NVIDIA要用上X3D堆叠设计!下代Feynman GPU将引入LPU
时间:2025-12-29 | 作者: | 阅读:012月29日消息,虽然NVIDIA目前在AI训练领域无可匹敌,但面对日益增长的即时推理需求,其正筹划一项足以改变行业格局的“秘密武器”。
据AGF透露,NVIDIA计划在2028年推出的Feynman(费曼)架构GPU中,整合来自Groq公司的LPU(语言处理单元),以大幅提升AI推理性能。
Feynman架构将接替Rubin架构,采用台积电最先进的A16(1.6nm)制程,为了突破半导体物理限制,NVIDIA计划利用台积电的SoIC混合键合技术,将专为推理加速设计的LPU单元直接堆叠在GPU之上。

这种设计类似于AMD的3D V-Cache技术,但NVIDIA堆叠的不是普通缓存,而是专为推理加速设计的LPU单元。
设计的核心逻辑在于解决SRAM的微缩困境,在1.6nm这种极致工艺下,直接在主芯片集成大量SRAM成本极高且占用空间。
通过堆叠技术,NVIDIA可以将运算核心留在主芯片,而将需要大量面积的SRAM独立成另一层芯片堆叠上去。
台积电的A16制程一大特色是支持背面供电技术,这项技术可以腾出芯片正面的空间,专供垂直信号连接,确保堆叠的LPU能以极低功耗进行高速数据交换。
结合LPU的“确定性”执行逻辑,未来的NVIDIA GPU在处理即时AI响应(如语音对话、实时翻译)时,速度将实现质的飞跃。
不过这也存在两大潜在挑战,分别是散热问题和CUDA兼容性难题,在运算密度极高的GPU 再加盖一层芯片,如何避免“热当机”是工程团队的头号难题。
同时LPU强调“确定性”执行顺序,需要精确的内存配置,而CUDA生态则是基于硬件抽象化设计的,要让这两者完美协同,需要顶级的软件优化。


来源:https://news.mydrivers.com/1/1095/1095424.htm
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- NVIDIA最深的护城河要凉!AMD放言:CUDA已不值一提
- 时间:2026-07-24
-

- 等等党彻底输了!NVIDIA显卡全线调涨价格:GDDR7和GDDR6无一幸免
- 时间:2026-07-23
-
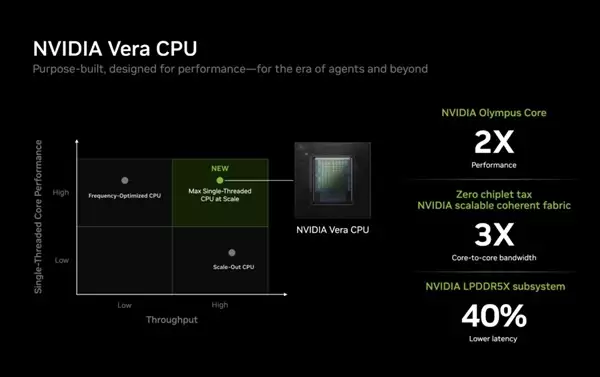
- 性能1.6倍于x86!NVIDIA亮出Vera CPU详细规格:88核、1.2TB/s LPDDR5X
- 时间:2026-07-22
-

- NVIDIA将详解DLSS5:AI生成逼真画面 但不会让游戏变质
- 时间:2026-07-20
-

- NVIDIA Jetson Thor家族新增T3000 T2000模组
- 时间:2026-07-19
-

- NVIDIA联合日本政经界推出全球首个国家级AI基础设施
- 时间:2026-07-18
-

- NVIDIA不想让你看的RTX 50热点温度:五款工具已绕过限制!
- 时间:2026-07-17
-

精选合集
更多大家都在玩
热门话题
大家都在看
更多-
- iOS 13.5.1电池续航差是电池耗电问题吗
- 时间:2026-07-25
-

- 苹果教育优惠开启 附购买攻略
- 时间:2026-07-25
-
- 苹果iOS 14 beta 2 测试版主要更新内容:除细节变化外修复多项Bug
- 时间:2026-07-25
-
- iOS 14 beta 2 是否解决内存占用过多问题?
- 时间:2026-07-25
-

- 受欢迎的奥特曼游戏有哪些
- 时间:2026-07-25
-
- iOS 14信息应用5大更新变化
- 时间:2026-07-25
-

- iOS 14正式版上线时间公布 官方全新介绍
- 时间:2026-07-25
-

- 最新苹果iOS 14 Beta 2版本更新内容全解析与升级教程
- 时间:2026-07-25