Step 3— 阶跃星辰最新推出的多模态推理模型
时间:2025-07-29 | 作者: | 阅读:0Step 3是什么
step 3 是阶跃星辰推出的全新一代基础大模型,专为推理时代打造,兼具卓越性能与极佳成本效益。该模型采用 moe 架构,总参数量达 321b,激活参数量为 38b,是全球首个全尺寸、原生支持多模态推理的大模型,具备出色的视觉理解与复杂逻辑推理能力,可广泛应用于多个领域。依托 afd 分布式推理系统 与 mfa 注意力机制,显著提升了推理效率。在国产芯片上,其推理速度可达同类模型的 3 倍;在 nvidia hopper 架构芯片上,吞吐量提升超过 70%,大幅降低部署成本。step 3 将于 7 月 31 日 正式开源,向全球开发者和企业免费开放,提供目前最强劲的多模态推理能力。
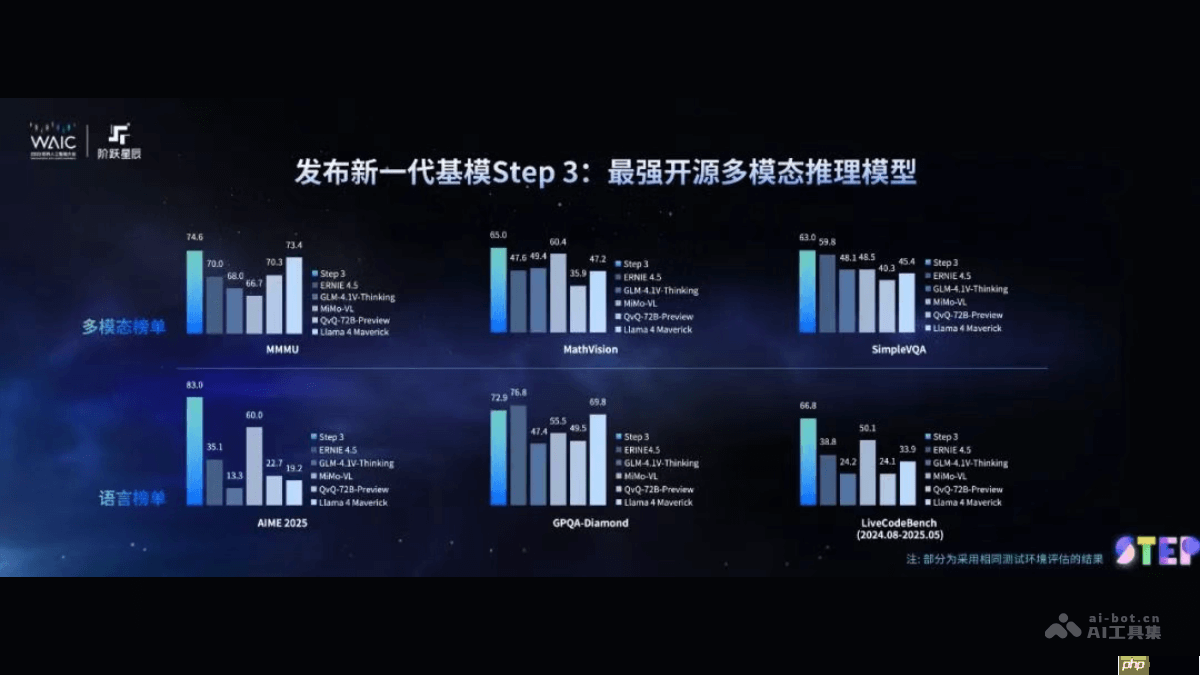
- 视觉感知能力:能够精准识别并解析图像和视频中的复杂信息,即便在极端反光或模糊的菜单识别场景中,也能准确还原文字内容。
- 复杂逻辑推理:支持跨模态、跨领域的知识整合与推理,例如结合微信群聊天记录与纸质消费小票,自动完成 AA 制费用分摊计算。
- 多模态任务处理:作为原生多模态模型,Step 3 可同时处理文本、图像等多种输入形式,灵活应对多样化的实际应用需求。
- 高效推理性能:通过系统级优化,在国产硬件平台上推理效率最高可达 DeepSeek-R1 的 300%;在 NVIDIA Hopper 架构 GPU 上,吞吐量提升超 70%。
- 广泛硬件适配性:兼容主流及国产芯片平台,显著降低推理部署成本,提升计算资源利用率。
Step 3的技术原理
- MoE 架构设计:Step 3 使用 MoE(Mixture of Experts)结构,将模型划分为多个专业化的“专家”子网络,根据输入内容动态激活最合适的子集,实现高效并行计算,在保障性能的同时减少算力浪费。
- AFD 分布式推理系统:创新性地将注意力(Attention)与前馈网络(FFN)模块分配至不同特性的硬件集群执行:
- Attention 模块:交由内存带宽更高的 GPU 集群处理,缓解带宽瓶颈;
- FFN 模块:由高算力 GPU 集群执行,充分发挥其计算优势。
- MFA 注意力机制:针对主流及国产芯片的硬件特性优化算术强度,提升注意力计算效率,实现跨平台高性能推理。
Step 3的项目地址
- GitHub 仓库:https://www.php.cn/link/d2669f6dd645e4881e07eb89a00afa98
Step 3的应用场景
- 智能终端 Agent:可集成于各类 IoT 设备中,如智能家居、可穿戴设备等,提供语音交互与视觉识别能力,打造更智能的用户体验。
- 金融与财经领域:适用于风险评估、智能客服、市场趋势预测等场景,利用多模态数据分析提升决策准确性。
- 内容创作辅助:帮助创作者生成图文并茂的广告文案、视频脚本等内容,提升创意效率与产出质量。
- 视觉识别任务:胜任高难度视觉任务,如反光菜单识别、图像分类、物体检测等,广泛用于餐饮、零售等行业。
- 复杂推理应用:支持多源信息融合推理,例如结合社交聊天记录与消费凭证,自动完成费用结算。
- 自然语言处理:在文本理解与生成任务中表现优异,可应用于问答系统、文档摘要、翻译等多种 NLP 场景。

来源:https://www.php.cn/faq/1430029.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- nef 格式图片降噪处理用什么工具 效果如何
- 时间:2025-07-29
-

- 邮箱长时间未登录被注销了能恢复吗?
- 时间:2025-07-29
-

- Outlook收件箱邮件不同步怎么办?
- 时间:2025-07-29
-

- 为什么客户端收邮件总是延迟?
- 时间:2025-07-29
-

- 一英寸在磁带宽度中是多少 老式设备规格
- 时间:2025-07-29
-

- 大卡和年龄的关系 不同年龄段热量需求
- 时间:2025-07-29
-

- jif 格式是 gif 的变体吗 现在还常用吗
- 时间:2025-07-29
-

- hdr 格式图片在显示器上能完全显示吗 普通显示器有局限吗
- 时间:2025-07-29
精选合集
更多大家都在玩











大家都在看
更多-
- 盐言故事:2026开年已售出百部版权
- 时间:2026-03-02
-

- 数毛社测试《红色沙漠》PC版 2026年图形新标杆
- 时间:2026-03-02
-

- 票房大卖王怎么获取五星剧本章节
- 时间:2026-03-02
-

- 流放之路2白武僧中配冰击电打BD怎么搭配
- 时间:2026-03-02
-

- 高级浪漫氛围感男生网名(精选100个)
- 时间:2026-03-02
-

- 都市加点唯我超凡下载地址在哪
- 时间:2026-03-02
-
- 梦幻西游怎么解绑将军令2026
- 时间:2026-03-02
-

- 白嫖符号网名男生可爱(精选100个)
- 时间:2026-03-02