本地AI新拐点 联想AI工作站全面适配DeepSeek-V4大模型!
时间:2026-04-26 | 作者: | 阅读:0DeepSeek再炸场!4月24日,DeepSeek-V4系列模型预览版正式上线并同步开源,联想AI工作站完成全面适配。

四大优势,模型本地化部署迎来新拐点
效率天花板:百万级超长上下文
DeepSeek V4通过100万Token的超长上下文(约75万字)标配和混合注意力架构(CSA+HCA)创新,突破长文本壁垒,可一次性处理整部《三体》三部曲或一个完整的代码仓库。通过全新的稀疏注意力机制,V4-Pro在处理百万token时,计算量仅为前代的27%,显存占用低至10%;V4-Flash更将这两个数字压到10% 和7%。
性能登顶:全球顶级的综合实力
基于创新的架构,DS-V4的性能也跻身全球第一梯队,多项关键能力达到甚至超越了顶级闭源模型。
数学 / STEM / 竞赛代码能力超越所有公开评测开源模型,与 GPT-5.4、Claude Opus 4.6 等顶级闭源模型比肩
Agentic Coding(代码智能体) 达开源最优水平,其在自主规划、工具调用和长程任务执行方面进步明显,内部使用体验甚至优于Claude Sonnet 4.5。
世界知识测评大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1。
两大版本:旗舰与普惠并行
DeepSeek-V4系列提供两种基于MoE架构的模型,以满足不同场景的需求。其中,Pro版(专家模式)面向复杂推理、Agent任务、代码工程、科研分析等高难度场景;Flash版(快速模式)则面向日常高频、快速响应场景。
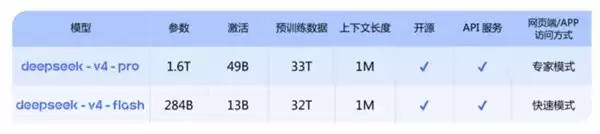
值得一提的是,V4-Flash在简单任务上表现接近Pro版,但成本仅为后者的18%,对于大多数常规应用场景,Flash版是更具性价比的选择。
原生多精度设计:从源头适配全档位量化
DeepSeek-V4采用 “FP4+FP8混合精度” 的量化感知训练(QAT)策略,让模型原生理解低精度运算,这为向下兼容 INT8/INT4 等格式奠定了极好的基础。对企业来说,这意味着DeepSeek-V4不仅能在云端运行,也能更好地适配本地AI工作站,从开发验证到业务落地都更高效。
联想AI工作站全面适配,
面向DeepSeek-V4的不同版本,联想AI工作站完成适配,本地化部署推荐如下:

DeepSeek V4-flash:推荐两台ThinkStation PGX互联,打造桌面级AI超算底座
DeepSeek-V4-Flash 主打高频、快速、普惠,适配个人开发者、小型及内容创作团队,可高效完成长文本处理、代码辅助、知识库问答、本地 Agent 搭建等任务。
联想 ThinkStation PGX AI超算工作站,搭载 NVIDIA GB10 高性能芯片,配备128GB一致性内存、单台提供1000TOPS AI算力与全套专业开发软件栈,单台可支持 200B 参数模型,双机互联最高适配 405B 参数模型,完美承载 DeepSeek-V4-Flash 本地推理、长上下文处理与复杂 Agent 应用的部署需求。

DeepSeek V4-Pro推荐:推荐ThinkStation PX旗舰双路AI工作站,支持百人团队并发使用
ThinkStation PX面向专业AI开发、数据科学、工程仿真与复杂计算任务,可用于模型适配、量化推理、行业化验证和企业级AI工作流开发。可支持至多4张顶级专业显卡,显存可以高达288GB(72*4),最高支持百人团队的多用户并发使用。对于生产级推理等更高阶需求,也可进一步与联想服务器形成“工作站开发验证 + 服务器生产部署”的协同架构。

强强联合,让AI转型触手可及
最新IDC报告(2025年12月),联想工作站产品凭借47.4%的市场份额雄踞榜首。以强大性能、快速部署、本地安全、多维生态、全栈服务五大核心优势,成为企业和个人 AI 转型的 “最佳拍档”。相比传统云服务或服务器方案,它实现了算力下沉到桌面、数据留在本地、成本可控、效率倍增的多重突破。让 AI 开发从 “云端依赖” 走向 “本地自主”,持续为各行业智能化升级筑牢算力底座,真正开启高效可控、落地性更强的 AI 普惠。

来源:https://news.mydrivers.com/1/1118/1118552.htm
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- 首创只吹风不吹人!海尔空调应用呼吸级雷达技术树防直吹新标杆
- 时间:2026-04-26
-

- 赴一场春日光景之约 京东相机五一狂欢优惠即将开启领999元焕新基金
- 时间:2026-04-26
-

- 北汽集团与宁德时代深化战略合作 共筑全面换电新生态
- 时间:2026-04-26
-

- 小户型日常 轻量化洗地机哪种好 五大核心清洁维度权威测评
- 时间:2026-04-26
-
- 行业首发!鸿蒙版雅迪智行App深度集成百度地图SDK 上线投屏导航 实现“抬头骑行 眼不离路”
- 时间:2026-04-26
-
- 彭博社直播专访赛力斯张正萍:以持续高强度研发投入引领行业
- 时间:2026-04-26
-

- 从8KRAW到米拍 海信百吋电视为何能满足专业影像的严苛标准
- 时间:2026-04-25
-

- 跳出数码参数内卷 海信百吋电视给出摄影行业适配方案
- 时间:2026-04-25
精选合集
更多大家都在玩
热门话题

大家都在看
更多-

- 小米音响蓝牙配对电脑后没声音怎么办
- 时间:2026-04-26
-

- 哈罗电动车充电口在座桶下面吗
- 时间:2026-04-26
-

- 机械键盘切换灯光需要驱动吗
- 时间:2026-04-26
-

- 永恒树之歌创世 第三种性别设定与核心玩法详解
- 时间:2026-04-26
-
- 无双屠龙boss系统怎么玩
- 时间:2026-04-26
-
- 地下城堡4秩序阵营有什么角色
- 时间:2026-04-26
-

- 永恒树之歌创世村民邀请方式全解析 永恒树之歌村民邀请方法与实用技巧汇总
- 时间:2026-04-26
-
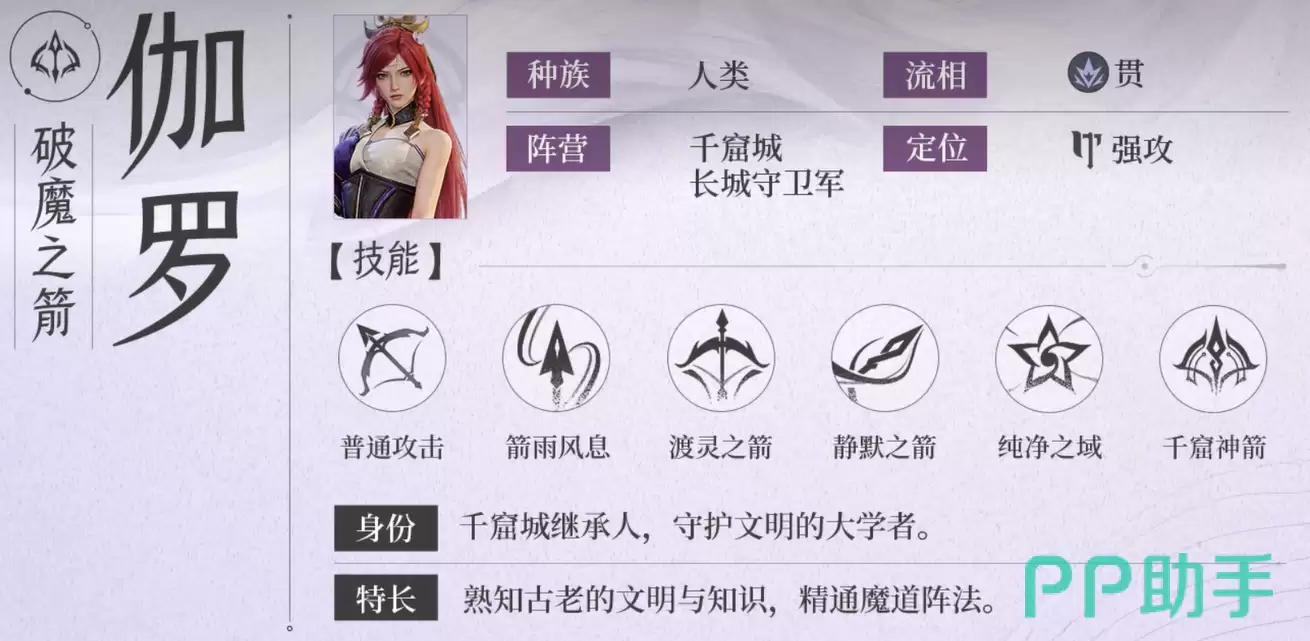
- 王者荣耀世界伽罗值得入手吗 王者荣耀世界伽罗强度与实战表现分析
- 时间:2026-04-26