基于PaddlePaddle的中风患者线性模型训练和预测
时间:2025-07-28 | 作者: | 阅读:0该研究基于PaddlePaddle构建中风患者预测模型。使用含4981条数据的数据集,含性别、年龄等11个特征。先对分类变量序列化、数据标准化,切分训练集(80%)和测试集(20%),通过协相关分析特征关系。构建含全连接层的网络,经6轮训练,训练集正确率约91%,测试集评估正确率87.65%,模型有一定预测能力。

一、基于PaddlePaddle的中风患者线性模型预测
1.背景描述
中风是一种医学疾病,由于流向大脑的血液不足导致细胞死亡。中风主要有两种类型:缺血性中风(缺乏血液流动导致)和出血性中风(出血导致)。两者都会导致大脑的某些部分停止正常运作。
中风的体征和症状可能包括一侧身体无法移动或感觉,理解或说话问题,头晕或一侧视力丧失。症状和体征通常在中风发生后不久就会出现。如果症状持续不到一两个小时,中风就是短暂性脑缺血发作(TIA),也称为小中风。出血性中风还可能伴有严重的头痛。中风的症状可能是永久性的。长期并发症可能包括肺炎和膀胱失控。
中风的主要危险因素是高血压。其他危险因素包括高血胆固醇、吸烟、肥胖、糖尿病、以前的TIA、终末期肾病和心房颤动。
缺血性中风通常是由血管堵塞引起的,尽管也有一些不太常见的原因。出血性中风是由出血直接进入大脑或进入大脑膜之间的空间引起的。
出血可能是由于脑动脉瘤破裂引起的。诊断通常基于身体检查,并辅以医学成像,如CT扫描或MRI扫描。CT扫描可以排除出血,但不一定排除缺血,早期的CT扫描通常不会显示缺血。其他检查,如心电图(ECG)和血液检查,以确定危险因素和排除其他可能的原因。低血糖也可能引起类似的症状。
2.数据说明
《中国成人超重和肥胖症预防控制指南》的BMI分类:
血糖水平正常空腹血糖浓度的预期值介于?70 mg/dL 到 100 mg/dL?之间。
或:3.9 mmol/L 和 5.6 mmol/L 之间
二、数据分析
1.基础分析
In [1]import numpy as npimport pandas as pd登录后复制 ? ?In [2]
data = pd.read_csv('data/data225165/brain_stroke.csv',encoding='gbk')data.head()登录后复制 ? ? ? ?
性别 年龄 是否患有高血压 是否患有心脏病 是否有过婚姻 工作类型 住宅类型 血糖水平 BMI 吸烟状况 是否中风0 男性 67.0 0 1 1 私人企业 城市 228.69 36.6 以前吸烟 11 男性 80.0 0 1 1 私人企业 农村 105.92 32.5 从不吸烟 12 女性 49.0 0 0 1 私人企业 城市 171.23 34.4 吸烟 13 女性 79.0 1 0 1 自雇人士 农村 174.12 24.0 从不吸烟 14 男性 81.0 0 0 1 私人企业 城市 186.21 29.0 以前吸烟 1登录后复制登录后复制 ? ? ? ? ? ? ? ?In [3]
data[data.duplicated()]登录后复制 ? ? ? ?
Empty DataFrameColumns: [性别, 年龄, 是否患有高血压, 是否患有心脏病, 是否有过婚姻, 工作类型, 住宅类型, 血糖水平, BMI, 吸烟状况, 是否中风]Index: []登录后复制 ? ? ? ? ? ? ? ?In [4]
data.isnull().sum()登录后复制 ? ? ? ?
性别 0年龄 0是否患有高血压 0是否患有心脏病 0是否有过婚姻 0工作类型 0住宅类型 0血糖水平 0BMI 0吸烟状况 0是否中风 0dtype: int64登录后复制 ? ? ? ? ? ? ? ?In [5]
data.shape登录后复制 ? ? ? ?
(4981, 11)登录后复制 ? ? ? ? ? ? ? ?In [6]
# 判断data中各个字段的取值是否与数据字典中一致# 以及判断是否存在额外的空值,如空格表示的空值for column in data.columns: print(column + ”:“ + str(data[column].unique()))登录后复制 ? ? ? ?
性别:['男性' '女性']年龄:[6.70e+01 8.00e+01 4.90e+01 7.90e+01 8.10e+01 7.40e+01 6.90e+01 7.80e+01 6.10e+01 5.40e+01 5.00e+01 6.40e+01 7.50e+01 6.00e+01 7.10e+01 5.20e+01 8.20e+01 6.50e+01 5.70e+01 4.20e+01 4.80e+01 7.20e+01 5.80e+01 7.60e+01 3.90e+01 7.70e+01 6.30e+01 7.30e+01 5.60e+01 4.50e+01 7.00e+01 5.90e+01 6.60e+01 4.30e+01 6.80e+01 4.70e+01 5.30e+01 3.80e+01 5.50e+01 4.60e+01 3.20e+01 5.10e+01 1.40e+01 3.00e+00 8.00e+00 3.70e+01 4.00e+01 3.50e+01 2.00e+01 4.40e+01 2.50e+01 2.70e+01 2.30e+01 1.70e+01 1.30e+01 4.00e+00 1.60e+01 2.20e+01 3.00e+01 2.90e+01 1.10e+01 2.10e+01 1.80e+01 3.30e+01 2.40e+01 3.60e+01 6.40e-01 3.40e+01 4.10e+01 8.80e-01 5.00e+00 2.60e+01 3.10e+01 7.00e+00 1.20e+01 6.20e+01 2.00e+00 9.00e+00 1.50e+01 2.80e+01 1.00e+01 1.80e+00 3.20e-01 1.08e+00 1.90e+01 6.00e+00 1.16e+00 1.00e+00 1.40e+00 1.72e+00 2.40e-01 1.64e+00 1.56e+00 7.20e-01 1.88e+00 1.24e+00 8.00e-01 4.00e-01 8.00e-02 1.48e+00 5.60e-01 1.32e+00 1.60e-01 4.80e-01]是否患有高血压:[0 1]是否患有心脏病:[1 0]是否有过婚姻:[1 0]工作类型:['私人企业' '自雇人士' '政府部门' '儿童']住宅类型:['城市' '农村']血糖水平:[228.69 105.92 171.23 ... 191.15 95.02 83.94]BMI:[36.6 32.5 34.4 24. 29. 27.4 22.8 24.2 29.7 36.8 27.3 28.2 30.9 37.5 25.8 37.8 22.4 48.9 26.6 27.2 23.5 28.3 44.2 25.4 22.2 30.5 26.5 33.7 23.1 32. 29.9 23.9 28.5 26.4 20.2 33.6 38.6 39.2 27.7 31.4 36.5 33.2 32.8 40.4 25.3 30.2 47.5 20.3 30. 28.9 28.1 31.1 21.7 27. 24.1 45.9 44.1 22.9 29.1 32.3 41.1 25.6 29.8 26.3 26.2 29.4 24.4 28. 28.8 34.6 19.4 30.3 41.5 22.6 27.1 31.3 31. 31.7 35.8 28.4 20.1 26.7 38.7 34.9 25. 23.8 21.8 27.5 24.6 32.9 26.1 31.9 34.1 36.9 37.3 45.7 34.2 23.6 22.3 37.1 45. 25.5 30.8 37.4 34.5 27.9 29.5 46. 42.5 35.5 26.9 45.5 31.5 33. 23.4 30.7 20.5 21.5 40. 28.6 42.2 29.6 35.4 16.9 26.8 39.3 32.6 35.9 21.2 42.4 40.5 36.7 29.3 19.6 18. 17.6 17.7 35. 22. 39.4 19.7 22.5 25.2 41.8 23.7 24.5 31.2 16. 31.6 25.1 24.8 18.3 20. 19.5 36. 35.3 40.1 43.1 21.4 34.3 27.6 16.5 24.3 25.7 21.9 38.4 25.9 18.6 24.9 48.2 20.7 39.5 23.3 35.1 43.6 21. 47.3 16.6 21.6 15.5 35.6 16.7 41.9 16.4 17.1 29.2 37.9 44.6 39.6 40.3 41.6 39. 23.2 18.9 36.1 36.3 46.5 16.8 46.6 35.2 20.9 31.8 15.3 38.2 45.2 17. 27.8 23. 22.1 26. 44.3 39.7 34.7 21.3 41.2 34.8 19.2 35.7 40.8 24.7 19. 32.4 34. 28.7 32.1 20.4 30.6 19.3 40.9 17.2 16.1 16.2 40.6 18.4 21.1 42.3 32.2 17.5 42.1 47.8 20.8 30.1 17.3 36.4 36.2 14.4 43. 41.7 33.8 43.9 22.7 18.7 37. 38.5 16.3 44. 32.7 40.2 33.3 17.4 41.3 14.6 17.8 46.1 33.1 18.1 43.8 38.9 43.7 39.9 15.9 19.8 38.3 41. 42.6 43.4 15.1 20.6 33.5 43.2 19.1 30.4 38. 33.4 44.9 44.7 37.6 39.8 42. 37.2 42.8 18.8 42.9 14.3 37.7 48.4 46.2 43.3 33.9 18.5 44.5 45.4 19.9 17.9 15.6 15.2 18.2 48.5 14.1 15.7 44.8 38.1 44.4 38.8 39.1 41.4 14.2 15.4 45.1 48.7 42.7 48.8 15.8 45.3 14.8 40.7 48. 46.8 48.3 14.5 15. 47.4 47.9 45.8 47.6 14. 46.4 46.9 47.1 48.1 46.3 14.9]吸烟状况:['以前吸烟' '从不吸烟' '吸烟' '不详']是否中风:[1 0]登录后复制 ? ? ? ?
三、特征处理
1.特征分类变量序列化
In [7]data.head()登录后复制登录后复制登录后复制 ? ? ? ?
性别 年龄 是否患有高血压 是否患有心脏病 是否有过婚姻 工作类型 住宅类型 血糖水平 BMI 吸烟状况 是否中风0 男性 67.0 0 1 1 私人企业 城市 228.69 36.6 以前吸烟 11 男性 80.0 0 1 1 私人企业 农村 105.92 32.5 从不吸烟 12 女性 49.0 0 0 1 私人企业 城市 171.23 34.4 吸烟 13 女性 79.0 1 0 1 自雇人士 农村 174.12 24.0 从不吸烟 14 男性 81.0 0 0 1 私人企业 城市 186.21 29.0 以前吸烟 1登录后复制登录后复制 ? ? ? ? ? ? ? ?In [8]
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()登录后复制 ? ?In [9]
# 除去序号列columns=data.columnsprint(len(columns))for column in columns: print(column)登录后复制 ? ? ? ?
11性别年龄是否患有高血压是否患有心脏病是否有过婚姻工作类型住宅类型血糖水平BMI吸烟状况是否中风登录后复制 ? ? ? ?In [10]
label_colum_encoder = ['性别', '工作类型', '住宅类型', '吸烟状况' ]登录后复制 ? ?In [11]
for column in label_colum_encoder: print(f”完成 {column} 列序列化“) data[column]=le.fit_transform(data[column])登录后复制 ? ? ? ?
完成 性别 列序列化完成 工作类型 列序列化完成 住宅类型 列序列化完成 吸烟状况 列序列化登录后复制 ? ? ? ?In [12]
data.head()登录后复制登录后复制登录后复制 ? ? ? ?
性别 年龄 是否患有高血压 是否患有心脏病 是否有过婚姻 工作类型 住宅类型 血糖水平 BMI 吸烟状况 是否中风0 1 67.0 0 1 1 2 1 228.69 36.6 2 11 1 80.0 0 1 1 2 0 105.92 32.5 1 12 0 49.0 0 0 1 2 1 171.23 34.4 3 13 0 79.0 1 0 1 3 0 174.12 24.0 1 14 1 81.0 0 0 1 2 1 186.21 29.0 2 1登录后复制 ? ? ? ? ? ? ? ?
2.数据标准化
In [13]columns=['年龄','工作类型','血糖水平','BMI','吸烟状况']for column in columns: col = data[column] col_min = col.min() col_max = col.max() normalized = (col - col_min) / (col_max - col_min) data[column] = normalized登录后复制 ? ?In [14]
data.head()登录后复制登录后复制登录后复制 ? ? ? ?
性别 年龄 是否患有高血压 是否患有心脏病 是否有过婚姻 工作类型 住宅类型 血糖水平 BMI � 1 0.816895 0 1 1 0.666667 1 0.801265 0.647564 1 1 0.975586 0 1 1 0.666667 0 0.234512 0.530086 2 0 0.597168 0 0 1 0.666667 1 0.536008 0.584527 3 0 0.963379 1 0 1 1.000000 0 0.549349 0.286533 4 1 0.987793 0 0 1 0.666667 1 0.605161 0.429799 吸烟状况 是否中风 0 0.666667 1 1 0.333333 1 2 1.000000 1 3 0.333333 1 4 0.666667 1登录后复制 ? ? ? ? ? ? ? ?
3.数据集切分
In [15]from sklearn.model_selection import train_test_split# 切分数据集为 训练集 、 测试集train, test = train_test_split(data, test_size=0.2, random_state=2023)登录后复制 ? ?
3.协相关
In [16]data.corr()登录后复制 ? ? ? ?
性别 年龄 是否患有高血压 是否患有心脏病 是否有过婚姻 工作类型 住宅类型 性别 1.000000 -0.026538 0.021485 0.086476 -0.028971 -0.075975 -0.004301 年龄 -0.026538 1.000000 0.278120 0.264852 0.677137 0.583042 0.017155 是否患有高血压 0.021485 0.278120 1.000000 0.111974 0.164534 0.140098 -0.004755 是否患有心脏病 0.086476 0.264852 0.111974 1.000000 0.114765 0.108356 0.002125 是否有过婚姻 -0.028971 0.677137 0.164534 0.114765 1.000000 0.455567 0.008191 工作类型 -0.075975 0.583042 0.140098 0.108356 0.455567 1.000000 0.004053 住宅类型 -0.004301 0.017155 -0.004755 0.002125 0.008191 0.004053 1.000000 血糖水平 0.055796 0.236763 0.170028 0.166847 0.150724 0.100118 0.001346 BMI -0.012093 0.373703 0.158762 0.060926 0.371690 0.378679 0.013185 吸烟状况 -0.000653 0.305230 0.104703 0.085429 0.287190 0.318605 0.026798 是否中风 0.008870 0.246478 0.131965 0.134610 0.108398 0.091301 0.016494 血糖水平 BMI 吸烟状况 是否中风 性别 0.055796 -0.012093 -0.000653 0.008870 年龄 0.236763 0.373703 0.305230 0.246478 是否患有高血压 0.170028 0.158762 0.104703 0.131965 是否患有心脏病 0.166847 0.060926 0.085429 0.134610 是否有过婚姻 0.150724 0.371690 0.287190 0.108398 工作类型 0.100118 0.378679 0.318605 0.091301 住宅类型 0.001346 0.013185 0.026798 0.016494 血糖水平 1.000000 0.186348 0.079654 0.133227 BMI 0.186348 1.000000 0.245660 0.056926 吸烟状况 0.079654 0.245660 1.000000 0.054793 是否中风 0.133227 0.056926 0.054793 1.000000登录后复制 ? ? ? ? ? ? ? ?In [17]
import matplotlib.pyplot as plt%matplotlib inlineimport seaborn as snssns.set_style('whitegrid')# 热力图plt.figure(figsize=(20,12))sns.heatmap(train.corr(), annot=True)登录后复制 ? ? ? ?
<matplotlib.axes._subplots.AxesSubplot at 0x7f3592d83dd0>登录后复制 ? ? ? ? ? ? ? ?
<Figure size 2000x1200 with 2 Axes>登录后复制 ? ? ? ? ? ? ? ?
四、模型训练
1.网络定义
In [18]import paddleimport paddle.nn.functional as F# 定义动态图class Net(paddle.nn.Layer): def __init__(self): super(Net, self).__init__() # 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数 self.fc = paddle.nn.Linear(in_features=10,out_features=2) # 网络的前向计算函数 def forward(self, inputs): pred = self.fc(inputs) return pred登录后复制 ? ?In [19]
net=Net()登录后复制 ? ?
2.超参设置
In [20]# 设置迭代次数epochs = 6# paddle.nn.loss.CrossEntropyLoss正常# paddle.nn.CrossEntropyLoss不正常loss_func = paddle.nn.CrossEntropyLoss()#优化器opt = paddle.optimizer.Adam(learning_rate=0.1,parameters=net.parameters())登录后复制 ? ?
3.模型训练
In [21]#训练程序for epoch in range(epochs): all_acc = 0 for i in range(train.shape[0]): x = paddle.to_tensor([train.iloc[i,:-1]]) y = paddle.to_tensor([train.iloc[i,-1]]) infer_y = net(x) loss = loss_func(infer_y,y) loss.backward() y=label = paddle.to_tensor([y], dtype=”int64“) acc= paddle.metric.accuracy(infer_y, y) all_acc=all_acc+acc.numpy() opt.step() opt.clear_gradients#清除梯度 # print(”epoch: {}, loss is: {},acc is:{}“.format(epoch, loss.numpy(),acc.numpy())) #由于输出过长,这里注释掉了 print(”第{}次正确率为:{}“.format(epoch+1,all_acc/i))登录后复制 ? ? ? ?
第1次正确率为:[0.906352]第2次正确率为:[0.913884]第3次正确率为:[0.9131308]第4次正确率为:[0.9131308]第5次正确率为:[0.9199096]第6次正确率为:[0.9113733]登录后复制 ? ? ? ?
五、模型评估
1.评估
In [22]#测试集数据运行net.eval()#模型转换为测试模式all_acc = 0for i in range(test.shape[0]): x = paddle.to_tensor([test.iloc[i,:-1]]) y = paddle.to_tensor([test.iloc[i,-1]]) infer_y = net(x) y=label = paddle.to_tensor([y], dtype=”int64“) # 计算损失与精度 loss = loss_func(infer_y, y) acc = paddle.metric.accuracy(infer_y, y) all_acc = all_acc+acc.numpy() # 打印信息 #print(”loss is: {}, acc is: {}“.format(loss.numpy(), acc.numpy()))print(”测试集正确率:{}“.format(all_acc/i))登录后复制 ? ? ? ?
测试集正确率:[0.87650603]登录后复制 ? ? ? ?
2.预测
In [23]#预测结果展示net.eval()x = paddle.to_tensor([test.iloc[0,:-1]])y = paddle.to_tensor([test.iloc[0,-1]]) infer_y = net(x)y=label = paddle.to_tensor([y], dtype=”int64“)# 计算损失与精度loss = loss_func(infer_y, y)# 打印信息print(”test[0] is :{}n y_test[0] is :{}n predict is {}“.format(test.iloc[0,:-1] ,test.iloc[0,-1], np.argmax(infer_y.numpy()[0])))登录后复制 ? ? ? ?
test[0] is :性别 0.000000年龄 0.218750是否患有高血压 0.000000是否患有心脏病 0.000000是否有过婚姻 0.000000工作类型 0.666667住宅类型 1.000000血糖水平 0.202613BMI 0.329513吸烟状况 0.666667Name: 4121, dtype: float64 y_test[0] is :0 predict is 0登录后复制 ? ? ? ?
来源:https://www.php.cn/faq/1428336.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- 宗馥莉离职原因曝光:“娃哈哈”商标使用出现问题 将全力打造新品牌 “娃小宗”
- 时间:2025-10-12
-
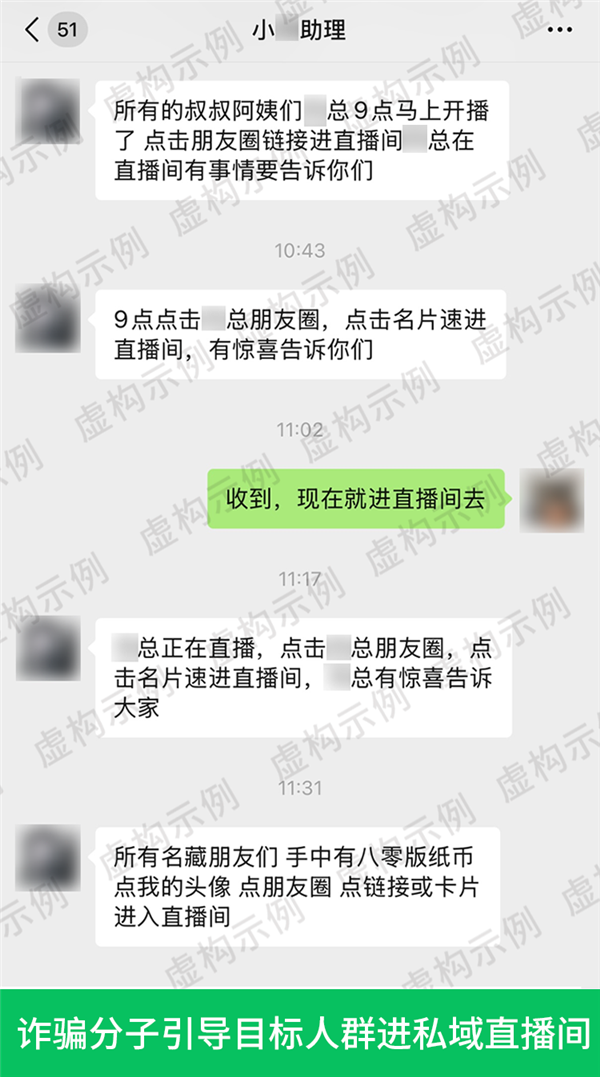
- “专家鉴定+高价回收”竟是骗局 私域直播间让收藏者血本无归
- 时间:2025-10-12
-
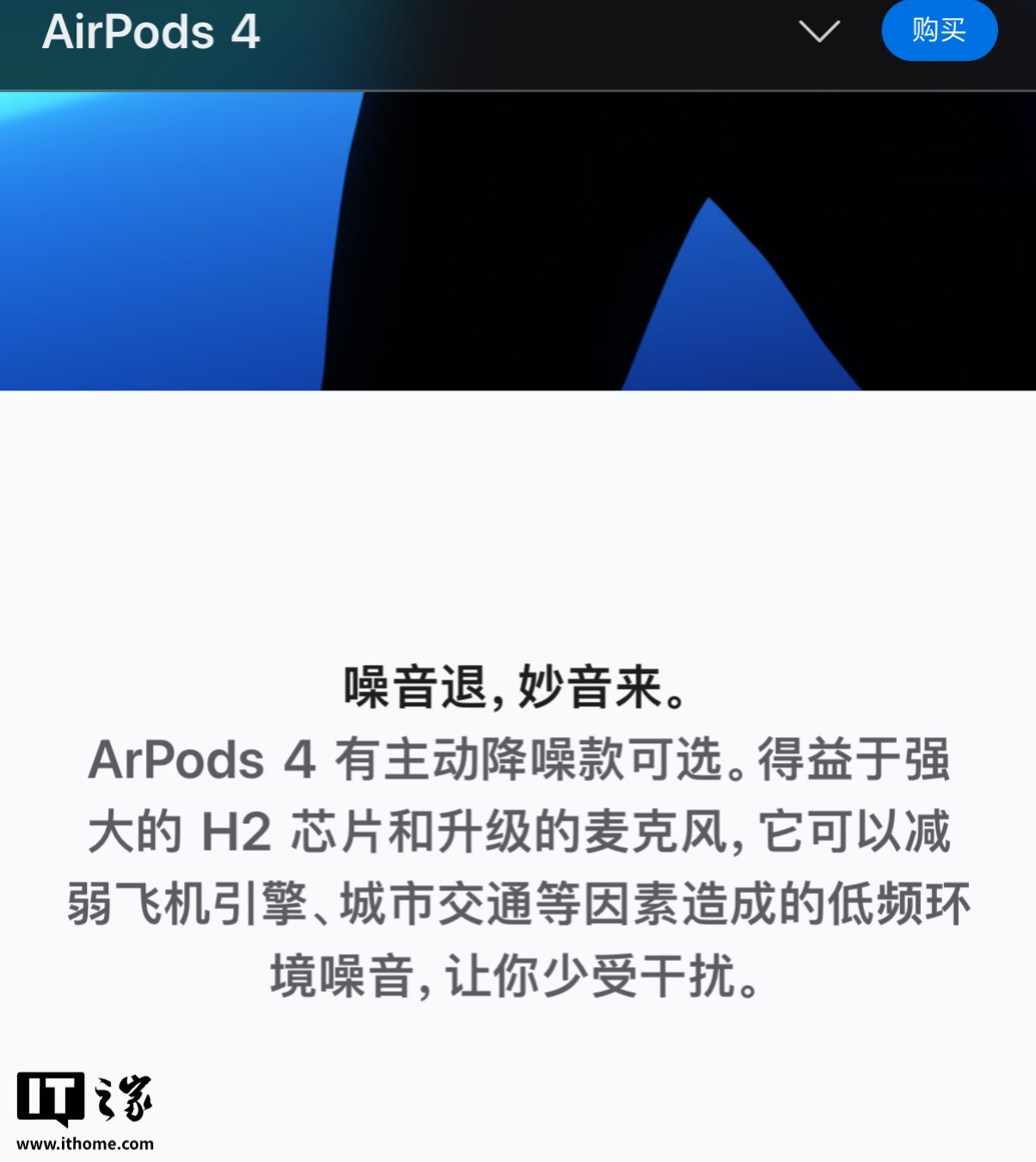
- 苹果官网出现“错别字”上热搜,AirPods 拼成“ArPods”
- 时间:2025-10-12
-

- 山航空姐全面换穿平底鞋:可自由选择裙装或裤装
- 时间:2025-10-12
-

- 白色超频利器 华硕B850M AYW OC主板预约中!
- 时间:2025-10-11
-

- 共谋业务智胜之道 2025 VDC互联网技术分会引关注
- 时间:2025-10-11
-

- 节能智能双王炸!追觅省电神机E-Wind智省PRO携黑科技定义舒适新标准
- 时间:2025-10-11
-
- 互联网法院管辖范围有调整,最新司法解释 11 月 1 日起施行
- 时间:2025-10-11

大家都在玩








大家都在看
更多-
- IDM下载器怎么设置限速
- 时间:2025-10-11
-
- IDM下载器如何设置线程数量
- 时间:2025-10-11
-

- 网球宝贝游戏名字
- 时间:2025-10-11
-

- 怎样删除抖音评论的回复?删除抖音评论的回复能看到吗?
- 时间:2025-10-11
-

- 短视频平台引流方法是什么?平台引流违法吗?
- 时间:2025-10-11
-

- 如何批量删除快手发布的作品?批量删除快手发布的作品会怎样?
- 时间:2025-10-11
-

- 抖音商品链接怎么复制?它的商品链接要怎么挂上去?
- 时间:2025-10-11
-

- 多账号矩阵该如何打造?矩阵带来的好处和价值是什么?
- 时间:2025-10-11