《人工智能导论:案例与实践》 基于U-Net实现宠物图像分割
时间:2025-07-22 | 作者: | 阅读:0吴老师《人工智能导论:案例与实践》飞桨版课程公开,聚焦宠物图像分割实验。实验涵盖数据处理、模型构建、训练配置、模型训练、保存、评估及推理可视化。采用U-Net网络,经10000批次训练,验证集miou达69%左右,助学习者掌握图像分割原理与飞桨框架使用,可拓展尝试调参或其他算法。

宠物图像分割实验
 ? ? ? ?
? ? ? ?1. 实验介绍
1.1 实验目的
- 理解并掌握卷积神经网络的基础知识点,包括:卷积计算、池化等;
- 掌握经典图像分割网络U-Net的架构的设计原理以及构建流程;
- 熟悉飞桨开源框架构建卷积神经网络的方法。
1.2 实验内容
图像分割是计算机视觉领域的核心任务之一,与图像分类、目标检测并称为计算机视觉领域的三大基础任务。图像分割任务目标是将整幅图像切分成多个子图像区域。在实际运算过程中,会对图像中的每个像素点添加类别标签,从而实现精确定位图像中物体外形轮廓的作用。
深度学习中的卷积网络可以根据输入的图像,自动学习包含丰富语义信息的特征,得到更为全面的图像特征描述,更精确地完成图像分割任务。当前这一技术已经广泛应用于自动驾驶、地块检测、表计识别、医疗影像等多个行业中。
 ? ? ? ?
? ? ? ?1.3 实验环境
本实验支持在实训平台或本地环境操作,建议您使用实训平台。
- 实训平台:如果您选择在实训平台上操作,无需安装实验环境。实训平台集成了实验必须的相关环境,代码可在线运行,同时还提供了免费算力,即使实践复杂模型也无算力之忧。
- 本地环境:如果您选择在本地环境上操作,需要安装Python3.7、飞桨开源框架2.0等实验必须的环境,具体要求及实现代码请参见《本地环境安装说明》。
1.4 实验设计
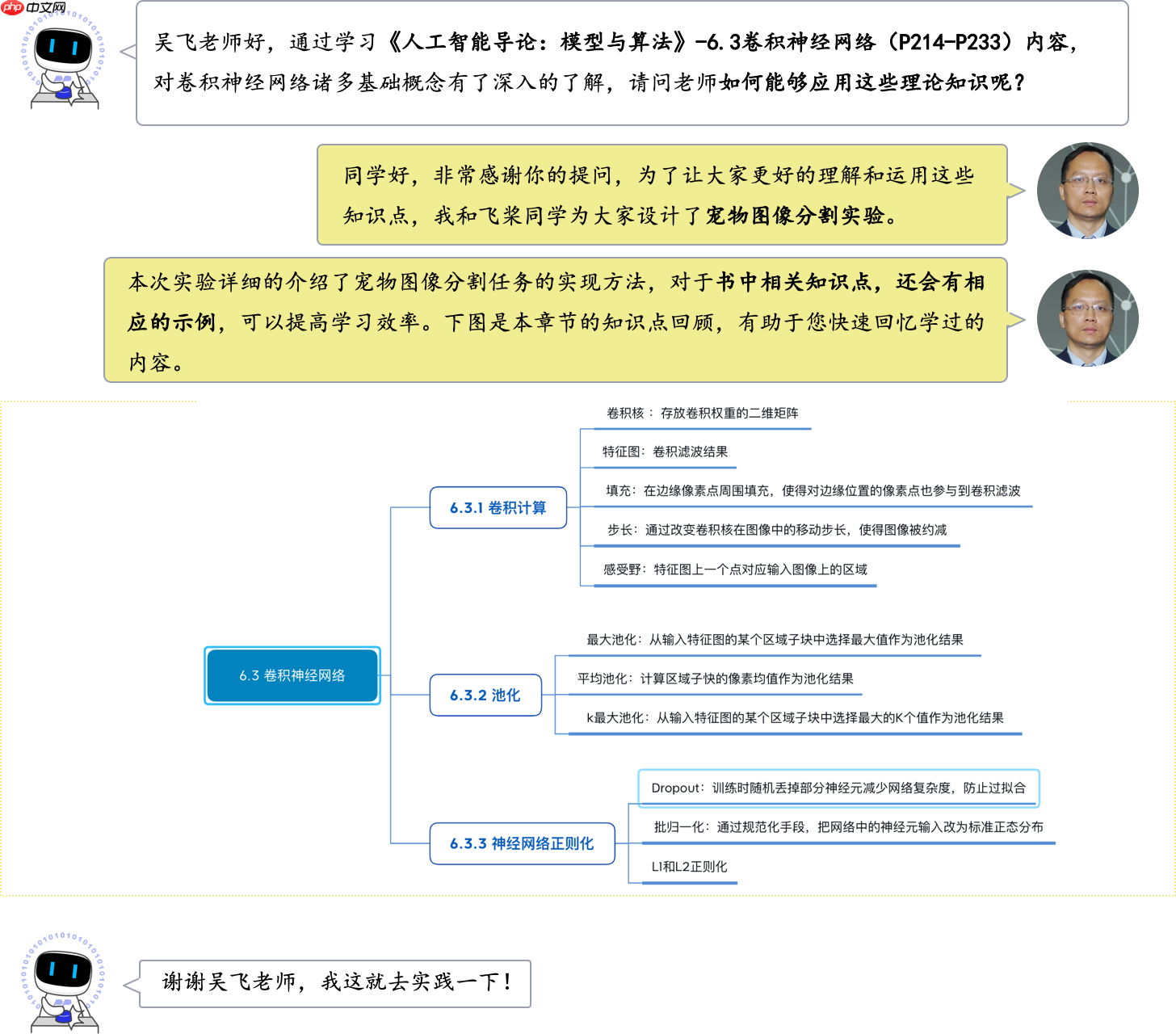
本实验的实现方案如?图3?所示,对于一幅宠物图像,首先使用卷积神经网络U-Net网络中的编码器提取特征(包含4个下采样阶段),获取高级语义特征图;然后使用解码器(包含4个上采样阶段)将特征图恢复到原始尺寸。在训练阶段,通过模型输出的预测图与样本的真实标签图构建损失函数,从而进行模型训练;在推理阶段,使用模型的预测图作为最终的输出。
 ? ? ? ?
? ? ? ?2. 实验详细实现
图像分割实验流程如?图4?所示,包含如下7个步骤:
- 数据处理:根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取;
- 模型构建:设计卷积网络结构(模型的假设空间);
- 训练配置:实例化模型,指定模型采用的寻解算法(优化器),定义损失函数,定义评估指标;
- 模型训练:执行多轮训练不断调整参数,以达到较好的效果;
- 模型保存:将模型参数保存到指定位置,便于后续推理或继续训练使用。
- 模型评估:对训练好的模型进行评估测试,观察准确率和Loss;
- 模型推理及可视化:使用一张测试图片来验证模型识别的效果,并可视化推理结果。
? ? ? ?
 ? ? ? ?
? ? ? ?说明:
不同的深度学习任务,使用深度学习框架的代码结构基本相似。大家掌握了一个任务的实现方法,便很容易在此基础上举一反三。使用深度学习框架可以屏蔽底层实现,用户只需关注模型的逻辑结构。同时,简化了计算,降低了深度学习入门门槛。
2.1 数据处理
2.1.1 数据集介绍
本次实验选取了学术经典的The Oxford-IIIT Pet Dataset数据集。The Oxford-IIIT Pet Dataset是一个宠物图像数据集,包含2371张猫的图片以及4978张狗的图片。数据集中提供了像素级别的分割标签图片,其中前景部分(宠物)标注为类别1;轮廓部分标注为类别2;背景部分标注为类别3。如?图5?所示。
 ? ? ? ?
? ? ? ?解压缩后的目录结构如下:
~/work/Dataset||--images|--trimaps登录后复制 ? ? ? ?
文件解压操作代码实现如下:
In [?]%cd /home/aistudio/work# 初次运行时将注释取消,以便解压文件# 如果已经解压过,不需要运行此段代码,否则由于文件已经存在,解压时会报错#!unzip -q /home/aistudio/data/data79141/Dataset.zip登录后复制 ? ? ? ?
/home/aistudio/work登录后复制 ? ? ? ?
对原始的数据集进行整理,将图片的路径和对应的标签图片路径进行一一对应,并按照4:1的比例划分训练集和测试集,生成实验需要的train、test标签文件,代码如下所示:
In [?]# coding=utf-8# 导入环境import osimport randomimport cv2import numpy as npfrom PIL import Imagefrom paddle.io import Datasetimport matplotlib.pyplot as plt# 在notebook中使用matplotlib.pyplot绘图时,需要添加该命令进行显示%matplotlib inlineimport paddleimport paddle.nn.functional as Fimport paddle.nn as nnIMAGE_SIZE = (160, 160)train_images_path = ”/home/aistudio/work/Dataset/images“label_images_path = ”/home/aistudio/work/Dataset/trimaps“image_count = len([os.path.join(train_images_path, image_name) for image_name in os.listdir(train_images_path) if image_name.endswith('.jpg')])# 对文件夹内的图像按文件名排序def _sort_images(image_dir, image_type): files = [] for image_name in os.listdir(image_dir): if image_name.endswith('.{}'.format(image_type)) and not image_name.startswith('.'): files.append(os.path.join(image_dir, image_name)) return sorted(files)# 生成实验需要的train、test标签文件,标签格式如下:‘images/image1.jpg labels/label1.png’def write_file(images, labels, eval_num): train_file = open('/home/aistudio/work/Dataset/train.txt', 'w') test_file = open('/home/aistudio/work/Dataset/test.txt', 'w') predict_file = open('/home/aistudio/work/Dataset/predict.txt', 'w') # 随机打乱文件顺序并保存文件路径 image_index = [i for i in range(image_count)] random.shuffle(image_index) for n in range(image_count): if n < eval_num: test_file.write('{} {}n'.format(images[image_index[n]], labels[image_index[n]])) predict_file.write('{} {}n'.format(images[image_index[n]], labels[image_index[n]])) else: train_file.write('{} {}n'.format(images[image_index[n]], labels[image_index[n]]))images = _sort_images(train_images_path, 'jpg')labels = _sort_images(label_images_path, 'png')eval_num = int(image_count * 0.20)# 对数据集进行处理,划分训练集、测试集write_file(images, labels, eval_num)登录后复制 ? ? ? ?
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized2022-06-17 18:25:57,747 - INFO - font search path ['/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/afm', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts']2022-06-17 18:25:58,182 - INFO - generated new fontManager登录后复制 ? ? ? ?
使用PIL库,随机选取一张图片可视化,观察该数据集的图片数据。
In [?]# 使用PIL库读取图片,并转为numpy array的格式# (思考)您也可以尝试修改下面代码中jpg文件夹包含的图片标号image_000XX,可视化数据集中的其他图片。image = Image.open('/home/aistudio/work/Dataset/images/British_Shorthair_128.jpg')image = np.array(image)label = Image.open('/home/aistudio/work/Dataset/trimaps/British_Shorthair_128.png')label = np.array(label)# 画出读取的图片plt.subplot(1,2,1),plt.title('Train Image')plt.imshow(image)plt.axis('off')plt.subplot(1,2,2),plt.title('Label')plt.imshow(label)plt.axis('off')登录后复制 ? ? ? ?
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator):/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data登录后复制 ? ? ? ?
(-0.5, 331.5, 499.5, -0.5)登录后复制 ? ? ? ? ? ? ? ?
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/numpy/lib/type_check.py:546: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead 'a.item() instead', DeprecationWarning, stacklevel=1)登录后复制 ? ? ? ?
<Figure size 432x288 with 2 Axes>登录后复制 ? ? ? ? ? ? ? ?In [?]
# 查看原始图片以及标签图片的形状print(image.shape, label.shape)登录后复制 ? ? ? ?
(500, 332, 3) (500, 332)登录后复制 ? ? ? ?
2.1.2 数据预处理
本实验中,图像分割算法对输入图片的格式、大小有一定的要求,数据输入模型前,需要对数据进行预处理操作,使图片满足网络训练以及预测的需要。另外,为了扩大训练集,抑制过拟合,提升模型的泛化能力,实验中还使用了几种基础的数据增广方法。
- 随机缩放图像:在[0.5, 2.0]范围内,以0.25为步长生成尺度列表后,随机选择一个值作为缩放的尺度进行图像缩放;
- 随机裁剪图像:从原始图像和标签图像中随机裁剪一个子图像。 如果目标裁切尺寸大于原始图像,则将添加右下角的填充。裁剪尺寸为[512, 512];
- 随机翻转图像:以一定的概率水平翻转图像。这里使用0.5的概率进行图像翻转;
- 归一化:通过规范化手段,将神经网络每层中任意神经元的输入值分布改变成均值为0,方差为1的标准正太分布,使得最优解的寻优过程明显会变得平缓,训练过程更容易收敛。
下面分别介绍数据预处理方法的代码实现。
随机缩放图像
在[0.5, 2.0]范围内,以0.25为步长生成尺度列表后,随机选择一个值作为缩放的尺度进行图像缩放。
In [?]# 使用opencv库缩放图像def resize(im, target_size=608, interp=cv2.INTER_LINEAR): if isinstance(target_size, list) or isinstance(target_size, tuple): w = target_size[0] h = target_size[1] else: w = target_size h = target_size im = cv2.resize(im, (w, h), interpolation=interp) return im登录后复制 ? ?In [?]
# 随机缩放图像class ResizeStepScaling: def __init__(self, min_scale_factor=0.5, max_scale_factor=2.0, scale_step_size=0.25): self.min_scale_factor = min_scale_factor self.max_scale_factor = max_scale_factor self.scale_step_size = scale_step_size def __call__(self, im, label=None): # 在[min_scale_factor, max_scale_factor]范围内,以scale_step_size为步长生成尺度列表 num_steps = int((self.max_scale_factor - self.min_scale_factor) / self.scale_step_size + 1) scale_factors = np.linspace(self.min_scale_factor, self.max_scale_factor, num_steps).tolist() # 随机打乱尺度列表 np.random.shuffle(scale_factors) # 取出列表中第一个尺度值 scale_factor = scale_factors[0] w = int(round(scale_factor * im.shape[1])) h = int(round(scale_factor * im.shape[0])) # 缩放图像 im = resize(im, (w, h), cv2.INTER_LINEAR) # 如果传入了标签图像,则进行缩放 if label is not None: label = resize(label, (w, h), cv2.INTER_NEAREST) if label is None: return (im, ) else: return (im, label)登录后复制 ? ?
随机裁剪图像
从原始图像和注释图像中随机裁剪一个子图像。 如果目标裁切尺寸大于原始图像,则将添加右下角的填充。裁剪尺寸为[512, 512]。
In [?]# 随机裁剪图像class RandomPaddingCrop: def __init__(self, crop_size=(512, 512), im_padding_value=(127.5, 127.5, 127.5), label_padding_value=255): self.crop_size = crop_size self.im_padding_value = im_padding_value self.label_padding_value = label_padding_value def __call__(self, im, label=None): crop_width = self.crop_size[0] crop_height = self.crop_size[1] img_height = im.shape[0] img_width = im.shape[1] # 如果剪裁尺寸等于原图像尺寸,则直接返回原图像 if img_height == crop_height and img_width == crop_width: if label is None: return (im, ) else: return (im, label) else: # 如果目标裁切尺寸大于原始图像,则将添加右下角的填充 pad_height = max(crop_height - img_height, 0) pad_width = max(crop_width - img_width, 0) if (pad_height > 0 or pad_width > 0): im = cv2.copyMakeBorder(im, 0, pad_height, 0, pad_width, cv2.BORDER_CONSTANT, value=self.im_padding_value) if label is not None: label = cv2.copyMakeBorder(label, 0, pad_height, 0, pad_width, cv2.BORDER_CONSTANT, value=self.label_padding_value) img_height = im.shape[0] img_width = im.shape[1] # 随机裁剪图像 if crop_height > 0 and crop_width > 0: h_off = np.random.randint(img_height - crop_height + 1) w_off = np.random.randint(img_width - crop_width + 1) im = im[h_off:(crop_height + h_off), w_off:(w_off + crop_width), :] if label is not None: label = label[h_off:(crop_height + h_off), w_off:(w_off + crop_width)] if label is None: return (im, ) else: return (im, label)登录后复制 ? ?
随机翻转图像
以一定的概率水平翻转图像。这里使用0.5的概率进行图像翻转。
In [?]# 水平翻转图像def horizontal_flip(im): if len(im.shape) == 3: im = im[:, ::-1, :] elif len(im.shape) == 2: im = im[:, ::-1] return im登录后复制 ? ?In [?]
# 随机翻转图像class RandomHorizontalFlip: def __init__(self, prob=0.5): self.prob = prob def __call__(self, im, label=None): # 以0.5的概率水平翻转图像 if random.random() < self.prob: im = horizontal_flip(im) if label is not None: label = horizontal_flip(label) if label is None: return (im, ) else: return (im, label)登录后复制 ? ?
归一化
In [?]# 归一化class Normalize: def __init__(self, mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)): self.mean = mean self.std = std from functools import reduce if reduce(lambda x, y: x * y, self.std) == 0: raise ValueError('{}: std is invalid!'.format(self)) def __call__(self, im, label=None): # 图像归一化 mean = np.array(self.mean)[np.newaxis, np.newaxis, :] std = np.array(self.std)[np.newaxis, np.newaxis, :] im = im.astype(np.float32, copy=False) / 255.0 im -= mean im /= std if label is None: return (im, ) else: return (im, label)登录后复制 ? ?
图像预处理方法汇总
In [?]# 图像预处理方法汇总def transforms(im, label=None, mode='train'): # 如果是训练集,需要进行数据增广 if mode == 'train': transform_list = [ResizeStepScaling, RandomPaddingCrop, RandomHorizontalFlip, Normalize] # 如果是测试集或验证集,仅需要归一化图像 else: transform_list = [Normalize] if isinstance(im, str): im = cv2.imread(im).astype('float32') if isinstance(label, str): # 将标签'1,2,3'调整为'0,1,2' label = np.asarray(Image.open(label))-1 im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) for transform_class in transform_list: op = transform_class() outputs = op(im, label) im = outputs[0] if len(outputs) == 2: label = outputs[1] im = np.transpose(im, (2, 0, 1)) return (im, label)登录后复制 ? ?
2.1.3 批量数据读取
上面的代码仅展示了读取一张图片和预处理的方法,但在真实场景的模型训练与评估过程中,通常会使用批量数据读取和预处理的方式。
定义数据读取类Dataset,实现数据批量读取和预处理。具体代码如下:
In [?]# 定义数据读取类class Dataset(paddle.io.Dataset): def __init__(self, dataset_root, mode='train', train_path=None, val_path=None, ignore_index=255): self.dataset_root = dataset_root self.file_list = list() self.mode = mode.lower() self.num_classes = 3 self.ignore_index = ignore_index self.dataset_root = dataset_root # 获取train、test标签文件 if mode == 'train': file_path = train_path else: file_path = val_path # 获取原始图片和标签图片列表 with open(file_path, 'r') as f: for line in f: items = line.strip().split(' ') image_path = os.path.join(self.dataset_root, items[0]) label_path = os.path.join(self.dataset_root, items[1]) self.file_list.append([image_path, label_path]) # 获取数据 def __getitem__(self, idx): image_path, label_path = self.file_list[idx] # 如果是验证集,仅对原始图片进行数据预处理 if self.mode == 'eval': im, _ = transforms(im=image_path, mode='val') # 将标签'1,2,3'调整为'0,1,2' label = np.asarray(Image.open(label_path))-1 label = label[np.newaxis, :, :] return im, label # 如果是训练集,需要对原始图片和标签图片进行数据增广处理 else: im, label = transforms(im=image_path, label=label_path, mode='train') return im, label def __len__(self): return len(self.file_list)登录后复制 ? ?
数据预处理耗时较长,推荐使用?paddle.io.DataLoader?API中的num_workers参数,设置进程数量,实现多进程读取数据。
class?paddle.io.DataLoader(dataset, batchsize=2, numworkers=2)
关键参数含义如下:
- batch_size (int|None) - 每个mini-batch中样本个数;
- num_workers (int) - 加载数据的子进程个数 。
说明:
熟练掌握API的使用方法,是使用开源框架完成各类深度学习任务的基础,也是开发者必须掌握的技能。飞桨API获取路径: “飞桨官网->文档->API文档”。
多线程读取实现代码如下。
In [?]DATADIR = '/home/aistudio/work/Dataset'train_path = '/home/aistudio/work/Dataset/train.txt'eval_path = '/home/aistudio/work/Dataset/test.txt'# 创建数据读取类train_dataset = Dataset(DATADIR, mode='train', train_path=train_path)eval_dataset = Dataset(DATADIR, mode='eval', val_path=eval_path)# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数train_sampler = paddle.io.DistributedBatchSampler(train_dataset, batch_size=8, shuffle=True, drop_last=True)train_loader = paddle.io.DataLoader(train_dataset, batch_sampler=train_sampler, num_workers=0, return_list=True)valid_sampler = paddle.io.DistributedBatchSampler(eval_dataset, batch_size=1, shuffle=False, drop_last=False)valid_loader = paddle.io.DataLoader(eval_dataset, batch_sampler=valid_sampler, num_workers=0, return_list=True)登录后复制 ? ?
至此完成了数据读取、提取数据标签信息、数据预处理、批量读取和加速等过程,通过paddle.io.Dataset可以返回图片和标签信息,接下来将处理好的数据输入到神经网络,应用到具体算法上。
2.2 模型构建
U-Net网络是一个非常经典的图像分割网络,起源于医疗图像分割,具有参数少、计算快、应用性强的特点,对于一般场景适应度很高。U-Net最早于2015年提出,并在ISBI 2015 Cell Tracking Challenge取得了第一。
U-Net的结构是标准的编码器—解码器结构,如?图7?所示。左侧可视为一个编码器,右侧可视为一个解码器。图像先经过编码器进行下采样得到高级语义特征图,再经过解码器上采样将特征图恢复到原图片的分辨率。网络中还使用了跳跃连接,即解码器每上采样一次,就以拼接的方式将解码器和编码器中对应相同分辨率的特征图进行特征融合,帮助解码器更好地恢复目标的细节。
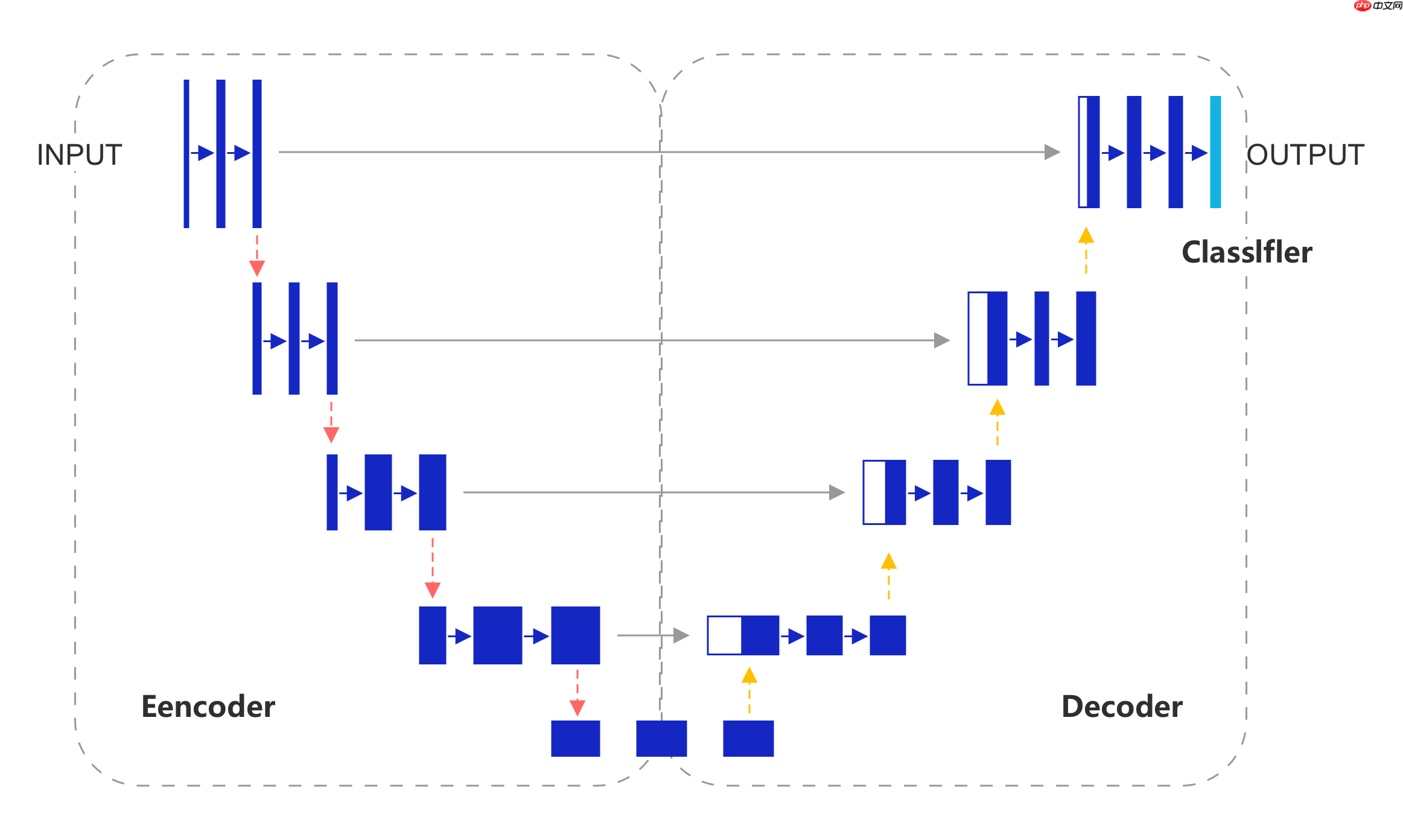 ? ? ? ?
? ? ? ?1)Encoder:编码器整体呈现逐渐缩小的结构,不断缩小特征图的分辨率,以捕获上下文信息。编码器共分为4个阶段,在每个阶段中,使用最大池化层进行下采样,然后使用两个卷积层提取特征,最终的特征图缩小了16倍;
2)Decoder:解码器呈现与编码器对称的扩张结构,逐步修复分割对象的细节和空间维度,实现精准的定位。解码器共分为4个阶段,在每个阶段中,将输入的特征图进行上采样后,与编码器中对应尺度的特征图进行拼接运算,然后使用两个卷积层提取特征,最终的特征图放大了16倍;
3)分类模块:使用大小为3×3的卷积,对像素点进行分类;
说明:
延伸阅读:U-Net: Convolutional Networks for Biomedical Image Segmentation
声明Layer子类
由于模型结构较为复杂,我们可以先使用飞桨中定义 Layer 子类的方式定义出整体的U-Net网络框架。Layer 子类中包含两个函数:
- init 函数:声明Layer组网 ;
- forward 函数:使用声明的 Layer 变量进行前向计算。
代码实现如下所示:
In [?]class UNet(nn.Layer): # 继承paddle.nn.Layer定义网络结构 def __init__(self, num_classes=3): # 初始化函数 super().__init__() # 定义编码器 self.encode = Encoder() # 定义解码器 self.decode = Decoder() # 分类模块 self.cls = nn.Conv2D(in_channels=64, out_channels=num_classes, kernel_size=3, stride=1, padding=1) def forward(self, x): # 前向计算 logit_list = [] # 编码运算 x, short_cuts = self.encode(x) # 解码运算 x = self.decode(x, short_cuts) # 分类运算 logit = self.cls(x) logit_list.append(logit) return logit_list登录后复制 ? ?
定义编码器
上边我们将模型分为了编码器、解码器和分类模块三个部分。其中,分类模块已经被实现,接下来分别定义编码器和解码器部分:
首先是编码器部分。这里的编码器通过不断地重复一个单元结构来增加通道数,减小图片尺寸,得到高级语义特征图。
说明:
考虑到卷积层、批归一化以及ReLU激活函数作为一个模块,在U-Net网络中频繁被使用。因此,这里将其定义为一个Layer子类,方便复用。
代码实现如下所示:
In [?]class ConvBNReLU(nn.Layer): def __init__(self, in_channels, out_channels, kernel_size, padding='same'): # 初始化函数 super().__init__() # 定义卷积层 self._conv = nn.Conv2D(in_channels, out_channels, kernel_size, padding=padding) # 定义批归一化层 self._batch_norm = nn.SyncBatchNorm(out_channels) def forward(self, x): # 前向计算 x = self._conv(x) x = self._batch_norm(x) x = F.relu(x) return x登录后复制 ? ?In [?]
class Encoder(nn.Layer): def __init__(self): # 初始化函数 super().__init__() # # 封装两个ConvBNReLU模块 self.double_conv = nn.Sequential(ConvBNReLU(3, 64, 3), ConvBNReLU(64, 64, 3)) # 定义下采样通道数 down_channels = [[64, 128], [128, 256], [256, 512], [512, 512]] # 封装下采样模块 self.down_sample_list = nn.LayerList([self.down_sampling(channel[0], channel[1]) for channel in down_channels]) # 定义下采样模块 def down_sampling(self, in_channels, out_channels): modules = [] # 添加最大池化层 modules.append(nn.MaxPool2D(kernel_size=2, stride=2)) # 添加两个ConvBNReLU模块 modules.append(ConvBNReLU(in_channels, out_channels, 3)) modules.append(ConvBNReLU(out_channels, out_channels, 3)) return nn.Sequential(*modules) def forward(self, x): # 前向计算 short_cuts = [] # 卷积运算 x = self.double_conv(x) # 下采样运算 for down_sample in self.down_sample_list: short_cuts.append(x) x = down_sample(x) return x, short_cuts登录后复制 ? ?
定义解码器
在通道数达到最大,得到高级语义特征图后,网络结构会开始进行解码操作。这里的解码也就是进行上采样,减小通道数的同时逐步增加对应图片尺寸,直至恢复到原图像大小。本实验中,使用双线性插值方法实现图片的上采样。双线性插值是线性插值的扩展,用于在直线2D网格上插值两个变量(例如,该操作中的H方向和W方向)的函数。 关键思想是首先在一个方向上执行线性插值,然后在另一个方向上再次执行线性插值。
在定义上采样模块时,需要使用paddle.nn.functional.interpolate?API。
class?paddle.nn.functional.interpolate(x, size=None, mode='nearest')
关键参数含义如下:
- x (Tensor) - 输入Tensor。
- size (list|tuple|Tensor|None) - 输出尺寸。
- mode (str) - 插值方法。
具体代码如下所示:
In [?]# 定义上采样模块class UpSampling(nn.Layer): def __init__(self, in_channels, out_channels): # 初始化函数 super().__init__() in_channels *= 2 # 封装两个ConvBNReLU模块 self.double_conv = nn.Sequential(ConvBNReLU(in_channels, out_channels, 3), ConvBNReLU(out_channels, out_channels, 3)) def forward(self, x, short_cut): # 前向计算 # 定义双线性插值模块 x = F.interpolate(x, paddle.shape(short_cut)[2:], mode='bilinear') # 特征图拼接 x = paddle.concat([x, short_cut], axis=1) # 卷积计算 x = self.double_conv(x) return x登录后复制 ? ?In [?]
# 定义解码器class Decoder(nn.Layer): def __init__(self): # 初始化函数 super().__init__() # 定义上采样通道数 up_channels = [[512, 256], [256, 128], [128, 64], [64, 64]] # 封装上采样模块 self.up_sample_list = nn.LayerList([UpSampling(channel[0], channel[1]) for channel in up_channels]) def forward(self, x, short_cuts): # 前向计算 for i in range(len(short_cuts)): # 上采样计算 x = self.up_sample_list[i](x, short_cuts[-(i + 1)]) return x登录后复制 ? ?
2.3 训练配置
声明定义好的模型实例,再定义优化器和损失函数。本实验使用Momentum优化器,其中,学习率使用多项式衰减的策略。其中,在定义学习率时,需要使用paddle.optimizer.lr.PolynomialDecay?API。
class?paddle.optimizer.lr.PolynomialDecay(learning_rate, end_lr=0.0001, power=1.0)
关键参数含义如下:
- learning_rate (float) - 初始学习率。
- end_lr (float)- 最小的最终学习率。
- power (float,可选) - 多项式的幂。
1)定义模型实例。
In [?]# 声明定义好的UNet模型model = UNet()登录后复制 ? ?
2)定义优化器
In [?]# 定义总的训练批次数iters = 10000# (思考)您也可以尝试增加训练批次数(如30000),观察训练批次数的变化对模型效果的影响# 定义学习率参数lr = paddle.optimizer.lr.PolynomialDecay(0.01, iters, end_lr=0.0, power=0.9)# 使用Momentum优化器,学习率设置为0.001optimizer = paddle.optimizer.Momentum(learning_rate=lr, momentum=0.9, parameters=model.parameters(), weight_decay=4.0e-5)#(思考)您也可以尝试使用SGD、Adam等其他优化器,观察训练结果登录后复制 ? ?
3)定义损失函数
In [?]class CrossEntropyLoss(nn.Layer): def __init__(self, ignore_index=255): super(CrossEntropyLoss, self).__init__() self.ignore_index = ignore_index self.EPS = 1e-8 def forward(self, logit, label): logit = paddle.transpose(logit, [0, 2, 3, 1]) # 计算交叉熵损失,不计算损失的平均值 loss = F.cross_entropy(logit, label, ignore_index=self.ignore_index, reduction='none') # 计算掩膜 mask = label != self.ignore_index mask = paddle.cast(mask, 'float32') # 计算损失值 loss = loss * mask avg_loss = paddle.mean(loss) / (paddle.mean(mask) + self.EPS) label.stop_gradient = True mask.stop_gradient = True return avg_loss登录后复制 ? ?
4)定义评估方式
这里采用了两种指标对模型效果进行评估:
- miou:平均iou。不同类别的宠物预测结果和真实标签的iou平均值。
- acc:准确率。宠物预测结果和真实标签相交部分的面积除以预测区域的面积。
# 分别计算宠物预测结果和真实标签的相交区域、宠物预测结果区域、真实标签区域的面积def calculate_area(pred, label, num_classes=3, ignore_index=255): if len(pred.shape) == 4: pred = paddle.squeeze(pred, axis=1) if len(label.shape) == 4: label = paddle.squeeze(label, axis=1) # 生成图像区域的掩膜 mask = label != ignore_index pred = pred + 1 label = label + 1 pred = pred * mask label = label * mask # 将预测结果和标签转换为one hot格式 pred = F.one_hot(pred, num_classes + 1) label = F.one_hot(label, num_classes + 1) pred = pred[:, :, :, 1:] label = label[:, :, :, 1:] pred_area = [] label_area = [] intersect_area = [] # 循环遍历每个类别 for i in range(num_classes): pred_i = pred[:, :, :, i] label_i = label[:, :, :, i] # 计算预测区域的面积 pred_area_i = paddle.sum(pred_i) # 计算真实区域的面积 label_area_i = paddle.sum(label_i) # 计算预测区域和真实区域相交的面积 intersect_area_i = paddle.sum(pred_i * label_i) pred_area.append(pred_area_i) label_area.append(label_area_i) intersect_area.append(intersect_area_i) pred_area = paddle.concat(pred_area) label_area = paddle.concat(label_area) intersect_area = paddle.concat(intersect_area) return intersect_area, pred_area, label_area登录后复制 ? ?In [?]
# 计算平均ioudef mean_iou(intersect_area, pred_area, label_area): intersect_area = intersect_area.numpy() pred_area = pred_area.numpy() label_area = label_area.numpy() # 计算预测区域和真实区域的并集部分 union = pred_area + label_area - intersect_area class_iou = [] # 计算iou for i in range(len(intersect_area)): if union[i] == 0: iou = 0 else: iou = intersect_area[i] / union[i] class_iou.append(iou) # 计算各个类别的iou均值 miou = np.mean(class_iou) return np.array(class_iou), miou登录后复制 ? ?In [?]
# 计算平均准确率def accuracy(intersect_area, pred_area): intersect_area = intersect_area.numpy() pred_area = pred_area.numpy() class_acc = [] # 计算准确率 for i in range(len(intersect_area)): if pred_area[i] == 0: acc = 0 else: acc = intersect_area[i] / pred_area[i] class_acc.append(acc) # 计算平均准确率 macc = np.sum(intersect_area) / np.sum(pred_area) return np.array(class_acc), macc登录后复制 ? ?
2.4 模型训练
训练模型并调整参数的过程,观察模型学习的过程是否正常,如损失函数值是否在降低。本实验考虑到时长因素,只训练了10000个批次,总批次数在配置优化器时进行了定义。其中,每隔100个批次会在训练集上计算loss并打印;每隔1000个批次会在验证集上计算平均iou和准确率并打印。
In [?]# 定义训练过程# 调用GPU进行运算use_gpu = Truepaddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')print('start training ... ')# 将模型切换到训练模式model.train()avg_loss = 0.0iters_per_epoch = len(train_sampler)best_miou = -1.0best_model_iter = -1# 训练模型 now_iter = 0while now_iter < iters: for data in train_loader: now_iter += 1 if now_iter > iters: break images = data[0] labels = data[1].astype('int64') # 运行模型前向计算,得到预测值 logits = model(images)[0] # 计算损失 loss_func = CrossEntropyLoss() loss= loss_func(logits, labels) # 反向传播,更新权重,清除梯度 loss.backward() optimizer.step() optimizer._learning_rate.step() model.clear_gradients() avg_loss += loss.numpy()[0] # 每隔100个iters打印当前指标 if (now_iter) % 100 == 0 : avg_loss /= 100 remain_iters = iters - now_iter lr_now = optimizer.get_lr() print(”[TRAIN] epoch={}, iter={}/{}, loss={:.4f}, lr={:.6f}“ .format((now_iter - 1) // iters_per_epoch + 1, now_iter, iters, avg_loss, lr_now)) # 将avg_loss重置为0 avg_loss = 0.0 # 每1000个iters训练完成后,进行模型评估 if (now_iter % 1000 == 0 or now_iter == iters) and (eval_dataset is not None): # 将模型切换到评估模式 model.eval() intersect_area_all = 0 pred_area_all = 0 label_area_all = 0 with paddle.no_grad(): for eval_iter, (im, label) in enumerate(valid_loader): label = label.astype('int64') # 运行模型前向计算,得到预测值 pred = model(im)[0] pred = paddle.argmax(pred, axis=1, keepdim=True, dtype='int32') # 计算相交区域、预测区域、标签区域 intersect_area, pred_area, label_area = calculate_area(pred, label, num_classes=3, ignore_index=255) intersect_area_all = intersect_area_all + intersect_area pred_area_all = pred_area_all + pred_area label_area_all = label_area_all + label_area # 计算平均iou class_iou, miou = mean_iou(intersect_area_all, pred_area_all, label_area_all) # 计算准确率 class_acc, acc = accuracy(intersect_area_all, pred_area_all) print(”[EVAL] #Images={} mIoU={:.4f} Acc={:.4f}“.format(len(eval_dataset), miou, acc)) # 如果当前的平均iou大于最佳的平均iou,保存最佳模型 if miou > best_miou: best_miou = miou best_model_iter = now_iter paddle.save(model.state_dict(), 'best_model.pdparams') print('[EVAL] The model with the best validation mIoU ({:.4f}) was saved at iter {}.' .format(best_miou, best_model_iter)) model.train()登录后复制 ? ? ? ?
start training ...登录后复制 ? ? ? ?
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)):Corrupt JPEG data: premature end of data segment登录后复制 ? ? ? ?
[TRAIN] epoch=1, iter=100/10000, loss=0.9838, lr=0.009910[TRAIN] epoch=1, iter=200/10000, loss=0.8644, lr=0.009820登录后复制 ? ? ? ?
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9登录后复制登录后复制登录后复制 ? ? ? ?
[TRAIN] epoch=1, iter=300/10000, loss=0.8139, lr=0.009730[TRAIN] epoch=1, iter=400/10000, loss=0.7672, lr=0.009639[TRAIN] epoch=1, iter=500/10000, loss=0.7334, lr=0.009549[TRAIN] epoch=1, iter=600/10000, loss=0.7208, lr=0.009458[TRAIN] epoch=1, iter=700/10000, loss=0.6687, lr=0.009368登录后复制 ? ? ? ?
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9登录后复制登录后复制登录后复制 ? ? ? ?
[TRAIN] epoch=2, iter=800/10000, loss=0.6794, lr=0.009277[TRAIN] epoch=2, iter=900/10000, loss=0.6407, lr=0.009186[TRAIN] epoch=2, iter=1000/10000, loss=0.6308, lr=0.009095登录后复制 ? ? ? ?
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:238: UserWarning: The dtype of left and right variables are not the same, left dtype is VarType.INT32, but right dtype is VarType.BOOL, the right dtype will convert to VarType.INT32 format(lhs_dtype, rhs_dtype, lhs_dtype))/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:238: UserWarning: The dtype of left and right variables are not the same, left dtype is VarType.INT64, but right dtype is VarType.BOOL, the right dtype will convert to VarType.INT64 format(lhs_dtype, rhs_dtype, lhs_dtype))登录后复制 ? ? ? ?
[EVAL] #Images=1476 mIoU=0.4723 Acc=0.7508[EVAL] The model with the best validation mIoU (0.4723) was saved at iter 1000.[TRAIN] epoch=2, iter=1100/10000, loss=0.6196, lr=0.009004[TRAIN] epoch=2, iter=1200/10000, loss=0.5915, lr=0.008913登录后复制 ? ? ? ?
Corrupt JPEG data: premature end of data segment登录后复制 ? ? ? ?
[TRAIN] epoch=2, iter=1300/10000, loss=0.5889, lr=0.008822[TRAIN] epoch=2, iter=1400/10000, loss=0.5854, lr=0.008731[TRAIN] epoch=3, iter=1500/10000, loss=0.5606, lr=0.008639登录后复制 ? ? ? ?
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9登录后复制登录后复制登录后复制 ? ? ? ?
[TRAIN] epoch=3, iter=1600/10000, loss=0.5642, lr=0.008548登录后复制 ? ? ? ?
通过运行结果可以发现,U-Net在The Oxford-IIIT Pet Dataset上,Loss能有效的下降,经过10000个批次的训练,在验证集上的miou可以达到69%左右。
2.5 模型保存
训练完成后,可以将模型参数保存到磁盘,用于模型推理或继续训练。
In [?]# 保存模型参数paddle.save(model.state_dict(), 'last_model.pdparams')# 保存优化器信息和相关参数,方便继续训练paddle.save(optimizer.state_dict(), 'last_model.pdopt')登录后复制 ? ?
2.6 模型评估
使用保存的模型参数评估在验证集上的准确率,代码实现如下:
In [?]# 开启0号GPUuse_gpu = Truepaddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')print('start evaluation .......')# 实例化模型model = UNet()# 加载模型参数params_file_path=”best_model.pdparams“model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)# 将模型切换到评估模式model.eval()intersect_area_all = 0pred_area_all = 0label_area_all = 0with paddle.no_grad(): for eval_iter, (im, label) in enumerate(valid_loader): label = label.astype('int64') # 运行模型前向计算,得到预测值 pred = model(im)[0] pred = paddle.argmax(pred, axis=1, keepdim=True, dtype='int32') # 计算相交区域、预测区域、标签区域 intersect_area, pred_area, label_area = calculate_area(pred, label, 3, ignore_index=255) intersect_area_all = intersect_area_all + intersect_area pred_area_all = pred_area_all + pred_area label_area_all = label_area_all + label_area# 计算平均iouclass_iou, miou = mean_iou(intersect_area_all, pred_area_all, label_area_all)# 计算准确率class_acc, acc = accuracy(intersect_area_all, pred_area_all)print(”[EVAL] #Images={} mIoU={:.4f} Acc={:.4f}“.format(len(eval_dataset), miou, acc))登录后复制 ? ?
2.7 模型推理及可视化
同样地,也可以使用保存好的模型,对数据集中的某一张图片进行模型推理,观察模型效果,具体代码实现如下:
In [?]# 开启0号GPUuse_gpu = Truepaddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')# 实例化模型model = UNet()# 加载模型参数params_file_path=”best_model.pdparams“model_state_dict = paddle.load(params_file_path)model.load_dict(model_state_dict)model.eval()# 读取test_list.txt中记录的第一张图片的路径及标签with open('/home/aistudio/work/Dataset/predict.txt') as test_file: img_path, label_path = test_file.readline().split(' ')# 读取图片并对图片进行预处理img = transforms(im=img_path, mode='val')[0]# 读取标签图片label = np.asarray(Image.open(label_path.split('n')[0]))# 为图片添加batch维度batch_img = np.expand_dims(img, 0)input_tensor = paddle.to_tensor(batch_img)# 运行模型前向计算,得到预测图片pred = model(input_tensor)[0]# 算法训练时,将标签统一减1,因此需要将最终结果恢复原样pred = paddle.argmax(pred, axis=1, keepdim=True, dtype='int32') + 1pred = pred[0].squeeze().numpy()# 可视化原始图片image = np.asarray(Image.open(img_path))plt.subplot(3, 3, 1)plt.imshow(image)plt.title('Input Image')plt.axis(”off“)# 可视化真实标签图片plt.subplot(3, 3, 2)plt.imshow(label, cmap='gray')plt.title('Label')plt.axis(”off“)# 可视化预测结果图片plt.subplot(3, 3, 3)plt.imshow(pred, cmap='gray')plt.title('Predict')plt.axis(”off“)登录后复制 ? ?
拓展思考:
如果您想预测The Oxford-IIIT Pet Dataset中另外一张图片的类别,只需在“/home/aistudio/work/Dataset/”路径下,打开predict.txt文件,将文件中任意一条数据复制到首行,然后重新执行“模型推理”代码即可。您可以观察下可视化的结果有何不同?
 ? ? ? ?
? ? ? ?3. 实验总结
本次实验使用飞桨框架构建了经典的U-Net图像分割网络,并在The Oxford-IIIT Pet Dataset上实现了宠物图像分割。通过本次实验,您不但掌握了《人工智能导论:模型与算法》- 6.3卷积神经网络(P214-P223)中介绍的相关原理的实践方法,还熟悉了通过开源框架实现深度学习任务的实验流程和代码实现。大家可以在此实验的基础上,尝试开发自己感兴趣的图像分割任务。
4. 实验拓展
- 尝试调整学习率和训练轮数等超参数,观察是否能够得到更高的精度;
- 尝试使用其他算法(FCN、ANN等)实现宠物图像分割任务。
来源:https://www.php.cn/faq/1422396.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-
- 天猫团队被偶遇灵隐寺祈福:求降温卖爆双十一 回应:对 谁说生活没有观众
- 时间:2025-10-14
-
- 星环科技AI Infra平台:重构企业AI基础设施
- 时间:2025-10-14
-

- 每日互动个知·智能工作站GAI Station照进凯文·凯利的“镜像世界”
- 时间:2025-10-14
-

- 容联云亮相迪拜 GITEX 2025 展示数智化出海新范式
- 时间:2025-10-14
-

- 京东联合多方推新车 知情人士:京东将发布新车是广汽埃安UT换电版
- 时间:2025-10-14
-

- 青蒿素问世后治疗数亿人 屠呦呦:希望年轻一代能超越前人
- 时间:2025-10-14
-

- 2025 VDC开发者大会发布多项无障碍功能升级 科技助力构建无障碍生态新范式
- 时间:2025-10-14
-

- 能拍能打绝世有双 努比亚Z80 Ultra街拍游戏机火热预约中
- 时间:2025-10-14
大家都在玩








大家都在看
更多-

- iOS抖音锁屏后如何关闭直播?锁屏后如何继续播放?
- 时间:2025-10-14
-
- Microsoft Teams怎么拒绝调查
- 时间:2025-10-14
-

- 无畏契约男生网名
- 时间:2025-10-14
-

- 快手定时发布的短视频如何取消?定时发布作品会有影响吗?
- 时间:2025-10-14
-

- 抖音的发布日期怎么关掉?发布日期能更改吗?
- 时间:2025-10-14
-

- 年产75万吨!全球最大变压吸附制氢装置群投运
- 时间:2025-10-14
-

- 王牌竞速网名男生
- 时间:2025-10-14
-

- 手机无卡时代来了!中国电信:华为、OPPO等将陆续上市eSIM手机
- 时间:2025-10-14