MHA2MLA— 复旦、上海AI Lab等推出优化LLM推理效率的方法
时间:2025-03-19 | 作者: | 阅读:0mha2mla:高效微调transformer模型的利器
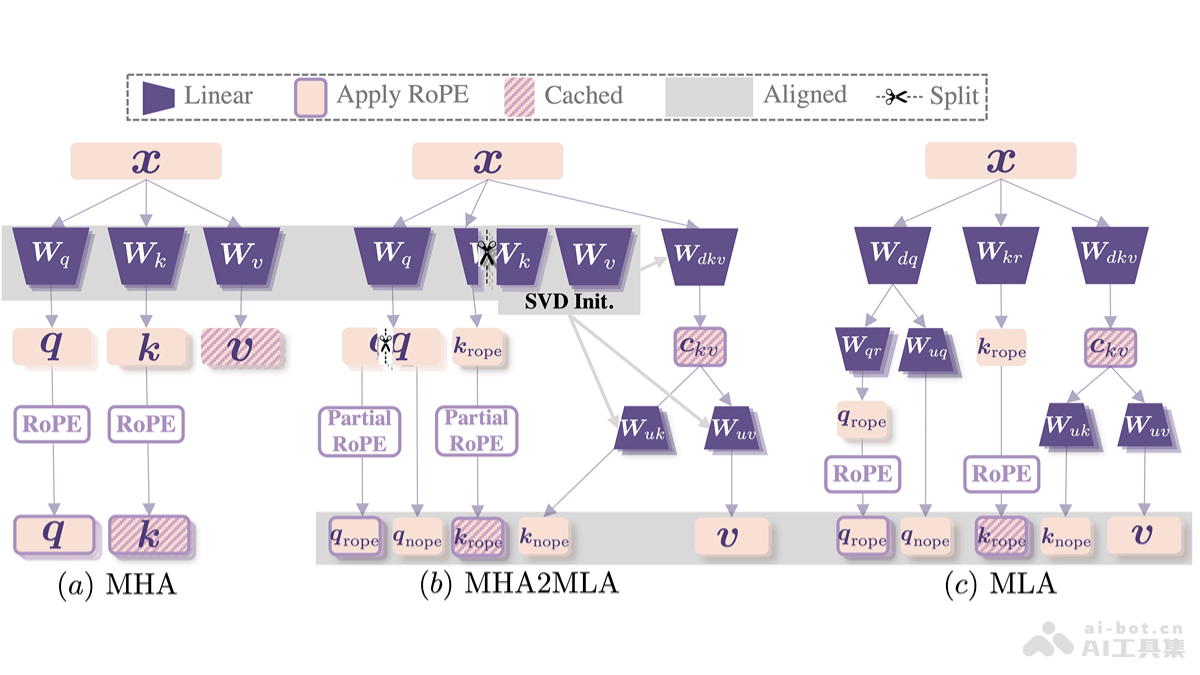
MHA2MLA是由复旦大学、华东师范大学和上海AI Lab等机构联合研发的一种数据高效的微调方法,它能够显著提升基于Transformer的大型语言模型(LLM)的推理效率,并降低推理成本。 该方法的核心在于引入DeepSeek的多头潜在注意力机制(MLA),并通过两个关键策略实现:部分旋转位置编码(Partial-RoPE)和低秩近似(Low-Rank Approximation)。
核心功能与优势:
- 大幅缩减KV缓存: 通过低秩压缩技术,最大程度地减少KV缓存大小(最高可达96.87%),有效降低内存占用。
- 性能损耗极低: 仅需使用原始数据的0.3%到0.6%进行微调,即可将性能损失控制在极小范围内(例如,LongBench性能仅下降0.5%)。
- 兼容性强: 可与量化技术(如4-bit量化)结合使用,进一步提升推理效率。
- 数据高效: 在资源受限的环境下,也能快速完成从多头注意力机制(MHA)到MLA的架构转换。
技术原理详解:
MHA2MLA的效率提升主要源于以下两项技术:
- Partial-RoPE: 旋转位置编码(RoPE)在MHA中用于编码位置信息。Partial-RoPE通过分析每个维度对注意力分数的贡献,移除贡献较小的维度,从而减少计算和内存开销,同时保留关键位置信息。
- 低秩近似 (Low-Rank Approximation with Joint SVD): MLA利用低秩近似来压缩键值矩阵(KV),减少内存占用。MHA2MLA采用联合奇异值分解(Joint SVD)对键和值矩阵进行联合分解,而非分别处理,从而更好地保留键值间的交互信息,并实现更有效的压缩。
项目信息与应用场景:
- GitHub仓库: https://www.php.cn/link/be6ea238d9be0fc60080a6f8a8188817
- arXiv论文: https://www.php.cn/link/be6ea238d9be0fc60080a6f8a8188817
MHA2MLA的应用场景广泛,包括:
- 边缘设备部署: 适用于资源受限的智能终端和物联网设备。
- 大规模模型推理: 降低硬件成本和能耗。
- 结合量化技术: 进一步优化推理性能,适用于实时应用场景,如实时对话和在线翻译。
- 长文本处理: 有效缓解长文本任务的内存瓶颈。
- 快速模型迁移: 降低模型迁移成本。
总而言之,MHA2MLA提供了一种高效且经济的微调方法,为在各种资源受限的环境中部署和使用大型语言模型提供了强有力的支持。

来源:https://www.php.cn/faq/1258386.html
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-
- 卡厄斯梦境国服开荒指南与开服奖励详解
- 时间:2026-05-27
-

- 免费在线试玩MCJS游戏 无需下载直接畅玩
- 时间:2026-05-27
-

- 学生通PC版网页登录入口及数字化教育云平台使用指南
- 时间:2026-05-27
-

- 踢踏爵士的冒险毁灭之药卷轴获取位置详解
- 时间:2026-05-27
-

- 毁灭之药技能书与卷轴位置获取攻略
- 时间:2026-05-27
-
- PxCook毛玻璃模糊半径参数查看与读取方法
- 时间:2026-05-27
-
- 搞机助手模块功能详解与使用教程
- 时间:2026-05-27
-

- 花小猪打车添加途经点教程 轻松设置多目的地行程
- 时间:2026-05-27
精选合集
更多大家都在玩

大家都在看
更多-

- 原神妮露角色强度解析与培养攻略
- 时间:2026-05-26
-

- 王者荣耀世界游戏设置优化指南
- 时间:2026-05-26
-

- 三角洲行动M7战斗步枪最佳改装方案推荐
- 时间:2026-05-26
-

- 卡厄思梦境卢克卡牌技能效果详解
- 时间:2026-05-26
-
- 异环无名医院快速通关攻略与实用技巧
- 时间:2026-05-26
-
- 王者荣耀世界体力高效规划指南与技巧
- 时间:2026-05-26
-

- 烹饪青菜时,以下哪种做法更能保持营养和口感 蚂蚁庄园今日答案5.25
- 时间:2026-05-26
-

- 光遇5月26日每日任务怎么做 图文攻略详解
- 时间:2026-05-26