要注意的是,将两个效果较好的数据增强方案结合后,整体的分数及稳定性都产生了下滑,因此,并不是数据增强越多越好,需要根据实现结果进行合理选择。
2.0.3 评估指标:Kappa 系数
分类问题中,最常见的评价指标是 Acc,它能够直接反映分正确的比例,同时计算非常简单。但是实际的分类问题种,各个类别的样本数量往往不太平衡。在这种不平衡数据集上如不加以调整,模型很容易偏向大类别而放弃小类别(eg:正负样本比例 1:9,直接全部预测为负,Acc 也有 90%。但正样本就完全被 “抛弃” 了)。此时整体 Acc 很高,但是部分类别完全不能被召回。
这时需要一种能够惩罚模型的 “偏向性” 的指标来代替 Acc。而根据 Kappa 的计算公式,越不平衡的混淆矩阵,p_e 越高,Kappa 值就越低,正好能够给 “偏向性” 强的模型打低分。
分别使用 Kappa 系数和 Acc 作为评估指标的训练曲线如下所示。
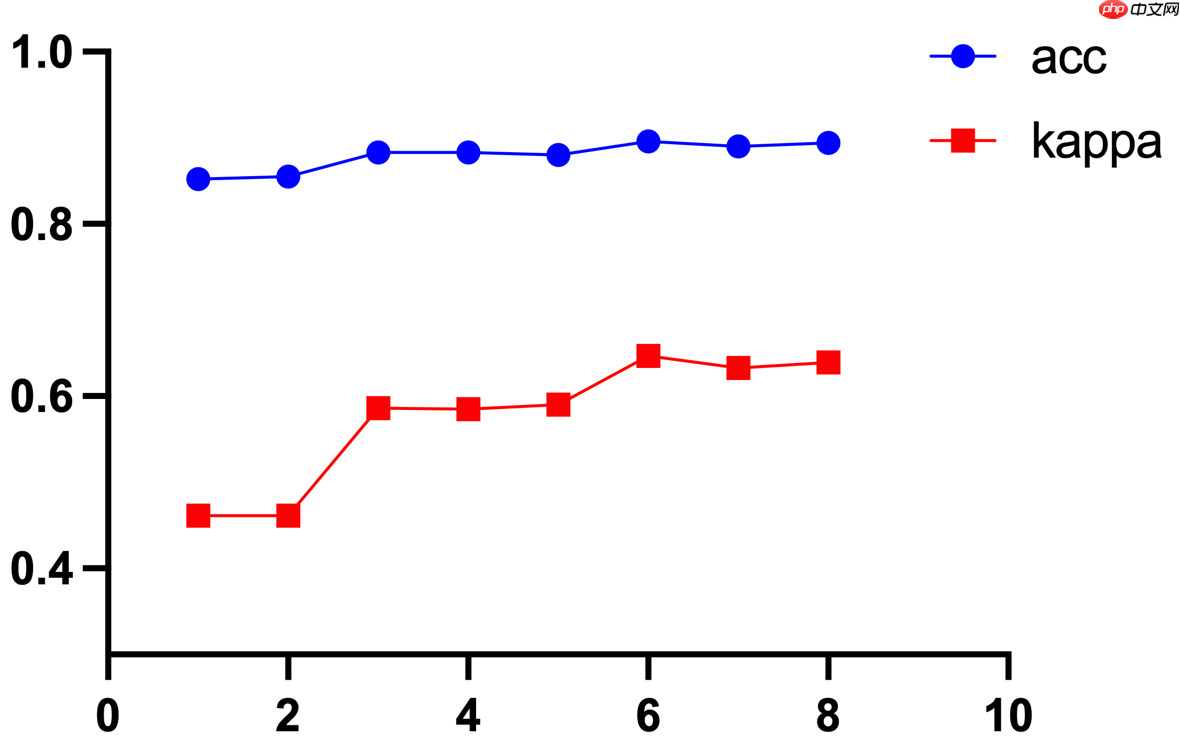
可以看到,Acc 整体变化远不如 Kappa 系数更加明显,因此选择 Kappa 系数作为评估指标更加合理,可以帮助我们更准确的选择最佳模型。
2.0.4 损失函数:Focal Loss
Focal Loss 可以认为是交叉熵损失的延伸,它的原理是使容易分类的样本权重降低,而对难分类的样本权重增加。
下图是同一模型下使用交叉熵损失函数和 Focal Loss 损失函数进行训练的迭代曲线,可以看到虽然 Focal Loss 对于模型准确率提升并不是很大,但是能够很好地提升训练的稳定性。
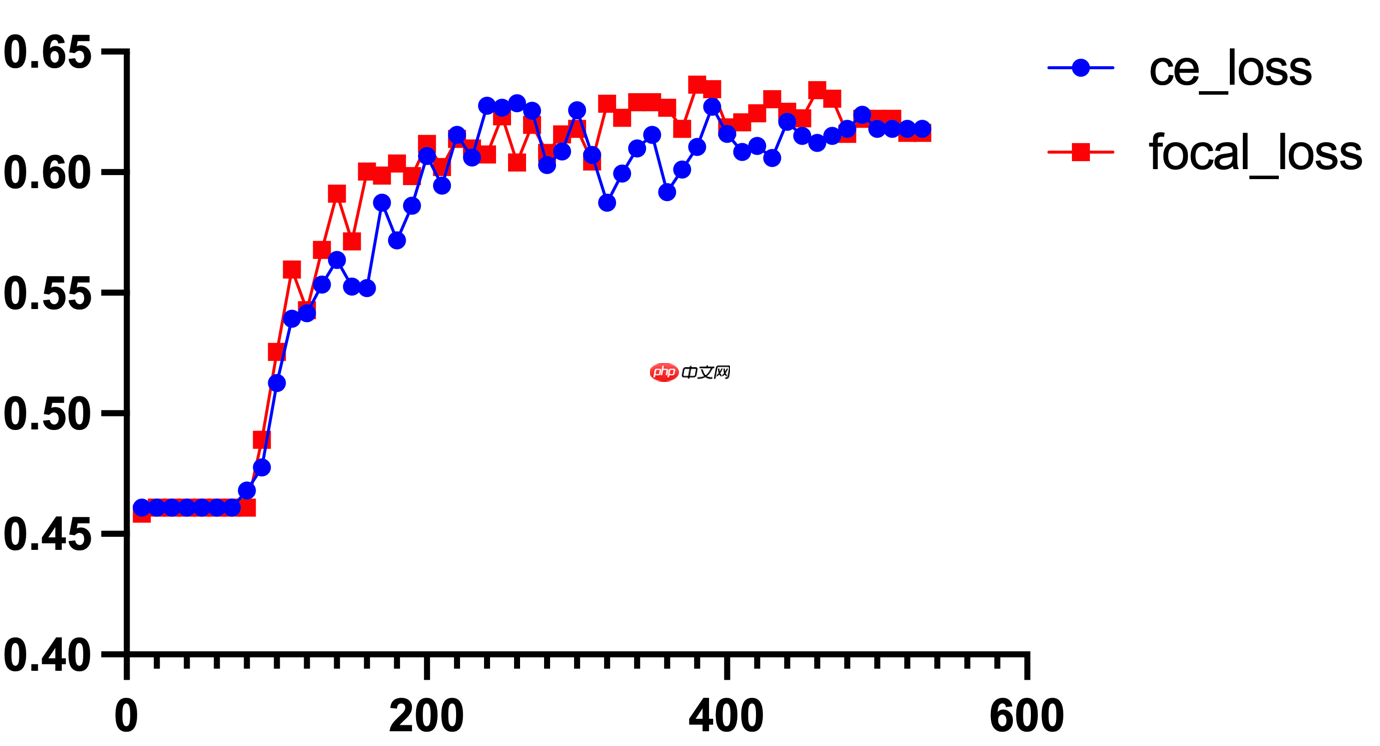
2.0.5 模型结构
这里我们设计了两种 BERT 的改进结构。
第一种改进结构我们称之为 BERT-hidden-fusion,其原理就是将隐藏层表示进行动态融合。具体做法为首先提取 BERT 的 12 层 Transformer 输出的 CLS 向量,之后为它们赋予一个初始权重,而后通过训练来确定权重值,并将每一层生成的表示加权平均,得到最终的文本向量表示。具体模型结构如下:
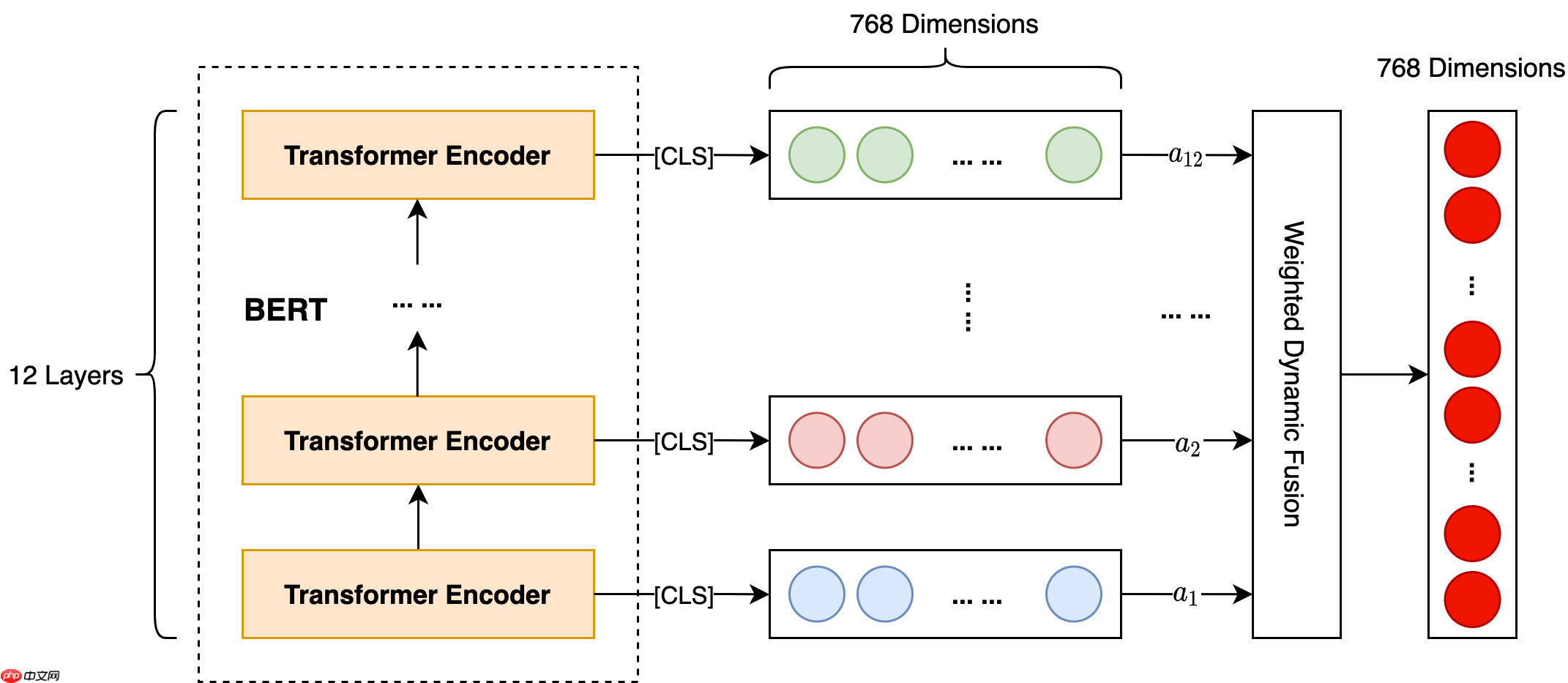
第二种改进结构我们称之为 BERT-CLS-mean-max,其原理就是为了充分利用最后一层的输出结果,将 CLS 向量与 Seq 的均值和最大值进行动态融合。具体模型结构如下:
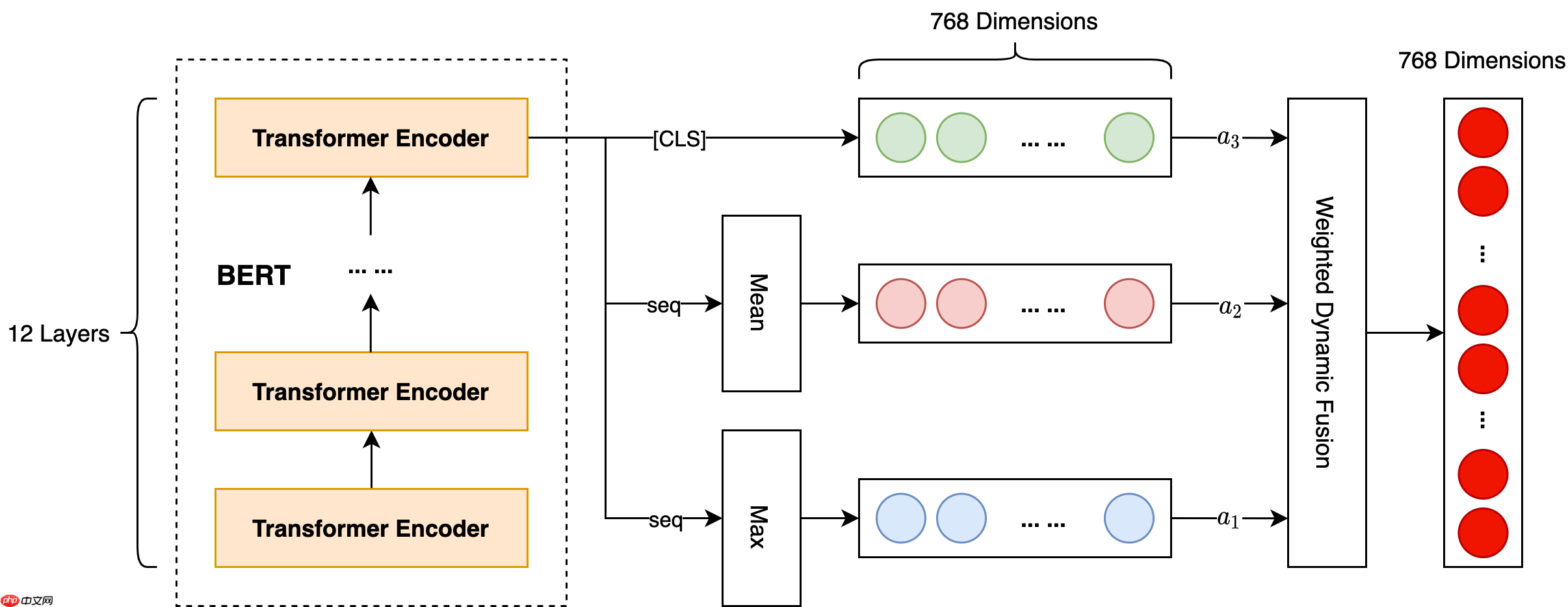
模型对比结果如下表:
可以看到,我们针对 BERT 改进的两种模型,最终得分都在一定程度上有所提升。
2.0.6 对抗训练
这里我们选择 FGM 进行对抗训练。对已有的三个模型增加对抗训练后的对比结果如下表:
可以看到,对抗训练是有效的,在原有的分数基础上都提升了至少一个百分点,尤其对于 BERT-hidden-fusion 提升了接近两个百分点。
2.0.7 总结
最终排名为 A 榜:47 / 363(13 %),B 榜:55 / 370(15 %)。
由于时间原因,上面大部分实验方案都是在赛后尝试的,经线下验证,我们线上采用的方案与上述最佳方案相差 5 个百分点(未基于训练难度划分数据集、未尝试数据增强方案、未进行对抗训练),在增加线上打分权重后,应该可以提升 1 到 2 个百分点。
各方案训练日志、部分模型 checkpoints 等实验相关文件可在?数据下载?中查看。
2.1 配置文件
config/data_fountain_529_senta.json
{ ”exp_name“: ”data_fountain_529_senta“, // 任务标识 ”train_filename“: ”train_data_public.csv“, // 训练数据原始文件 ”test_filename“: ”test_public.csv“, // 测试数据原始文件 ”num_classes“: 3, // 分类数量 // 模型参数配置 ”model_config“: { ”bert_baseline“: { ”max_seq_len“: 200, ”hidden_dropout_prob“: 0.5 }, ”bert_base“: { ”max_seq_len“: 200, ”hidden_dropout_prob“: 0.5 }, ”bert_hidden_fusion“: { ”max_seq_len“: 200, ”hidden_dropout_prob“: 0.3 }, ”bert_cls_seq_mean_max“: { ”max_seq_len“: 200, ”hidden_dropout_prob“: 0.5 } }, // 训练配置 ”train“: { ”model_name“: ”bert_hidden_fusion“, // 模型名称(与 model_config 匹配) ”batch_size“: 128, // 训练批大小 ”epochs“: 200, // 训练轮次 ”learning_rate“: 1e-5, // 学习率 ”loss_func“: ”focal_loss“, // 损失函数 ”adversarial“: ”fgm“, // 对抗训练方法 // 数据预处理方法 ”data_process“: { ”enable_text_clean“: true, // 是否开启文本清洗 // 数据增强方法 ”data_augmentation“: { ”random_delete_char_options“: { // 随机字删除参数 ”create_num“: 2, ”change_rate“: 0.1 }, ”ner_labeled_entity_options“: { // 基于 NER 标注的实体替换参数 ”create_num“: 3, ”change_prop“: 0.5, ”ner_labeled_entity_file_path“: ”/home/aistudio/work/entity.json“ } }, // 数据集划分配置(基于模型预测打分) ”data_split_options“: { ”model_name“: ”bert_baseline“, ”model_params_path“: ”/home/aistudio/work/checkpoints/baseline/model.pdparams“ } }, ”k_fold“: 10, // K 折交叉验证 ”random_state“: 2021, // 随机种子 // Baseline 配置 ”baseline“: { ”model_name“: ”bert_baseline“, ”loss_func“: ”ce_loss“, ”adversarial“: ”“, ”data_process“: { ”enable_text_clean“: false, ”data_augmentation“: {}, ”data_split_options“: {} }, ”k_fold“: 0, ”dev_prop“: 0.2 } }, // 预测配置 ”predict“: { ”batch_size“: 8, ”base_path“: ”/home/aistudio/work/checkpoints“, // 模型融合权重 ”model_params“: { ”bert_base“: 0.69339421919, ”bert_hidden_fusion“: 0.69966576165, ”bert_cls_seq_mean_max“: 0.69421932573 }, ”data_process“: { ”enable_text_clean“: true }, ”k_fold“: 10 }}登录后复制
2.2 数据处理
data_process/data_fountain_529_senta.py
from dataset.data_fountain_529_senta import DataFountain529SentaDatasetfrom model.data_fountain_529_senta import get_model_and_tokenizerfrom infer.data_fountain_529_senta import DataFountain529SentaInferfrom sklearn.model_selection import StratifiedKFoldfrom dotmap import DotMapfrom utils.utils import mkdir_if_not_exist, md5from utils.config_utils import DATA_PATHfrom utils.nlp_da import NlpDAimport pandas as pdimport stringimport randomimport jsonimport csvimport osimport reclass DataFountain529SentaDataProcessor(object): def __init__(self, config: DotMap): self.config = config # 原始数据集路径 self.train_data_path = os.path.join(DATA_PATH, config.exp_name, config.train_filename) self.test_data_path = os.path.join(DATA_PATH, config.exp_name, config.test_filename) # 根据配置文件设置数据处理后的存储路径 self._set_processed_data_path(config) self.da_options = config.data_process.data_augmentation self.enable_text_clean = config.data_process.enable_text_clean self.sp_options = config.data_process.data_split_options self.enable_da = bool(self.da_options) self.enable_sp = bool(self.sp_options) # 数据集划分配置 self.k_fold = config.k_fold self.random_state = config.random_state self.dev_prop = config.dev_prop self.mode = config.mode self.logger = config.logger def _set_processed_data_path(self, config): data_process_config = config.data_process unique_dir_name = md5({**data_process_config.toDict(), **{”k_fold“: config.k_fold, ”random_state“: config.random_state, ”dev_prop“: config.dev_prop}}) # 数据难度评估结果存储路径 self.data_difficulty_assessment_path = os.path.join( DATA_PATH, config.exp_name, ”data_difficulty_assessment“, unique_dir_name ) mkdir_if_not_exist(self.data_difficulty_assessment_path) self.assessed_path = os.path.join(self.data_difficulty_assessment_path, ”assessed_data.csv“) self.data_difficulty_score_path = os.path.join( self.data_difficulty_assessment_path, ”data_difficulty_score.json“ ) # 数据增强路径 self.data_augmentation_path = os.path.join(DATA_PATH, config.exp_name, ”data_augmentation“, unique_dir_name) mkdir_if_not_exist(self.data_augmentation_path) self.da_train_data_path = os.path.join(self.data_augmentation_path, ”train.csv“) self.da_test_data_path = os.path.join(self.data_augmentation_path, ”test.csv“) # 处理后的数据集路径 self.processed_path = os.path.join(DATA_PATH, config.exp_name, ”processed“, unique_dir_name) mkdir_if_not_exist(self.processed_path) self.train_path = os.path.join(self.processed_path, ”train_{}.csv“) self.dev_path = os.path.join(self.processed_path, ”dev_{}.csv“) self.test_path = os.path.join(self.processed_path, ”test.csv“) # 补充配置信息 config.splits = { ”train“: self.train_path, ”dev“: self.dev_path, ”test“: self.test_path, ”assessed“: self.assessed_path, } def process(self): # 数据难度评估 if self.enable_sp: self._data_difficulty_assessment() # 数据增强 if self.enable_da: self._data_augmentation() # 训练集、开发集划分 if self.mode != ”predict“: self._train_dev_dataset_split() # 测试集保存 self._test_dataset_save() def _data_difficulty_assessment(self): # 相应文件都存在,跳过处理 if os.path.isfile(self.assessed_path) and os.path.isfile(self.data_difficulty_score_path): self.logger.info(”skip data difficulty assessment“) return # 待评估数据集保存 self._assessed_dataset_save() # 获取待评估数据集 [assessed_ds] = DataFountain529SentaDataset(self.config).load_data(splits=['assessed'], lazy=False) # 加载 model 和 tokenizer model, tokenizer, self.config = get_model_and_tokenizer(self.sp_options.model_name, self.config) # 获取推断器 model_params_path = self.sp_options.model_params_path infer = DataFountain529SentaInfer( model, tokenizer=tokenizer, test_ds=assessed_ds, config=self.config, model_params_path=model_params_path) # 开始预测 result = infer.predict() # 提取数据难度打分(预测概率,值越小难度越大) difficulty_score = {} df = pd.read_csv(self.assessed_path, encoding=”utf-8“) for qid, probs in result: label = df.loc[df[”id“] == qid].iloc[0][”label“] difficulty_score[qid] = probs[int(label)] # 保存数据难度打分 with open(self.data_difficulty_score_path, ”w“, encoding=”utf-8“) as score_f: json.dump(difficulty_score, score_f) def _assessed_dataset_save(self): df = pd.read_csv(self.train_data_path, encoding=”utf-8“) with open(self.assessed_path, ”w“, encoding=”utf-8“) as assessed_f: assessed_writer = csv.writer(assessed_f) assessed_writer.writerow([”id“, ”text“, ”label“]) rows = [] for idx, line in df.iterrows(): _id, text, label = line.get(”id“, ”“), line.get(”text“, ”“), line.get(”class“, ”“) rows.append([_id, text, label]) assessed_writer.writerows(rows) def _data_augmentation(self): # 相应文件都存在,跳过处理 if os.path.isfile(self.da_train_data_path) and os.path.isfile(self.da_test_data_path): self.logger.info(”skip data augmentation“) return # 数据增强对象 nlp_da = NlpDA(**self.da_options) # 训练数据 train_df = pd.read_csv(self.train_data_path, encoding=”utf-8“) with open(self.da_train_data_path, ”w“, encoding=”utf-8“) as train_f: train_writer = csv.writer(train_f) train_writer.writerow([”id“, ”text“, ”class“]) # 保持与原始数据一致 for idx, line in train_df.iterrows(): _id, text, label = line.get(”id“, ”“), line.get(”text“, ”“), line.get(”class“, ”“) bio = line.get(”BIO_anno“, ”“) for da_text in nlp_da.generate(text, {”bio“: bio}): train_writer.writerow([_id, da_text, label]) # 测试数据 test_df = pd.read_csv(self.test_data_path, encoding=”utf-8“) with open(self.da_test_data_path, ”w“, encoding=”utf-8“) as test_f: test_writer = csv.writer(test_f) test_writer.writerow([”id“, ”text“]) for idx, line in test_df.iterrows(): _id, text = line.get(”id“, ”“), line.get(”text“, ”“) bio = line.get(”BIO_anno“, ”“) for da_text in nlp_da.generate(text, {”bio“: bio}): test_writer.writerow([_id, da_text]) def _train_dev_dataset_split(self): df = pd.read_csv(self.train_data_path, encoding=”utf-8“) X, y = df.drop([”class“], axis=1), df[”class“] if self.enable_sp: def _get_difficulty_class(_class, _score): return int(”{}{}“.format(_class, int(_score * 10) // 3)) with open(self.data_difficulty_score_path, ”r“, encoding=”utf-8“) as difficulty_score_f: difficulty_score = json.load(difficulty_score_f) df[”difficulty_class“] = df.apply(lambda x: _get_difficulty_class( x[”class“], difficulty_score[str(x[”id“])] ), axis=1) X, y = df.drop([”difficulty_class“], axis=1), df[”difficulty_class“] da_df = pd.read_csv(self.da_train_data_path, encoding=”utf-8“) if self.enable_da else None k_fold = int(1 / self.dev_prop) if self.k_fold == 0 else self.k_fold skf = StratifiedKFold(n_splits=k_fold, shuffle=True, random_state=self.random_state).split(X, y) for k, (train_idx, dev_idx) in enumerate(skf): train_path = self.train_path.format(k) with open(train_path, ”w“, encoding=”utf-8“) as train_f: train_writer = csv.writer(train_f) train_writer.writerow([”text“, ”label“]) rows = [] for i in range(len(train_idx)): cur_X, cur_y = X.iloc[train_idx[i]], y.iloc[train_idx[i]] if self.enable_sp: cur_y = cur_X[”class“] if da_df is not None: da_texts = da_df.loc[da_df[”id“] == cur_X[”id“]][”text“].values.tolist() for da_text in da_texts: if self.enable_text_clean: da_text = self.text_clean(da_text) rows.append([da_text, cur_y]) else: text = cur_X[”text“] if self.enable_text_clean: text = self.text_clean(text) rows.append([text, cur_y]) random.shuffle(rows) train_writer.writerows(rows) dev_path = self.dev_path.format(k) with open(dev_path, ”w“, encoding=”utf-8“) as dev_f: dev_writer = csv.writer(dev_f) dev_writer.writerow([”text“, ”label“]) for i in range(len(dev_idx)): cur_X, cur_y = X.iloc[dev_idx[i]], y.iloc[dev_idx[i]] if self.enable_sp: cur_y = cur_X[”class“] text = cur_X[”text“] if self.enable_text_clean: text = self.text_clean(text) dev_writer.writerow([text, cur_y]) if self.k_fold == 0: break def _test_dataset_save(self): df = pd.read_csv(self.test_data_path, encoding=”utf-8“) da_df = pd.read_csv(self.da_test_data_path, encoding=”utf-8“) if self.enable_da and self.da_options.enable_tta else None with open(self.test_path, ”w“, encoding=”utf-8“) as test_f: test_writer = csv.writer(test_f) test_writer.writerow([”id“, ”text“]) rows = [] for idx, line in df.iterrows(): _id, text = line.get(”id“, ”“), line.get(”text“, ”“) if da_df is not None: da_texts = da_df.loc[da_df[”id“] == _id][”text“].values.tolist() for da_text in da_texts: if self.enable_text_clean: da_text = self.text_clean(da_text) rows.append([_id, da_text]) else: if self.enable_text_clean: text = self.text_clean(text) rows.append([_id, text]) test_writer.writerows(rows) @classmethod def text_clean(cls, text): # 去除空白字符及首尾标点 text = text.strip().strip(string.punctuation).replace(” “, ”“) # 去除数字内部的逗号 p = re.compile(r”d+,d+?“) for m in p.finditer(text): mm = m.group() text = text.replace(mm, mm.replace(”,“, ”“)) # 去除数字小数点 p = re.compile(r”d+.d+“) for m in p.finditer(text): mm = m.group() text = text.replace(mm, mm[0:mm.find(”.“)]) # 数字转换 k、K -> 千,w、W -> 万 p = re.compile(r”d+[kKK千]?“) for m in p.finditer(text): mm = m.group() text = text.replace(mm, mm.replace(”k“, ”000“).replace(”K“, ”000“).replace(”千“, ”000“)) p = re.compile(r”d+[wWW万]?“) for m in p.finditer(text): mm = m.group() text = text.replace(mm, mm.replace(”w“, ”0000“).replace(”W“, ”0000“).replace(”万“, ”0000“)) # 英文标点转中文标点 e_pun = u',.!?%[]()<>”'' c_pun = u',。!?%【】()《》“‘' table = {ord(f): ord(t) for f, t in zip(e_pun, c_pun)} text = text.translate(table) return text登录后复制
2.3 数据集构建
dataset/data_fountain_529_senta.py
from paddlenlp.datasets import load_datasetfrom dotmap import DotMapimport pandas as pdclass DataFountain529SentaDataset(object): “”“ df-529 情感分类数据集(1:正面,0:负面,2:中立) ”“” def __init__(self, config: DotMap): super().__init__() self.config = config def load_data(self, fold=0, splits=None, lazy=None): result = [] for split in splits: path = self.config.splits.get(split).format(fold) ds = load_dataset(self.read, data_path=path, lazy=lazy) result.append(ds) return result @staticmethod def read(data_path): df = pd.read_csv(data_path, encoding=“utf-8”) for idx, line in df.iterrows(): text, label, qid = line.get(“text”, “”), line.get(“label”, “”), line.get(“id”, “”) yield {“text”: text, “label”: label, “qid”: qid}登录后复制
2.4 模型搭建
model/data_fountain_529_senta.py
from paddlenlp.transformers import BertTokenizer, BertForSequenceClassification, BertPretrainedModelfrom dotmap import DotMapimport paddledef get_model_and_tokenizer(model_name: str, config: DotMap): config = DotMap({**config.toDict(), **config.model_config[model_name].toDict()}) if model_name in [“bert_base”, “bert_baseline”]: model = BertForSequenceClassification.from_pretrained(“bert-base-chinese”, num_classes=config.num_classes, dropout=config.hidden_dropout_prob) tokenizer = BertTokenizer.from_pretrained(“bert-base-chinese”) elif model_name == “bert_hidden_fusion”: model = DataFountain529SentaBertHiddenFusionModel.from_pretrained(“bert-base-chinese”, config=config) tokenizer = BertTokenizer.from_pretrained(“bert-base-chinese”) elif model_name == “bert_cls_seq_mean_max”: model = DataFountain529SentaBertClsSeqMeanMaxModel.from_pretrained(“bert-base-chinese”, config=config) tokenizer = BertTokenizer.from_pretrained(“bert-base-chinese”) else: raise RuntimeError(“load model error: {}.”.format(model_name)) return model, tokenizer, configclass DataFountain529SentaBertHiddenFusionModel(BertPretrainedModel): “”“ Bert 隐藏层向量动态融合 ”“” def __init__(self, bert, config: DotMap): super(DataFountain529SentaBertHiddenFusionModel, self).__init__() self.bert = bert self.dropout = paddle.nn.Dropout(config.hidden_dropout_prob) self.classifier = paddle.nn.layer.Linear(768, config.num_classes) self.layer_weights = self.create_parameter(shape=(12, 1, 1), default_initializer=paddle.nn.initializer.Constant(1.0)) self.apply(self.init_weights) def forward(self, input_ids, token_type_ids): encoder_outputs, _ = self.bert(input_ids, token_type_ids=token_type_ids, output_hidden_states=True) stacked_encoder_outputs = paddle.stack(encoder_outputs, axis=0) all_layer_cls_embedding = stacked_encoder_outputs[:, :, 0, :] weighted_average = (self.layer_weights * all_layer_cls_embedding).sum(axis=0) / self.layer_weights.sum() pooled_output = self.dropout(weighted_average) logits = self.classifier(pooled_output) return logitsclass DataFountain529SentaBertClsSeqMeanMaxModel(BertPretrainedModel): “”“ Bert:最后一层 pooled_output 与 Seq Mean、Max 动态融合 ”“” def __init__(self, bert, config: DotMap): super(DataFountain529SentaBertClsSeqMeanMaxModel, self).__init__() self.bert = bert self.dropout = paddle.nn.Dropout(config.hidden_dropout_prob) self.classifier = paddle.nn.layer.Linear(768, config.num_classes) self.layer_weights = self.create_parameter(shape=(3, 1, 1), default_initializer=paddle.nn.initializer.Constant(1.0)) self.apply(self.init_weights) def forward(self, input_ids, token_type_ids): encoder_outputs, pooled_output = self.bert(input_ids, token_type_ids=token_type_ids, output_hidden_states=True) seq_embeddings = encoder_outputs[-1][:, 1:] mean_seq_embedding = seq_embeddings.mean(axis=1) max_seq_embedding = seq_embeddings.max(axis=1) stacked_outputs = paddle.stack([pooled_output, mean_seq_embedding, max_seq_embedding], axis=0) weighted_average = (self.layer_weights * stacked_outputs).sum(axis=0) / self.layer_weights.sum() pooled_output = self.dropout(weighted_average) logits = self.classifier(pooled_output) return logits登录后复制
2.5 训练器定义
trainer/data_fountain_529_senta.py
from paddlenlp.transformers import PretrainedTokenizer, LinearDecayWithWarmupfrom paddlenlp.datasets import MapDatasetfrom paddlenlp.data import Stack, Tuple, Padfrom paddle import nnfrom dotmap import DotMapfrom functools import partialfrom visualdl import LogWriterfrom utils.utils import create_data_loader, mkdir_if_not_existfrom utils.metric import Kappafrom utils.loss import FocalLossfrom utils.adversarial import FGMimport paddle.nn.functional as Fimport numpy as npimport timeimport paddleimport osclass DataFountain529SentaTrainer(object): train_data_loader = None dev_data_loader = None epochs = None ckpt_dir = None num_training_steps = None optimizer = None criterion = None metric = None def __init__(self, model: nn.Layer, tokenizer: PretrainedTokenizer, train_ds: MapDataset, dev_ds: MapDataset, config: DotMap): if config.model_name not in config.model_config: raise RuntimeError(“current model: {} not configured”.format(config.model_name)) self.model = model self.tokenizer = tokenizer self.train_ds = train_ds self.dev_ds = dev_ds self.logger = config.logger self.config = config self._gen_data_loader(config) self._prepare(config) def _gen_data_loader(self, config: DotMap): # 将数据处理成模型可读入的数据格式 trans_func = partial( self.convert_example, tokenizer=self.tokenizer, max_seq_len=config.max_seq_len) # 将数据组成批量式数据,如 # 将不同长度的文本序列 padding 到批量式数据中最大长度 # 将每条数据 label 堆叠在一起 batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # input_ids Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id), # token_type_ids Stack() # labels ): [data for data in fn(samples)] self.train_data_loader = create_data_loader( self.train_ds, trans_fn=trans_func, mode='train', batch_size=config.batch_size, batchify_fn=batchify_fn) self.dev_data_loader = create_data_loader( self.dev_ds, trans_fn=trans_func, mode='dev', batch_size=config.batch_size, batchify_fn=batchify_fn) def _prepare(self, config: DotMap): # 当前训练折次 self.fold = config.fold # 训练折数 self.total_fold = config.k_fold or 1 # 训练轮次 self.epochs = config.epochs # 保存模型参数的文件夹 self.ckpt_dir = os.path.join(config.ckpt_dir, config.model_name, “fold_{}”.format(self.fold)) mkdir_if_not_exist(self.ckpt_dir) # 可视化日志的文件夹 self.train_vis_dir = os.path.join(config.vis_dir, config.model_name, “fold_{}/train”.format(self.fold)) self.dev_vis_dir = os.path.join(config.vis_dir, config.model_name, “fold_{}/dev”.format(self.fold)) mkdir_if_not_exist(self.train_vis_dir) mkdir_if_not_exist(self.dev_vis_dir) # 训练所需要的总 step 数 self.num_training_steps = len(self.train_data_loader) * self.epochs # 定义 learning_rate_scheduler,负责在训练过程中对 lr 进行调度 self.lr_scheduler = LinearDecayWithWarmup(config.learning_rate, self.num_training_steps, 0.0) # Generate parameter names needed to perform weight decay. # All bias and LayerNorm parameters are excluded. decay_params = [ p.name for n, p in self.model.named_parameters() if not any(nd in n for nd in [“bias”, “norm”]) ] # 定义 Optimizer self.optimizer = paddle.optimizer.AdamW( learning_rate=self.lr_scheduler, parameters=self.model.parameters(), weight_decay=0.0, apply_decay_param_fun=lambda x: x in decay_params) self.enable_adversarial = False if config.adversarial: self.enable_adversarial = True if config.adversarial == “fgm”: self.adv = FGM(self.model, epsilon=1e-5, emb_name=“word_embeddings”) else: raise RuntimeError(“config error adversarial: {}”.format(config.adversarial)) if config.loss_func == “ce_loss”: # 交叉熵损失函数 self.criterion = paddle.nn.loss.CrossEntropyLoss() self.eval_criterion = paddle.nn.loss.CrossEntropyLoss() self.adv_criterion = paddle.nn.loss.CrossEntropyLoss() elif config.loss_func == “focal_loss”: # Focal Loss self.criterion = FocalLoss(num_classes=config.num_classes) self.eval_criterion = FocalLoss(num_classes=config.num_classes) self.adv_criterion = FocalLoss(num_classes=config.num_classes) elif config.loss_func == “focal_loss-gamma3”: # Focal Loss (gamma = 3) self.criterion = FocalLoss(num_classes=config.num_classes, gamma=3) self.eval_criterion = FocalLoss(num_classes=config.num_classes, gamma=3) self.adv_criterion = FocalLoss(num_classes=config.num_classes, gamma=3) elif config.loss_func == “focal_loss-gamma5”: # Focal Loss (gamma = 5) self.criterion = FocalLoss(num_classes=config.num_classes, gamma=5) self.eval_criterion = FocalLoss(num_classes=config.num_classes, gamma=5) self.adv_criterion = FocalLoss(num_classes=config.num_classes, gamma=5) else: raise RuntimeError(“config error loss function: {}”.format(config.loss_func)) # Kappa 评价指标 self.metric = Kappa(config.num_classes) self.eval_metric = Kappa(config.num_classes) # Acc 评价指标 self.acc_metric = paddle.metric.Accuracy() self.eval_acc_metric = paddle.metric.Accuracy() def train(self): # 开启训练 global_step = 0 tic_train = time.time() with LogWriter(logdir=self.train_vis_dir) as train_writer: with LogWriter(logdir=self.dev_vis_dir) as dev_writer: for epoch in range(1, self.epochs + 1): for step, batch in enumerate(self.train_data_loader, start=1): input_ids, token_type_ids, labels = batch # 喂数据给 model logits = self.model(input_ids, token_type_ids) # 计算损失函数值 loss = self.criterion(logits, labels) # 反向梯度回传,更新参数 loss.backward() # 预测分类概率值 probs = F.softmax(logits, axis=1) preds = paddle.argmax(probs, axis=1, keepdim=True) # 计算 kappa self.metric.update(preds, labels) kappa = self.metric.accumulate() # 计算 acc correct = self.acc_metric.compute(probs, labels) self.acc_metric.update(correct) acc = self.acc_metric.accumulate() global_step += 1 self.logger.info( “「%d/%d」global step %d, epoch: %d, batch: %d, loss: %.5f, kappa: %.5f, acc: %.5f, speed: %.2f step/s” % (self.fold, self.total_fold - 1, global_step, epoch, step, loss, kappa, acc, 1 / (time.time() - tic_train))) tic_train = time.time() train_writer.add_scalar(tag=“kappa”, step=global_step, value=kappa) train_writer.add_scalar(tag=“acc”, step=global_step, value=acc) train_writer.add_scalar(tag=“loss”, step=global_step, value=loss) # 对抗训练 if self.enable_adversarial: self.adv.attack() # 在 embedding 上添加对抗扰动 adv_logits = self.model(input_ids, token_type_ids) adv_loss = self.adv_criterion(adv_logits, labels) adv_loss.backward() # 反向传播,并在正常的 grad 基础上,累加对抗训练的梯度 self.adv.restore() # 恢复 embedding 参数 self.optimizer.step() self.lr_scheduler.step() self.optimizer.clear_grad() if global_step % 10 == 0 or global_step == self.num_training_steps: # 评估当前训练的模型 loss_dev, kappa_dev, acc_dev = self.evaluate() dev_writer.add_scalar(tag=“kappa”, step=global_step, value=kappa_dev) dev_writer.add_scalar(tag=“acc”, step=global_step, value=acc_dev) dev_writer.add_scalar(tag=“loss”, step=global_step, value=loss_dev) # # 保存当前模型参数等 # if global_step >= 100: # save_dir = os.path.join(self.ckpt_dir, “model_%d” % global_step) # mkdir_if_not_exist(save_dir) # paddle.save(self.model.state_dict(), os.path.join(save_dir, “model.pdparams”)) @staticmethod def convert_example(example, tokenizer, max_seq_len=512): encoded_inputs = tokenizer(text=example[“text”], max_seq_len=max_seq_len, pad_to_max_seq_len=True) return tuple([np.array(x, dtype=“int64”) for x in [ encoded_inputs[“input_ids”], encoded_inputs[“token_type_ids”], [example[“label”]]]]) @paddle.no_grad() def evaluate(self): self.model.eval() self.eval_metric.reset() self.eval_acc_metric.reset() losses, kappa, acc = [], 0.0, 0.0 for batch in self.dev_data_loader: input_ids, token_type_ids, labels = batch logits = self.model(input_ids, token_type_ids) loss = self.eval_criterion(logits, labels) losses.append(loss.numpy()) probs = F.softmax(logits, axis=1) preds = paddle.argmax(probs, axis=1, keepdim=True) self.eval_metric.update(preds, labels) kappa = self.eval_metric.accumulate() correct = self.eval_acc_metric.compute(probs, labels) self.eval_acc_metric.update(correct) acc = self.eval_acc_metric.accumulate() self.logger.info(“「%d/%d」eval loss: %.5f, kappa: %.5f, acc: %.5f” % (self.fold, self.total_fold - 1, float(np.mean(losses)), kappa, acc)) self.model.train() self.eval_metric.reset() self.eval_acc_metric.reset() return float(np.mean(losses)), kappa, acc登录后复制
2.6 开始训练
run/data_fountain_529_senta/train.py
from data_process.data_fountain_529_senta import DataFountain529SentaDataProcessorfrom dataset.data_fountain_529_senta import DataFountain529SentaDatasetfrom model.data_fountain_529_senta import get_model_and_tokenizerfrom trainer.data_fountain_529_senta import DataFountain529SentaTrainerfrom utils.config_utils import get_config, CONFIG_PATHfrom dotmap import DotMapimport argparseimport osdef train(opt): config = get_config(os.path.join(CONFIG_PATH, “data_fountain_529_senta.json”), “train”) # baseline 配置重写 if opt.baseline: config = DotMap({**config.toDict(), **config.baseline.toDict()}) # 原始数据预处理 data_processor = DataFountain529SentaDataProcessor(config) data_processor.process() folds = [0] if config.k_fold == 0 else range(config.k_fold) for fold in folds: config.fold = fold # 获取训练集、开发集 train_ds, dev_ds = DataFountain529SentaDataset(config).load_data( fold=config.fold, splits=['train', 'dev'], lazy=False ) # 加载 model 和 tokenizer model, tokenizer, config = get_model_and_tokenizer(config.model_name, config) # 获取训练器 trainer = DataFountain529SentaTrainer( model=model, tokenizer=tokenizer, train_ds=train_ds, dev_ds=dev_ds, config=config ) # 开始训练 trainer.train()if __name__ == “__main__”: parser = argparse.ArgumentParser() parser.add_argument('--baseline', nargs='?', const=True, default=False, help='start baseline training') train(parser.parse_args())登录后复制
2.7 推断器定义
infer/data_fountain_529_senta.py
from paddlenlp.transformers import PretrainedTokenizerfrom paddlenlp.datasets import MapDatasetfrom paddlenlp.data import Stack, Tuple, Padfrom paddle import nnfrom dotmap import DotMapfrom functools import partialfrom utils.utils import create_data_loaderimport paddle.nn.functional as Fimport numpy as npimport paddleclass DataFountain529SentaInfer(object): def __init__(self, model: nn.Layer, tokenizer: PretrainedTokenizer, test_ds: MapDataset, config: DotMap, model_params_path: str): self.model = model self.tokenizer = tokenizer self.test_ds = test_ds self.logger = config.logger self.config = config self._gen_data_loader(config) self._load_model(model_params_path) def _gen_data_loader(self, config: DotMap): # 将数据处理成模型可读入的数据格式 trans_func = partial( self.convert_example, tokenizer=self.tokenizer, max_seq_len=config.max_seq_len) batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # input_ids Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id), # token_type_ids Stack() # qid ): [data for data in fn(samples)] self.test_data_loader = create_data_loader( self.test_ds, mode='test', batch_size=config.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func) def _load_model(self, model_params_path): try: # 加载模型参数 state_dict = paddle.load(model_params_path) self.model.set_dict(state_dict) self.logger.info(“Loaded parameters from {}”.format(model_params_path)) except Exception as e: raise RuntimeError(“Loaded parameters error from {}: {}”.format(model_params_path, e)) @paddle.no_grad() def predict(self): result = [] # 切换 model 模型为评估模式,关闭 dropout 等随机因素 self.model.eval() for step, batch in enumerate(self.test_data_loader, start=1): input_ids, token_type_ids, qids = batch # 喂数据给 model logits = self.model(input_ids, token_type_ids) # 预测分类 probs = F.softmax(logits, axis=-1) qids = qids.flatten().numpy().tolist() probs = probs.numpy().tolist() result.extend(zip(qids, probs)) return result @staticmethod def convert_example(example, tokenizer, max_seq_len=512): encoded_inputs = tokenizer(text=example[“text”], max_seq_len=max_seq_len, pad_to_max_seq_len=True) return tuple([np.array(x, dtype=“int64”) for x in [ encoded_inputs[“input_ids”], encoded_inputs[“token_type_ids”], [example[“qid”]]]])登录后复制
2.8 开始预测
run/data_fountain_529_senta/predict.py
from data_process.data_fountain_529_senta import DataFountain529SentaDataProcessorfrom dataset.data_fountain_529_senta import DataFountain529SentaDatasetfrom model.data_fountain_529_senta import get_model_and_tokenizerfrom infer.data_fountain_529_senta import DataFountain529SentaInferfrom utils.config_utils import get_config, CONFIG_PATHfrom dotmap import DotMapimport numpy as npimport csvimport osdef predict(): config = get_config(os.path.join(CONFIG_PATH, “data_fountain_529_senta.json”), “predict”) # 原始数据预处理 data_processor = DataFountain529SentaDataProcessor(config) data_processor.process() # 使用配置中的所有模型进行融合 fusion_result = [] for model_name, weight in config.model_params.items(): # 计算单模型 K 折交叉验证的结果 k_fold_result = [] for fold in range(config.k_fold or 1): model_path = os.path.join(config.base_path, model_name, 'model_{}.pdparams'.format(fold)) fold_result = single_model_predict(config, model_name, model_path) k_fold_result.append(fold_result) # 融合 k 折模型的预测结果 merge_result = merge_k_fold_result(k_fold_result) # 将当前模型及对应权重保存 fusion_result.append([merge_result, weight]) # 融合所有模型的预测结果 result = merge_fusion_result(fusion_result) # 写入预测结果 with open(os.path.join(config.base_path, “result.csv”), “w”, encoding=“utf-8”) as f: writer = csv.writer(f) writer.writerow([“id”, “class”]) for line in result: qid, label = line writer.writerow([qid, label])def merge_fusion_result(fusion_result): merge_result = {} for single_result, weight in fusion_result: for line in single_result: qid, label = line[0], line[1] if qid not in merge_result: merge_result[qid] = [0.] * 3 merge_result[qid][label] += 1. * weight merge_result = sorted(merge_result.items(), key=lambda x: x[0], reverse=False) result = [] for line in merge_result: qid, scores = line[0], line[1] label = np.argmax(scores) result.append([qid, label]) return resultdef single_model_predict(config: DotMap, model_name: str, model_path: str): # 获取测试集 [test_ds] = DataFountain529SentaDataset(config).load_data(splits=['test'], lazy=False) # 加载 model 和 tokenizer model, tokenizer, config = get_model_and_tokenizer(model_name, config) # 获取推断器 infer = DataFountain529SentaInfer(model, tokenizer=tokenizer, test_ds=test_ds, config=config, model_params_path=model_path) # 开始预测 result = infer.predict() # 合并 TTA 后的结果 result = merge_tta_result(result) return resultdef merge_tta_result(tta_result): tta = {} for record in tta_result: qid, probs = record[0], record[1] if qid not in tta: tta[qid] = {'probs': [0.] * 3, 'num': 0} tta[qid]['probs'] = np.sum([tta[qid]['probs'], probs], axis=0) tta[qid]['num'] += 1 result = [] for qid, sum_probs in tta.items(): probs = np.divide(sum_probs['probs'], sum_probs['num']).tolist() result.append([qid, probs]) return resultdef merge_k_fold_result(k_fold_result): merge_result = {} for fold_result in k_fold_result: for line in fold_result: qid, probs = line[0], line[1] if qid not in merge_result: merge_result[qid] = [0.] * 3 merge_result[qid] = np.sum([merge_result[qid], probs], axis=0) merge_result = sorted(merge_result.items(), key=lambda x: x[0], reverse=False) result = [] for line in merge_result: qid, probs = line[0], line[1] label = np.argmax(probs) result.append([qid, label]) return resultif __name__ == “__main__”: predict()登录后复制
三、命名实体识别部分
3.0 方案介绍
3.0.1 模型选择
3.0.2 总结
最终排名为 A 榜:47 / 363(13 %),B 榜:55 / 370(15 %)。
各方案训练日志、部分模型 checkpoints 等实验相关文件可在?数据下载?中查看。
3.1 配置文件
config/data_fountain_529_ner.json
{ “exp_name”: “data_fountain_529_ner”, “train_filename”: “train_data_public.csv”, “test_filename”: “test_public.csv”, “model_config”: { “bert_base”: { “max_seq_len”: 200 }, “bert_crf”: { “max_seq_len”: 200 }, “ernie_base”: { “max_seq_len”: 200 }, “ernie_crf”: { “max_seq_len”: 200 } }, “train”: { “model_name”: “bert_crf”, “loss_func”: “ce_loss”, “batch_size”: 64, “epochs”: 10, “learning_rate”: 2e-5, “adam_epsilon”: 1e-8, “k_fold”: 10, “random_state”: 2021, “dev_prop”: 0.2 }, “predict”: { “batch_size”: 8, “base_path”: “/home/aistudio/work/checkpoints”, “model_params”: { “bert_base”: 1.0, “bert_crf”: 1.0, “ernie_base”: 1.0, “ernie_crf”: 1.0 }, “k_fold”: 10 }}登录后复制
3.2 数据处理
data_process/data_fountain_529_ner.py
from sklearn.model_selection import KFoldfrom dotmap import DotMapfrom utils.utils import mkdir_if_not_exist, md5from utils.config_utils import DATA_PATHimport pandas as pdimport csvimport osclass DataFountain529NerDataProcessor(object): def __init__(self, config: DotMap): self.config = config # 原始数据集路径 self.train_data_path = os.path.join(DATA_PATH, self.config.exp_name, self.config.train_filename) self.test_data_path = os.path.join(DATA_PATH, self.config.exp_name, self.config.test_filename) # 根据配置文件设置数据处理后的存储路径 self._set_processed_data_path(config) # 数据集划分配置 self.k_fold = config.k_fold self.random_state = config.random_state self.dev_prop = config.dev_prop self.mode = config.mode self.logger = config.logger def _set_processed_data_path(self, config): data_process_config = config.data_process unique_dir_name = md5({**data_process_config.toDict(), **{“k_fold”: config.k_fold, “random_state”: config.random_state, “dev_prop”: config.dev_prop}}) # 处理后的数据集路径 self.processed_path = os.path.join(DATA_PATH, config.exp_name, “processed”, unique_dir_name) mkdir_if_not_exist(self.processed_path) self.train_path = os.path.join(self.processed_path, “train_{}.csv”) self.dev_path = os.path.join(self.processed_path, “dev_{}.csv”) self.test_path = os.path.join(self.processed_path, “test.csv”) # 补充配置信息 config.splits = { “train”: self.train_path, “dev”: self.dev_path, “test”: self.test_path, } def process(self): # 训练集、开发集划分 if self.mode != “predict”: self._train_dev_dataset_split() # 测试集保存 self._test_dataset_save() def _train_dev_dataset_split(self): df = pd.read_csv(self.train_data_path, encoding=“utf-8”) X, y = df.drop(['BIO_anno'], axis=1), df['BIO_anno'] k_fold = int(1 / self.dev_prop) if self.k_fold == 0 else self.k_fold kf = KFold(n_splits=k_fold, shuffle=True, random_state=self.random_state).split(X, y) for k, (train_idx, dev_idx) in enumerate(kf): train_path = self.train_path.format(k) with open(train_path, “w”, encoding=“utf-8”) as train_f: train_writer = csv.writer(train_f) train_writer.writerow([“text”, “BIO_anno”]) for i in range(len(train_idx)): cur_X, cur_y = X.iloc[train_idx[i]], y.iloc[train_idx[i]] train_writer.writerow([cur_X[“text”], cur_y]) dev_path = self.dev_path.format(k) with open(dev_path, “w”, encoding=“utf-8”) as dev_f: dev_writer = csv.writer(dev_f) dev_writer.writerow([“text”, “BIO_anno”]) for i in range(len(dev_idx)): cur_X, cur_y = X.iloc[dev_idx[i]], y.iloc[dev_idx[i]] dev_writer.writerow([cur_X[“text”], cur_y]) if self.k_fold == 0: break def _test_dataset_save(self): df = pd.read_csv(self.test_data_path, encoding=“utf-8”) with open(self.test_path, “w”, encoding=“utf-8”) as test_f: test_writer = csv.writer(test_f) test_writer.writerow([“id”, “text”]) for idx, line in df.iterrows(): _id, text = line.get(“id”, “”), line.get(“text”, “”) test_writer.writerow([_id, text])登录后复制
3.3 数据集构建
dataset/data_fountain_529_ner.py
from paddlenlp.datasets import load_datasetfrom dotmap import DotMapimport pandas as pdclass DataFountain529NerDataset(object): “”“ df-529 NER 数据集 ”“” def __init__(self, config: DotMap): super().__init__() self.config = config def load_data(self, fold=0, splits=None, lazy=None): result = [] for split in splits: path = self.config.splits.get(split).format(fold) ds = load_dataset(self.read, data_path=path, lazy=lazy) result.append(ds) return result @staticmethod def read(data_path): df = pd.read_csv(data_path, encoding=“utf-8”) for idx, line in df.iterrows(): text, bio, qid = line.get(“text”, “”), line.get(“BIO_anno”, “”), line.get(“id”, “”) yield {“tokens”: list(text), “labels”: bio.split(), “qid”: qid} @staticmethod def get_labels(): return [“B-BANK”, “I-BANK”, “B-PRODUCT”, “I-PRODUCT”, “B-COMMENTS_N”, “I-COMMENTS_N”, “B-COMMENTS_ADJ”, “I-COMMENTS_ADJ”, “O”]登录后复制
3.4 模型搭建
model/data_fountain_529_ner.py
from paddlenlp.transformers import BertTokenizer, BertForTokenClassificationfrom paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassificationfrom paddlenlp.layers.crf import LinearChainCrf, LinearChainCrfLoss, ViterbiDecoderfrom dotmap import DotMapimport paddledef get_model_and_tokenizer(model_name: str, config: DotMap): config = DotMap({**config.toDict(), **config.model_config[model_name].toDict()}) if model_name == “bert_base”: model = BertForTokenClassification.from_pretrained(“bert-base-chinese”, num_classes=len(config.label_list)) tokenizer = BertTokenizer.from_pretrained(“bert-base-chinese”) elif model_name == “bert_crf”: bert = BertForTokenClassification.from_pretrained(“bert-base-chinese”, num_classes=len(config.label_list)) model = BertCrfForTokenClassification(bert) tokenizer = BertTokenizer.from_pretrained(“bert-base-chinese”) elif model_name == “ernie_base”: model = ErnieForTokenClassification.from_pretrained(“ernie-1.0”, num_classes=len(config.label_list)) tokenizer = ErnieTokenizer.from_pretrained(“ernie-1.0”) elif model_name == “ernie_crf”: ernie = ErnieForTokenClassification.from_pretrained(“ernie-1.0”, num_classes=len(config.label_list)) model = ErnieCrfForTokenClassification(ernie) tokenizer = ErnieTokenizer.from_pretrained(“ernie-1.0”) else: raise RuntimeError(“load model error: {}.”.format(model_name)) return model, tokenizer, configclass BertCrfForTokenClassification(paddle.nn.Layer): def __init__(self, bert, crf_lr=100): super().__init__() self.num_classes = bert.num_classes self.bert = bert self.crf = LinearChainCrf(self.num_classes, crf_lr=crf_lr, with_start_stop_tag=False) self.crf_loss = LinearChainCrfLoss(self.crf) self.viterbi_decoder = ViterbiDecoder(self.crf.transitions, False) def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None, lengths=None, labels=None): logits = self.bert( input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, position_ids=position_ids) if labels is not None: loss = self.crf_loss(logits, lengths, labels) return loss else: _, prediction = self.viterbi_decoder(logits, lengths) return predictionclass ErnieCrfForTokenClassification(paddle.nn.Layer): def __init__(self, ernie, crf_lr=100): super().__init__() self.num_classes = ernie.num_classes self.ernie = ernie self.crf = LinearChainCrf( self.num_classes, crf_lr=crf_lr, with_start_stop_tag=False) self.crf_loss = LinearChainCrfLoss(self.crf) self.viterbi_decoder = ViterbiDecoder(self.crf.transitions, False) def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None, lengths=None, labels=None): logits = self.ernie( input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, position_ids=position_ids) if labels is not None: loss = self.crf_loss(logits, lengths, labels) return loss else: _, prediction = self.viterbi_decoder(logits, lengths) return prediction登录后复制
3.5 训练器定义
trainer/data_fountain_529_ner.py
from paddlenlp.transformers import PretrainedTokenizer, LinearDecayWithWarmupfrom paddlenlp.datasets import MapDatasetfrom paddlenlp.data import Stack, Tuple, Padfrom paddlenlp.metrics import ChunkEvaluatorfrom paddle import nnfrom dotmap import DotMapfrom functools import partialfrom visualdl import LogWriterfrom utils.utils import create_data_loader, mkdir_if_not_exist, load_label_vocabfrom utils.loss import FocalLossimport numpy as npimport timeimport paddleimport osclass DataFountain529NerTrainer(object): train_data_loader = None dev_data_loader = None epochs = None ckpt_dir = None num_training_steps = None optimizer = None criterion = None metric = None ignore_label = -100 def __init__(self, model: nn.Layer, tokenizer: PretrainedTokenizer, train_ds: MapDataset, dev_ds: MapDataset, config: DotMap): if config.model_name not in config.model_config: raise RuntimeError(“current model: {} not configured”.format(config.model_name)) self.model = model self.tokenizer = tokenizer self.train_ds = train_ds self.dev_ds = dev_ds self.logger = config.logger self.config = config self._gen_data_loader(config) self._prepare(config) def _gen_data_loader(self, config): label_vocab = load_label_vocab(config.label_list) self.no_entity_id = label_vocab[“O”] # 将数据处理成模型可读入的数据格式 trans_func = partial( self.convert_example, tokenizer=self.tokenizer, max_seq_len=config.max_seq_len, label_vocab=label_vocab) batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=self.tokenizer.pad_token_id, dtype='int32'), # input_ids Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id, dtype='int32'), # token_type_ids Stack(dtype='int64'), # seq_len Pad(axis=0, pad_val=self.no_entity_id, dtype='int64') # labels ): [data for data in fn(samples)] self.train_data_loader = create_data_loader( self.train_ds, trans_fn=trans_func, mode='train', batch_size=config.batch_size, batchify_fn=batchify_fn) self.dev_data_loader = create_data_loader( self.dev_ds, trans_fn=trans_func, mode='dev', batch_size=config.batch_size, batchify_fn=batchify_fn) def _prepare(self, config): # 当前训练折次 self.fold = config.fold # 训练折数 self.total_fold = config.k_fold or 1 # 训练轮次 self.epochs = config.epochs # 训练过程中保存模型参数的文件夹 self.ckpt_dir = os.path.join(config.ckpt_dir, config.model_name, “fold_{}”.format(self.fold)) mkdir_if_not_exist(self.ckpt_dir) # 可视化日志的文件夹 self.train_vis_dir = os.path.join(config.vis_dir, config.model_name, “fold_{}/train”.format(self.fold)) self.dev_vis_dir = os.path.join(config.vis_dir, config.model_name, “fold_{}/dev”.format(self.fold)) mkdir_if_not_exist(self.train_vis_dir) mkdir_if_not_exist(self.dev_vis_dir) # 训练所需要的总 step 数 self.num_training_steps = len(self.train_data_loader) * self.epochs # 定义 learning_rate_scheduler,负责在训练过程中对 lr 进行调度 self.lr_scheduler = LinearDecayWithWarmup(config.learning_rate, self.num_training_steps, 0.0) # Generate parameter names needed to perform weight decay. # All bias and LayerNorm parameters are excluded. decay_params = [ p.name for n, p in self.model.named_parameters() if not any(nd in n for nd in [“bias”, “norm”]) ] # 定义 Optimizer self.optimizer = paddle.optimizer.AdamW( learning_rate=self.lr_scheduler, epsilon=config.adam_epsilon, parameters=self.model.parameters(), weight_decay=0.0, apply_decay_param_fun=lambda x: x in decay_params) if config.loss_func == “ce_loss”: # 交叉熵损失函数 self.criterion = nn.loss.CrossEntropyLoss(ignore_index=self.ignore_label) self.eval_criterion = nn.loss.CrossEntropyLoss(ignore_index=self.ignore_label) elif config.loss_func == “focal_loss”: # Focal Loss self.criterion = FocalLoss(num_classes=len(config.label_list), ignore_index=self.ignore_label) self.eval_criterion = FocalLoss(num_classes=len(config.label_list), ignore_index=self.ignore_label) else: raise RuntimeError(“config error loss function: {}”.format(config.loss_func)) # 评价指标 self.metric = ChunkEvaluator(label_list=config.label_list) self.eval_metric = ChunkEvaluator(label_list=config.label_list) def train(self): # 开启训练 global_step = 0 tic_train = time.time() with LogWriter(logdir=self.train_vis_dir) as train_writer: with LogWriter(logdir=self.dev_vis_dir) as dev_writer: for epoch in range(1, self.epochs + 1): for step, batch in enumerate(self.train_data_loader, start=1): input_ids, token_type_ids, lens, labels = batch if self.config.model_name in [“bert_crf”, “ernie_crf”]: loss = paddle.mean(self.model(input_ids, token_type_ids, lengths=lens, labels=labels)) global_step += 1 if global_step % 10 == 0: self.logger.info( “「%d/%d」global step %d, epoch: %d, batch: %d, loss: %.5f, speed: %.2f step/s” % (self.fold, self.total_fold, global_step, epoch, step, loss, 10 / (time.time() - tic_train))) tic_train = time.time() train_writer.add_scalar(tag=“loss”, step=global_step, value=loss) else: logits = self.model(input_ids, token_type_ids) # 计算损失函数值 loss = paddle.mean(self.criterion(logits, labels)) # 预测分类概率值 preds = logits.argmax(axis=2) n_infer, n_label, n_correct = self.metric.compute(lens, preds, labels) self.metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy()) precision, recall, f1_score = self.metric.accumulate() global_step += 1 if global_step % 10 == 0: self.logger.info( “「%d/%d」global step %d, epoch: %d, batch: %d, loss: %.5f, precision: %.5f, recall: %.5f, f1: %.5f, speed: %.2f step/s” % (self.fold, self.total_fold, global_step, epoch, step, loss, precision, recall, f1_score, 10 / (time.time() - tic_train))) tic_train = time.time() train_writer.add_scalar(tag=“precision”, step=global_step, value=precision) train_writer.add_scalar(tag=“recall”, step=global_step, value=recall) train_writer.add_scalar(tag=“f1”, step=global_step, value=f1_score) train_writer.add_scalar(tag=“loss”, step=global_step, value=loss) # 反向梯度回传,更新参数 loss.backward() self.optimizer.step() self.lr_scheduler.step() self.optimizer.clear_grad() if global_step % 10 == 0 or global_step == self.num_training_steps: # 评估当前训练的模型 loss_dev, precision_dev, recall_dev, f1_score_dev = self.evaluate() dev_writer.add_scalar(tag=“precision”, step=global_step, value=precision_dev) dev_writer.add_scalar(tag=“recall”, step=global_step, value=recall_dev) dev_writer.add_scalar(tag=“f1”, step=global_step, value=f1_score_dev) if self.config.model_name not in [“bert_crf”, “ernie_crf”]: dev_writer.add_scalar(tag=“loss”, step=global_step, value=loss_dev) # # 保存当前模型参数等 # if global_step >= 400: # save_dir = os.path.join(self.ckpt_dir, “model_%d” % global_step) # mkdir_if_not_exist(save_dir) # paddle.save(self.model.state_dict(), os.path.join(save_dir, “model.pdparams”)) @staticmethod def convert_example(example, tokenizer, max_seq_len, label_vocab): tokens, labels = example[“tokens”], example[“labels”] encoded_inputs = tokenizer(text=tokens, max_seq_len=max_seq_len, return_length=True, is_split_into_words=True) # -2 for [CLS] and [SEP] if len(encoded_inputs['input_ids']) - 2 < len(labels): labels = labels[:len(encoded_inputs['input_ids']) - 2] labels = [“O”] + labels + [“O”] labels += [“O”] * (len(encoded_inputs['input_ids']) - len(labels)) encoded_inputs[“labels”] = [label_vocab[label] for label in labels] return tuple([np.array(x, dtype=“int64”) for x in [encoded_inputs[“input_ids”], encoded_inputs[“token_type_ids”], encoded_inputs[“seq_len”], encoded_inputs[“labels”]]]) @paddle.no_grad() def evaluate(self): self.model.eval() self.eval_metric.reset() loss, precision, recall, f1_score = 0., 0., 0., 0. for batch in self.dev_data_loader: input_ids, token_type_ids, lens, labels = batch if self.config.model_name in [“bert_crf”, “ernie_crf”]: preds = self.model(input_ids, token_type_ids, lengths=lens) n_infer, n_label, n_correct = self.eval_metric.compute(lens, preds, labels) self.eval_metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy()) precision, recall, f1_score = self.eval_metric.accumulate() else: logits = self.model(input_ids, token_type_ids) preds = logits.argmax(axis=2) loss = paddle.mean(self.eval_criterion(logits, labels)) n_infer, n_label, n_correct = self.eval_metric.compute(lens, preds, labels) self.eval_metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy()) precision, recall, f1_score = self.eval_metric.accumulate() self.logger.info(“「%d/%d」eval loss: %.5f, precision: %.5f, recall: %.5f, f1: %.5f” % (self.fold, self.total_fold, loss, precision, recall, f1_score)) self.model.train() self.eval_metric.reset() return loss, precision, recall, f1_score登录后复制
3.6 开始训练
run/data_fountain_529_ner/train.py
from data_process.data_fountain_529_ner import DataFountain529NerDataProcessorfrom dataset.data_fountain_529_ner import DataFountain529NerDatasetfrom model.data_fountain_529_ner import get_model_and_tokenizerfrom trainer.data_fountain_529_ner import DataFountain529NerTrainerfrom utils.config_utils import get_config, CONFIG_PATHimport osdef train(): config = get_config(os.path.join(CONFIG_PATH, “data_fountain_529_ner.json”), “train”) # 原始数据预处理 data_processor = DataFountain529NerDataProcessor(config) data_processor.process() # 获取全部分类标签 config.label_list = DataFountain529NerDataset.get_labels() folds = [0] if config.k_fold == 0 else range(config.k_fold) for fold in folds: config.fold = fold # 获取训练集、开发集 train_ds, dev_ds = DataFountain529NerDataset(config).load_data( fold=config.fold, splits=['train', 'dev'], lazy=False ) # 加载 model 和 tokenizer model, tokenizer, config = get_model_and_tokenizer(config.model_name, config) # 获取训练器 trainer = DataFountain529NerTrainer( model=model, tokenizer=tokenizer, train_ds=train_ds, dev_ds=dev_ds, config=config ) # 开始训练 trainer.train()if __name__ == “__main__”: train()登录后复制
3.7 推断器定义
infer/data_fountain_529_ner.py
from paddlenlp.transformers import PretrainedTokenizerfrom paddlenlp.datasets import MapDatasetfrom paddlenlp.data import Stack, Tuple, Padfrom paddle import nnfrom dotmap import DotMapfrom functools import partialfrom utils.utils import create_data_loader, load_label_vocabimport numpy as npimport paddleimport osclass DataFountain529NerInfer(object): def __init__(self, model: nn.Layer, tokenizer: PretrainedTokenizer, test_ds: MapDataset, config: DotMap, model_params_path: str): self.model = model self.tokenizer = tokenizer self.test_ds = test_ds self.logger = config.logger self.config = config self._gen_data_loader(config) self._load_model(model_params_path) def _gen_data_loader(self, config): label_vocab = load_label_vocab(config.label_list) self.no_entity_id = label_vocab[“O”] # 将数据处理成模型可读入的数据格式 trans_func = partial( self.convert_example, tokenizer=self.tokenizer, max_seq_len=config.max_seq_len) batchify_fn = lambda samples, fn=Tuple( Pad(axis=0, pad_val=self.tokenizer.pad_token_id, dtype='int32'), # input_ids Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id, dtype='int32'), # token_type_ids Stack(dtype='int64'), # seq_len Stack(dtype='int64'), # qid ): [data for data in fn(samples)] self.test_data_loader = create_data_loader( self.test_ds, mode='test', batch_size=config.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func) def _load_model(self, model_params_path): try: # 加载模型参数 state_dict = paddle.load(model_params_path) self.model.set_dict(state_dict) self.logger.info(“Loaded parameters from {}”.format(model_params_path)) except Exception as e: raise RuntimeError(“Loaded parameters error from {}: {}”.format(model_params_path, e)) @paddle.no_grad() def predict(self): # 切换 model 模型为评估模式,关闭 dropout 等随机因素 self.model.eval() result = [] id2label = dict(enumerate(self.config.label_list)) for step, batch in enumerate(self.test_data_loader): input_ids, token_type_ids, lens, qids = batch logits = self.model(input_ids, token_type_ids) pred = paddle.argmax(logits, axis=-1) for i, end in enumerate(lens): tags = [id2label[x.numpy()[0]] for x in pred[i][1:end - 1]] qid = qids[i].numpy()[0] result.append([qid, tags]) return result @staticmethod def parse_decodes(input_words, id2label, decodes, lens): decodes = [x for batch in decodes for x in batch] lens = [x for batch in lens for x in batch] outputs = [] for idx, end in enumerate(lens): sent = “”.join(input_words[idx]['tokens']) tags = [id2label[x] for x in decodes[idx][1:end - 1]] outputs.append([sent, tags]) return outputs @staticmethod def convert_example(example, tokenizer, max_seq_len): tokens, qid = example[“tokens”], example[“qid”] encoded_inputs = tokenizer(text=tokens, max_seq_len=max_seq_len, return_length=True, is_split_into_words=True) return tuple([np.array(x, dtype=“int64”) for x in [encoded_inputs[“input_ids”], encoded_inputs[“token_type_ids”], encoded_inputs[“seq_len”], qid]])登录后复制
3.8 开始预测
from model.data_fountain_529_ner import get_model_and_tokenizerfrom data_process.data_fountain_529_ner import DataFountain529NerDataProcessorfrom dataset.data_fountain_529_ner import DataFountain529NerDatasetfrom infer.data_fountain_529_ner import DataFountain529NerInferfrom utils.config_utils import get_config, CONFIG_PATHfrom utils.utils import mkdir_if_not_existfrom dotmap import DotMapfrom scipy import statsimport csvimport osdef predict(): config = get_config(os.path.join(CONFIG_PATH, “data_fountain_529_ner.json”), “predict”) # 原始数据预处理 data_processor = DataFountain529NerDataProcessor(config) data_processor.process() # 获取全部分类标签 config.label_list = DataFountain529NerDataset.get_labels() # 使用配置中的所有模型进行融合 fusion_result = [] for model_name, weight in config.model_params.items(): # 计算单模型 K 折交叉验证的结果 k_fold_result = [] for fold in range(config.k_fold or 1): model_path = os.path.join(config.base_path, model_name, 'model_{}.pdparams'.format(fold)) fold_result = single_model_predict(config, model_name, model_path) k_fold_result.append(fold_result) # 融合 k 折模型的预测结果 merge_result = merge_k_fold_result(k_fold_result) # 将当前模型及对应权重保存 fusion_result.append([merge_result, weight]) # 融合所有模型的预测结果 result = merge_fusion_result(fusion_result) # 写入预测结果 res_dir = os.path.join(config.res_dir, config.model_name) mkdir_if_not_exist(res_dir) with open(os.path.join(res_dir, “result.csv”), “w”, encoding=“utf-8”) as f: writer = csv.writer(f) writer.writerow([“id”, “BIO_anno”]) for line in result: qid, tags = line writer.writerow([qid, “ ”.join(tags)])def merge_fusion_result(fusion_result): # TODO: 尝试不同的模型融合方法 return fusion_result[0]def single_model_predict(config: DotMap, model_name: str, model_path: str): # 获取测试集 [test_ds] = DataFountain529NerDataset(config).load_data(splits=['test'], lazy=False) # 加载 model 和 tokenizer model, tokenizer, config = get_model_and_tokenizer(model_name, config) # 获取推断器 infer = DataFountain529NerInfer(model, tokenizer=tokenizer, test_ds=test_ds, config=config, model_params_path=model_path) # 开始预测 result = infer.predict() return resultdef merge_k_fold_result(k_fold_result): merge_result = {} for fold_result in k_fold_result: for line in fold_result: qid, tags = line[0], line[1] if qid not in merge_result: merge_result[qid] = [] merge_result[qid].append(tags) result = [] for qid, tags in merge_result.items(): merge_tags = stats.mode(tags)[0][0] result.append([qid, merge_tags]) return resultif __name__ == “__main__": predict()登录后复制
来源:https://www.php.cn/faq/1412634.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- nef 格式图片降噪处理用什么工具 效果如何
- 时间:2025-07-29
-

- 邮箱长时间未登录被注销了能恢复吗?
- 时间:2025-07-29
-

- Outlook收件箱邮件不同步怎么办?
- 时间:2025-07-29
-

- 为什么客户端收邮件总是延迟?
- 时间:2025-07-29
-

- 一英寸在磁带宽度中是多少 老式设备规格
- 时间:2025-07-29
-

- 大卡和年龄的关系 不同年龄段热量需求
- 时间:2025-07-29
-

- jif 格式是 gif 的变体吗 现在还常用吗
- 时间:2025-07-29
-

- hdr 格式图片在显示器上能完全显示吗 普通显示器有局限吗
- 时间:2025-07-29
大家都在玩








大家都在看
更多-

- DNF11月职业平衡死灵怎么玩
- 时间:2025-11-10
-

- 台球游戏推荐2025
- 时间:2025-11-10
-

- 高人气轻量版吃鸡手游推荐
- 时间:2025-11-10
-

- 泰拉瑞亚是哪个国家的游戏
- 时间:2025-11-10
-
- 影视大全怎么设置开机时自动启动
- 时间:2025-11-10
-
- 影视大全怎么自动关联相关媒体文件
- 时间:2025-11-10
-
- 影视大全怎么设置退出时清除播放记录
- 时间:2025-11-10
-

- 吃鸡撩人名字两个字
- 时间:2025-11-10