微云全息推出基于DeepSeek V2.5的数据库自动降维技术
时间:2025-11-28 | 作者: | 阅读:0微云全息推出一项基于模式匹配和合并技术的数据库自动降维方法,旨在通过优化数据结构、减少数据冗余,显著提升数据库的处理效率和数据检索的便捷性。该方法利用DeepSeek V2.5 API进行96次聚类算法与语义相似性评价的集成试验,结合词频逆文档频率(TF-IDF)矢量化和句子变换器嵌入技术,实现了高效的数据库降维。
在技术实现方面,微云全息的方法首先通过TF-IDF矢量化与句子变换器嵌入技术对数据进行特征提取。TF-IDF矢量化通过计算词频和逆文档频率,有效捕捉数据中的关键信息;而句子变换器嵌入则利用深度学习模型将文本数据转换为高维向量,进一步捕捉语义信息。随后,该方法利用DeepSeek V2.5 API进行聚类算法与语义相似性评估的集成试验,通过将语义上相似的数据表进行分组,减少了数据表的数量,并通过计算数据表之间的相似性得分优化聚类结果。实验过程中,微云全息应用了不同的相似性阈值(0.7、0.8、0.9)来评估其对表合并性能的影响。结果显示,随着相似性阈值的提高,表合并的精度和召回率均有所提升,特别是在相似性阈值为0.9时,F1得分达到了1.00,表明该方法在高相似性阈值下能够实现极高的合并精度。
在性能评估方面,微云全息采用调整后的兰德指数(ARI)、归一化互信息(NMI)、精确度、召回率和F1分数等指标对降维效果进行了全面评估。实验结果表明,句子变换器嵌入在聚类性能方面优于TF-IDF矢量化,在仅聚类的情况下,F1分数从大约0.51-0.87增加到了0.51-0.95。此外,通过聚类算法的应用,表对比较的数量减少了77%至83%,显著降低了计算复杂度。DeepSeek V2.5展示了其在匹配和量化细微语义差异方面的潜力,能够在高相似性阈值下保持较高的合并精度。
微云全息的这一技术更新主要体现在DeepSeek V2.5的语义匹配功能和句子变换器嵌入技术的应用上。DeepSeek V2.5通过其强大的语义匹配能力,能够有效识别和量化数据表之间的细微语义差异,从而在高维数据处理中保持较高的合并精度和效率。与传统的TF-IDF矢量化相比,句子变换器嵌入技术能够更好地捕捉数据中的语义信息,从而显著提升聚类效果。此外,该方法通过将数据表数量从113个压缩至13-16个表组,不仅减少了数据存储的需求,还大幅提升了数据检索和分析的效率。
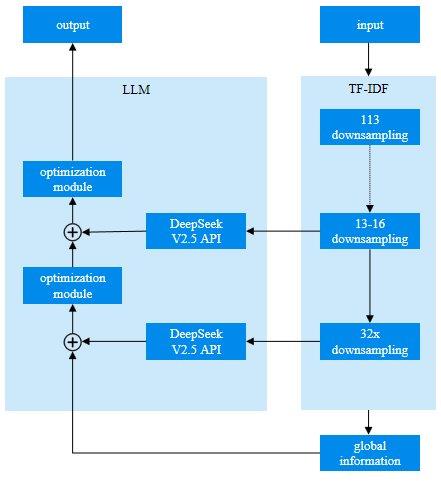
微云全息的数据库自动降维方法具有广泛的应用潜力。该方法能够显著提升数据库的处理效率,适用于需要处理大规模数据的企业和研究机构。同时,通过优化数据结构,该方法能够与大型语言模型(LLM)等高级分析工具兼容,支持更复杂的数据分析任务。此外,该方法还可应用于金融、医疗、电子商务等多个行业,促进更高效、更准确的数据分析工作流程。
微云全息基于DeepSeek V2.5的数据库自动降维方法通过结合模式匹配和语义相似性评估,实现了高效的数据库降维。该方法在特征提取、聚类算法、相似性阈值选择等方面进行了优化,显著提升了数据处理效率和数据质量。该方法在高相似性阈值下能够实现极高的合并精度,未来有望在更多领域得到广泛应用,推动数据分析技术的进一步发展。

来源:https://news.mydrivers.com/1/1089/1089376.htm
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- 精准狙击仿冒客服诈骗 抖音验证助手新增会员验证功能
- 时间:2025-11-28
-
- QNX携手芯驰科技 以新一代X10芯片赋能座舱未来
- 时间:2025-11-28
-

- 海信如何定义“100寸电视性价比之王”
- 时间:2025-11-28
-

- 硬核实力再获认可!睿数信息RayZoom G100获2025世界VR产业大会“虚拟现实产业优秀创新成果”荣誉
- 时间:2025-11-28
-

- 研发周期斩半 成本直降30%!曙光超智融合革新汽车研发仿真
- 时间:2025-11-28
-

- 工信部首批领航级智能工厂 家电业海尔排第一
- 时间:2025-11-28
-

- 文化养老 因AI生动:梨花教育开启文化素养智慧服务新程
- 时间:2025-11-28
-
- AI重构财税价值版图 慧算账以垂直领域大模型引领行业升级
- 时间:2025-11-28

大家都在玩











大家都在看
更多-

- 高人气的大型枪战单机游戏大全?必玩的枪战手游下载分享2025
- 时间:2025-11-28
-

- 滴滴出行被审查,审查期间停止新用户注册
- 时间:2025-11-28
-
- 《魔兽争霸3 重制版》暗夜精灵对战不死族指南-全面解析兵种与玩法
- 时间:2025-11-28
-

- 2025最火的游戏排行榜大全
- 时间:2025-11-28
-
- DNF11.26职业改版魔道技能数据表
- 时间:2025-11-28
-

- 绝地求生怎么抬枪 超全面抬枪指南从原理到实战一网打尽
- 时间:2025-11-28
-
- 三角洲行动s7全面战场M14改枪方案
- 时间:2025-11-28
-

- 2025公测的大型网游有哪些
- 时间:2025-11-28