AI游刃有余 | AI业务7×24稳如磐石!InCloud AIOS可视化监控方案,让异构GPU了如指掌
时间:2026-01-07 | 作者: | 阅读:0据浪潮数据统计,智算中心60%以上的故障都出自GPU卡或GPU服务器的故障,这类故障动辄造成设备离线甚至直接的经济损失。在大模型推理服务 7 x 24 小时连续运行的今天,AI 基础设施的稳定性对业务至关重要。但现实痛点突出:云数据中心里GPU、TPU、XPU等各类异构加速卡并存,环境复杂、调用链长,传统监控往往“看得见指标摸不到本质,看得到报错找不到根因”。浪潮云海InCloud AIOS针对性打造可灵活扩展的平台级GPU监控方案,以“异构兼容、深度联动、细粒度可视、智能预警”四大核心亮点,破解监控难题,为AI业务筑牢稳定防线。
一、异构全兼容:统一模型打破硬件监控壁垒
传统监控工具对NVIDIA GPU支持完善,但对国产异构加速卡普遍存在覆盖不全、指标零散、适配周期长的问题,难以应对多品牌GPU共存的业务场景。
InCloud AIOS构建了灵活可扩展的平台级监控框架,从根源解决兼容痛点:
* 建立统一抽象模型:传统的监控系统往往通过“拼接”不同接口实现各类硬件的支持,InCloud AIOS将不同架构加速设备的使用率、显存占用、温度、功耗等核心指标标准化,打破硬件品牌差异;
* 自研可扩展监控框架:基于插件模式开发专属监控代理,按OpenTelemetry标准封装指标,代理北向提供metrics接口,通过推拉结合的方式提升实时性与并发能力;
* 快速适配多品牌:不仅完美支持英伟达全系列,还已快速完成多款主流国产GPU适配,无需重复开发即可接入新设备;
* 准实时分析与告警:监控中心搜集数据后,通过内置的元数据信息识别芯片架构,并存入时序数据库;告警模块则同步根据预设的告警策略实现准实时分析与告警,帮助运维人员及时发现异常,并通过短信、邮件、企业微信等多种方式进行推送。

平台级统一监控方案
二、深度指标联动:精准定位性能瓶颈
传统监控系统大多只聚焦 GPU 占用率、利用率等基础指标,但对大模型推理服务来说,这些表面数据很难反映加速设备的真实运行状态。
事实上,大模型多卡推理(如张量并行)高度依赖卡间数据同步——无论是权重分片分发,还是中间计算结果交换,链路吞吐性能直接决定整体推理效率。比如卡间互联吞吐触及上限时,数据传输时延会急剧增加;依据阿姆达尔定律,通信开销的攀升会直接拉低系统整体效率,极端情况下还会造成计算核心空转浪费。此时仅靠调整应用参数无济于事,必须通过优化卡间互联拓扑、调整并行策略等系统级手段才能破解。
InCloud AIOS通过深度集成NVIDIA DCGM等厂商底层接口,突破传统监控的指标局限,覆盖pwr(GPU功率消耗)、rxpci(PCI接收速率)、txpci(PCI发送速率)等更纵深的运行指标。更关键的是,它创新性地将硬件运行状态与推理服务性能做联动分析,既能帮助用户实现资源的全面监控与高效利用,更能精准定位传统工具无法察觉的隐藏性能瓶颈。
三、细粒度映射:从物理卡到业务Pod的全链路可视
云原生推理场景中,一张物理GPU常通过MIG(Multi-Instance GPU)、虚拟化技术切分为多个计算单元,分配给不同Pod使用。传统监控仅支持“卡级别”监控,根本无法满足应用级细粒度管控需求。
例如,在多GPU节点集群中,系统可能同时运行Llama3-70b、Qwen-7b、DeepSeek-671b 等不同规模大模型,以及embedding、reranker等辅助模型,通过精细调度将Pod与指定 GPU绑定——这种复杂部署下,传统工具无法定位单个Pod的资源占用情况,给多租户计费、故障排查、性能优化带来巨大挑战。
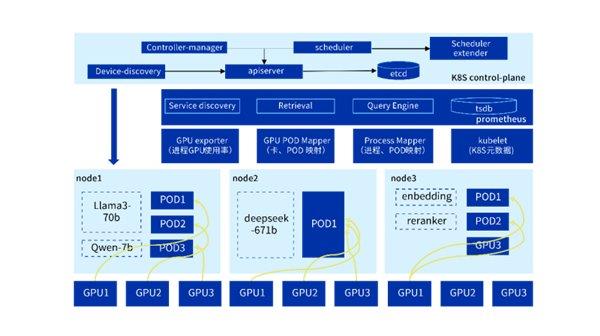
服务(模型)级别显卡性能监控
InCloud AIOS创新性突破细粒度监控瓶颈,实现从物理卡到业务Pod的全链路可视:
1.先通过节点设备插件搜集显卡拓扑信息,结合平台CMDB数据库,建立Pod与底层加速卡实例(含切分后的子实例)的关联;
2.再通过自研监控代理采集主机进程级GPU使用率,借助专属的GPU POD Mapper 与Process Mapper框架,完成GPU、Pod、进程的精准映射;
3.最终实现推理任务的细粒度资源监控与分析,支持按业务线、模型类型、命名空间等多维度聚合统计,彻底解决多租户场景下的监控盲区。
四、智能预警:未雨绸缪守护业务连续运行
在复杂的异构推理集群中,硬件异常向来防不胜防——一次ECC内存错误、一次PCIe链路故障,都可能直接引发服务抖动甚至完全中断,给业务连续性带来巨大风险。
InCloud AIOS 构建主动预警体系,实现“故障早发现、根因快定位”:
* 深度集成DCGM等厂商原生接口组件,实时采集并可视化展示GPU使用率、显存占用、带宽、温度、功耗等关键指标,还支持根据业务需求灵活定制检查项,实现精准高效的硬件健康监控;
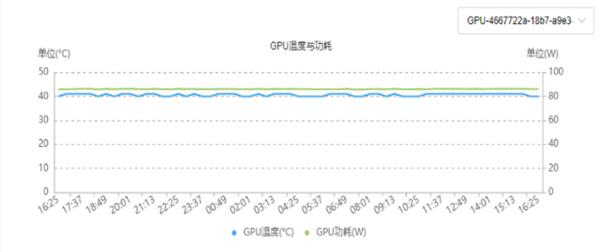
GPU温度和功耗监控
* 支持配置“显卡不可纠正内存错误(uncorrectable memory errors)”等核心异常检测规则,同时实时追踪多维度指标趋势与设备日志,全方位覆盖硬件运行状态,助力故障快速研判;
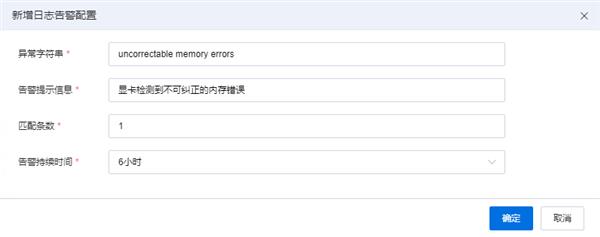
GPU的日志告警
* 内置多种成熟的时间序列预测算法,能够基于历史数据提前识别显存飙升、温度异常等潜在风险,让运维人员在故障发生前就能介入干预,从根源降低业务中断概率。
结语:全栈监控赋能,让异构AI部署更稳更省心
InCloud AIOS的GPU全栈监控方案,彻底解决了传统监控“兼容差、粒度粗、不深入、预警晚”的痛点。无论是多品牌异构GPU的统一管理,还是推理服务的性能优化、故障排查,都能实现“看得见指标、看得透本质,找得到根因、防得住风险”。
目前,该方案已广泛适配主流GPU,为政府、金融、医疗、教育等行业的大模型推理服务提供稳定支撑,让私有云部署的AI业务真正实现7×24小时无忧运行。

来源:https://news.mydrivers.com/1/1097/1097055.htm
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- OpenClaw+NUC+联想百应智能体,联想百应发布长期记忆AI终端
- 时间:2026-02-12
-

- 龙魂收官,马力全开:微星笔记本12项媒体奖项敬献新年
- 时间:2026-02-12
-

- 京东与TCL签署2026年战略合作协议 锚定155亿销售目标
- 时间:2026-02-12
-

- 淘天集团获浙江省科技进步一等奖!
- 时间:2026-02-12
-

- 落地阿布扎比市中心 文远知行与优步定下2027年1200辆Robotaxi新目标
- 时间:2026-02-12
-

- 京东与美的、海尔、海信、TCL达成2026年合作协议 冲刺1800亿销售目标
- 时间:2026-02-12
-

- 15w左右的车油车标杆!瑞虎9以越级配置满足用车高期待
- 时间:2026-02-12
-

- 解构汽车流通“不可能三角”:ZCAR竹子买车的效率革命与产业基础设施进化论
- 时间:2026-02-12
精选合集
更多大家都在玩












大家都在看
更多-

- 抖音带谈字网名男生霸气(精选100个)
- 时间:2026-02-12
-
- psm什么意思?是什么意思
- 时间:2026-02-12
-

- 挪威语网名男生霸气两个字(精选100个)
- 时间:2026-02-12
-

- mindmanager调整项目间距的操作教程
- 时间:2026-02-12
-
- 我册你们码是什么梗是什么意思
- 时间:2026-02-12
-

- LOL海克斯大乱斗物转蛤蟆怎么玩
- 时间:2026-02-12
-

- 摩尔庄园的拉姆变身值怎么增加
- 时间:2026-02-12
-

- LOL海克斯大乱斗卡兹克怎么玩
- 时间:2026-02-12