『AI达人创造营』基于PaddleHub实现常见鱼类分类及微信小程序部署
时间:2025-07-25 | 作者: | 阅读:0本项目针对30种常见鱼类,通过爬取多平台图片形成含1917张图片的数据集,用PaddleHub实现分类并部署到微信小程序。先预处理数据,选ResNet50模型训练,经调参优化,用Momentum优化器、batch_size=8时效果佳。再封装模型为PaddleHub Module,借PaddleHub Serving部署,实现小程序端鱼类识别,后续计划扩充数据集与功能。

基于PaddleHub实现常见鱼类分类及微信小程序部署
针对以上30种常见鱼类进行分类,并部署到微信小程序
一、项目背景
1.1项目由来
1.2微信小程序鱼类识别截图

二、数据集简介
包含30类常见鱼类,合计1917张图片,由于有部分鱼类爬取到的图片数量较少,因此每种鱼类的数据量并不是一致的。友情提示:数据集仅供学习和个人使用30种鱼类中英文对照字典:{'Cuttlefish': '墨鱼', 'Turbot': '多宝鱼', 'Hairtail': '带鱼', 'Grouper': '石斑鱼', 'Saury': '秋刀鱼', 'Octopus': '章鱼', 'Red_fish': '红鱼', 'Tilapia_mossambica': '罗非鱼', 'Variegated_carp': '胖头鱼', 'Grass_Carp': '草鱼', 'Silverfish': '银鱼', 'Herring': '青鱼', 'Horsehead_fish': '马头鱼', 'Squid': '鱿鱼', 'Catfish': '鲇鱼', 'Perch': '鲈鱼', 'Abalone': '鲍鱼', 'Salmon': '鲑鱼', 'Silver_carp': '鲢鱼', 'Carp': '鲤鱼', 'Crucian_carp': '鲫鱼', 'Silvery_pomfret': '鲳鱼', 'Bream': '鲷鱼', 'Plaice': '鲽鱼', 'Parabramis_pekinensis': '鳊鱼', 'Eel': '鳗鱼', 'Yellow_croaker': '黄鱼', 'Ricefield_eel': '黄鳝', 'Snakehead': '黑鱼', 'Bibcock_fish': '龙头鱼'}
2.1.数据加载和预处理
In [1]# 解压缩数据!unzip -oq -d images data/data103322/images.zip登录后复制 ? ? ? ? ? ?In [2]
# 数据加载和预处理import osimport paddleimport numpy as npimport paddlehub.vision.transforms as T# 定义数据集class FishDataset(paddle.io.Dataset): def __init__(self, dataset_dir, transforms, mode='train'): # 数据集存放路径 self.dataset_dir = dataset_dir # 数据增强 self.transforms = transforms # 分类数 self.label_lst = [] self.num_classes= self.get_label() self.mode = mode # 根据mode读取对应的数据集 if self.mode == 'train': self.file = 'train_list.txt' elif self.mode == 'test': self.file = 'test_list.txt' else: self.file = 'validate_list.txt' self.file = os.path.join(self.dataset_dir, self.file) with open(self.file, 'r') as f: self.data = f.read().split('n')[:-1] def get_label(self): # 获取分类数 with open(os.path.join(dataset_dir, 'label_list.txt'), 'r') as f: labels = f.readlines() for idx, label in enumerate(labels): dic = {} dic['label_name'] = label.split('n')[0] dic['label_id'] = idx self.label_lst.append(dic) return len(self.label_lst) def __getitem__(self, idx): img_path, label = self.data[idx].split(' ') img_path = os.path.join(self.dataset_dir, img_path) im = self.transforms(img_path) return im, int(label) def __len__(self): return len(self.data)# 定义数据增强train_Transforms = T.Compose([ T.Resize((256, 256)), T.CenterCrop(224), T.RandomHorizontalFlip(), T.Normalize() ], to_rgb=True)eval_Transforms = T.Compose([ T.Resize((256, 256)), T.CenterCrop(224), T.Normalize() ], to_rgb=True)# 读取数据集dataset_dir = 'images/images'fish_train = FishDataset(dataset_dir, train_Transforms)fish_validate = FishDataset(dataset_dir, eval_Transforms, mode='validate')print('训练集的图片数量: {}'.format(len(fish_train)))print('验证集的图片数量: {}'.format(len(fish_validate)))print('分类数: {}'.format(len(fish_train.label_lst)))登录后复制 ? ? ? ? ? ?In [3]
# label_id转labelid2label = {}for i in fish_train.label_lst: id2label[i['label_id']] = i['label_name']print(id2label)登录后复制 ? ? ? ? ? ?In [4]
# 鱼类英文名转中文en2zh = {'Cuttlefish': '墨鱼', 'Turbot': '多宝鱼', 'Hairtail': '带鱼', 'Grouper': '石斑鱼', 'Saury': '秋刀鱼', 'Octopus': '章鱼', 'Red_fish': '红鱼', 'Tilapia_mossambica': '罗非鱼', 'Variegated_carp': '胖头鱼', 'Grass_Carp': '草鱼', 'Silverfish': '银鱼', 'Herring': '青鱼', 'Horsehead_fish': '马头鱼', 'Squid': '鱿鱼', 'Catfish': '鲇鱼', 'Perch': '鲈鱼', 'Abalone': '鲍鱼', 'Salmon': '鲑鱼', 'Silver_carp': '鲢鱼', 'Carp': '鲤鱼', 'Crucian_carp': '鲫鱼', 'Silvery_pomfret': '鲳鱼', 'Bream': '鲷鱼', 'Plaice': '鲽鱼', 'Parabramis_pekinensis': '鳊鱼', 'Eel': '鳗鱼', 'Yellow_croaker': '黄鱼', 'Ricefield_eel': '黄鳝', 'Snakehead': '黑鱼', 'Bibcock_fish': '龙头鱼'}print(en2zh)登录后复制 ? ? ? ? ? ?
2.2数据集查看
In [6]from PIL import Imageimport matplotlib.pyplot as pltpath = 'images/images/train'plt.figure(figsize=(30, 8))for idx, name in enumerate(en2zh.keys()): for fpath, dirname, fname in os.walk(os.path.join(path, name)): plt.subplot(3, 10, idx+1) img = Image.open(os.path.join(fpath, fname[0])) plt.title(name) plt.imshow(img)登录后复制 ? ? ? ? ? ?
三、模型选择和开发
3.1.模型选择
In [7]import paddlefrom paddle.vision.models import resnet50# 设置pretrained参数为True,可以加载resnet50在imagenet数据集上的预训练模型model = paddle.Model(resnet50(pretrained=True, num_classes=len(fish_train.label_lst)))登录后复制 ? ? ? ? ? ?
3.2模型训练
In [8]from paddle.optimizer import Momentumfrom paddle.regularizer import L2Decayfrom paddle.nn import CrossEntropyLossfrom paddle.metric import Accuracy# 配置优化器optimizer = Momentum(learning_rate=0.001, momentum=0.9, weight_decay=L2Decay(1e-4), parameters=model.parameters())# 进行训练前准备model.prepare(optimizer, CrossEntropyLoss(), Accuracy(topk=(1, 5)))# 启动训练model.fit(fish_train, fish_validate, epochs=50, batch_size=8, save_dir=”./output“)登录后复制 ? ? ? ? ? ?In [9]
if not os.path.exists('final'): os.mkdir('final')# 将final.pdparams复制到final文件夹!cp output/final.pdparams final登录后复制 ? ? ? ? ? ?
3.3模型评估测试
In [10]# 模型评估,根据prepare接口配置的loss和metric进行返回result = model.evaluate(fish_validate)print(result)登录后复制 ? ? ? ? ? ?
3.4.模型预测
In [11]# 批量预测from paddle.static import InputSpec# 加载final模型参数inputs = InputSpec([None, 1*1*3*224*224], 'float32', 'x')labels = InputSpec([None, 30], 'int32', 'x')model = paddle.Model(resnet50(num_classes=len(fish_train.label_lst)), inputs, labels)# 加载模型参数model.load('final/final.pdparams')# 定义优化器optimizer = Momentum(learning_rate=0.001, momentum=0.9, weight_decay=L2Decay(1e-4), parameters=model.parameters())# 进行预测前准备model.prepare(optimizer, CrossEntropyLoss(), Accuracy(topk=(1, 5)))# 加载测试集数据fish_test = FishDataset(dataset_dir, eval_Transforms, mode='test')# 进行预测操作result = model.predict(fish_test)# 定义画图方法def show_img(idx, predict): with open(os.path.join(dataset_dir, 'test_list.txt')) as f: data = f.readlines() plt.figure() print('predict: {}'.format(predict)) img = Image.open(os.path.join(dataset_dir, data[idx].split()[0])) plt.imshow(img) plt.show()# 抽样展示indexs = [2, 15, 38, 100]for idx in indexs: show_img(idx, en2zh[id2label[np.argmax(result[0][idx])]])登录后复制 ? ? ? ? ? ?In [12]
# 单张图片预测# 读取单张图片image = paddle.to_tensor(fish_test[80][0]).reshape([1, 1, 3, 224, 224])image_id = 80# 单张图片预测result = model.predict(image)# 可视化结果show_img(image_id, en2zh[id2label[np.argmax(result)]])登录后复制 ? ? ? ? ? ?
四、基于PaddleHub Serving进行微信小程序部署
内容根据PaddleHub文档教程>如何创建自己的Module改编。文档基于情感分类(NLP)模型,本文基于(CV),开发者可根据需要相互参考。
4.1创建必要的目录和文件
在?/home/aistudio/work?目录下创建?fish_predict?文件夹,并在该目录下分别创建?module.py?__init__.py?,其中?module.py?作为?Module?的入口,用来实现逻辑预测功能。
In [13]! tree work/登录后复制 ? ? ? ? ? ?
4.2. 修改 module.py 文件
hub模型的转换基于我们在此之前写过的代码,通过对其进行包装修饰得到所需的?module.py?文件。
查看module.py代码
4.3 安装模型及预测
在 module.py 中编写好代码后,就可以通过 hub install xxx 的方式来安装模型了!
In [14]!pip install --upgrade paddlehub登录后复制 ? ? ? ? ? ?In [15]
# 安装模型!hub install work/fish_predict/登录后复制 ? ? ? ? ? ?In [16]
# 预测import paddlehub as hubmy_fish_predict = hub.Module(name=”fish_predict“)my_fish_predict.fish_predict('images/images/test/Hairtail/137.jpg')登录后复制 ? ? ? ? ? ?
4.4 终端部署
部署方法:
在终端运行命令?hub serving start -m fish_predict?。如果它出现下面的提示说明部署成功
? ? ? ? ? ? ? ? ? ? ? ?
通过POST请求实现预测
# 通过POST请求实现预测import requestsimport jsonimport cv2import base64def cv2_to_base64(image): data = cv2.imencode('.png', image)[1] return base64.b64encode(data.tobytes()).decode('utf-8')# 发送HTTP请求data = {'img_b64': cv2_to_base64(cv2.imread(”images/images/test/Hairtail/137.jpg“))}headers = {”Content-type“: ”application/json“, ”Connection“: ”close“}url = ”http://0.0.0.0:8866/predict/fish_predict“r = requests.post(url=url, headers=headers, data=json.dumps(data))# 打印预测结果print(r)print(r.json()['results'].encode('utf-8').decode('unicode_escape'))登录后复制 ? ? ? ? ? ?
4.5 部署到微信小程序
- 小程序二维码

- 效果展示

- 相关代码
- 小程序页面js代码
? ? ? ? ? ? ? ? ? ? ? ? ? ?
- 服务端请求云函数代码
? ? ? ? ? ? ? ? ? ? ? ? ? ?
- 小程序页面js代码
五、总结
- 数据集获取
- 初始阶段是通过在百度图片、电商平台搜索关键词,爬取返回的百度图片及产品图片,但是通过这样的方式爬取的图片,经常会在搜索的关键词中返回其他的鱼类
- 后来则通过借鉴百度百科中所介绍的相关鱼类的信息,对爬取的图片进行人工筛选、判断,最终获取到1917张的数据集图片
- 后续考虑需要直接去菜市场对相关鱼类进行现场拍摄,获取更准确、更丰富的数据集图片
- 模型调参
- 在batch_size的选择上,初始选择了32,但是由于本身数据集不是很大,因此发现batch_size为32的训练结果较差,后续将batch_size缩减到8后,模型的收敛速度加快,模型表现也更好
- 在优化器的选择上,选择了SGD、Momentum、Adam、Adagrad进行训练,根据最终训练结果的表现,Momentum更胜一筹,收敛速度及准确率都优于其他的优化器
- 后续进展
- 本次仅针对30种较为常见的鱼类进行了分类识别,后续继续收集菜市场中常见的蔬菜、虾蟹贝类、禽畜等数据集图片,将整个模型扩充到对菜市场常见的产品的识别
- 本次仅训练了分类模型,后续将使用Labelimg对数据集进行数据标注,便于后续训练目标检测模型
- 本次虽然使用了微信小程序进行部署,但是微信小程序的整体页面及功能还是相对比较简陋,后续不仅在对用户传入的图片进行识别后,还应当返回相关的鱼类或其他蔬菜等的科普介绍、热门菜谱等,提升整个小程序的实用性
个人简介
我在AI Studio上获得白银等级,点亮3个徽章,来互关呀~ https://aistudio.baidu.com/aistudio/personalcenter/thirdview/158581
In [?]<br/>登录后复制 ? ? ? ? ? ?

来源:https://www.php.cn/faq/1426865.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-
- 2026特殊符号大全可复制
- 时间:2025-12-11
-
- 1000个特殊符号可复制
- 时间:2025-12-11
-

- 下班后回工作微信属于加班吗 法院明确:算!
- 时间:2025-12-08
-
- 怎么取消微信输入法的记忆功能
- 时间:2025-12-06
-
- 微信输入法怎么设置成繁体字
- 时间:2025-12-06
-
- 怎么消除微信打字时的记忆词组
- 时间:2025-12-06
-
- 怎么用换机助手把微信换到另一个手机上
- 时间:2025-12-06
-
- 微信输入法怎么换皮肤颜色
- 时间:2025-12-06

精选合集
更多大家都在玩








热门话题

大家都在看
更多-
- 想低调发布 陶德再次暗示《辐射3》与《新维加斯》重制版
- 时间:2025-12-15
-
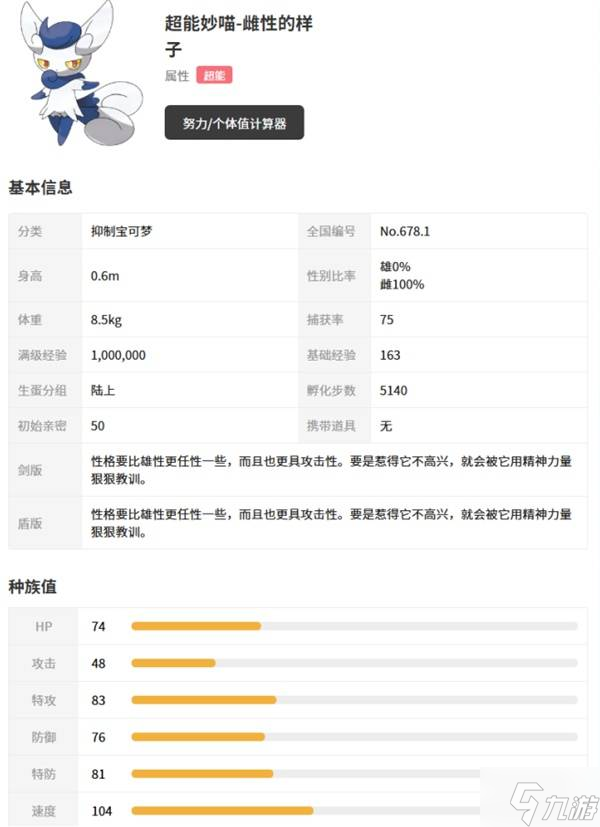
- 《宝可梦传说ZA》超能妙喵及Mega形态介绍 超级超能妙喵种族值介绍
- 时间:2025-12-15
-
- 老外也上头 《燕云十六声》获PlayStation 11月最佳新游戏
- 时间:2025-12-15
-
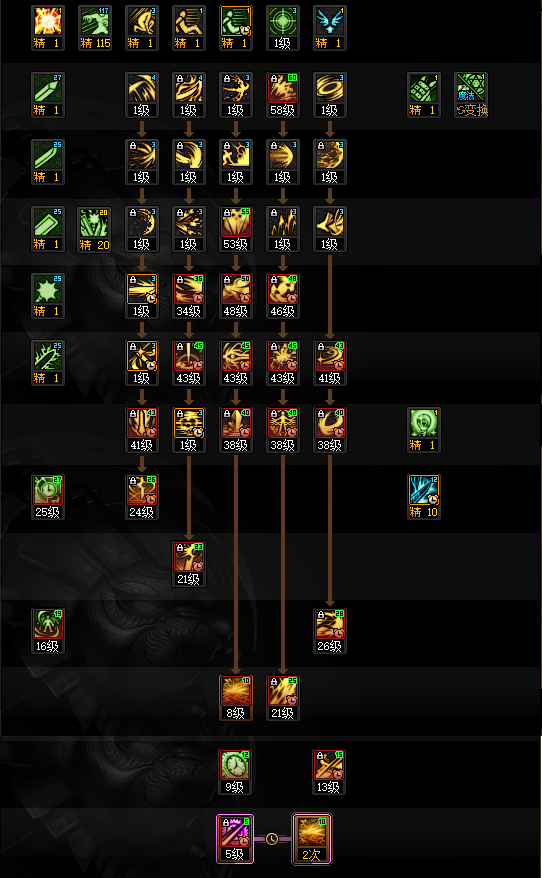
- DNF2026黑暗武士加点攻略
- 时间:2025-12-15
-

- 魔兽世界黑暗院长的玄秘火盆怎么获得
- 时间:2025-12-15
-

- 宝藏骑士好玩吗 宝藏骑士玩法简介
- 时间:2025-12-15
-

- 向僵尸开炮空百和风百宝石优先建议
- 时间:2025-12-15
-
- 《上古卷轴5》PS与NS2平台对比 NS2版本画质提升性能灾难
- 时间:2025-12-15