



















ChildMandarin— 智源联合南开开源的低幼儿童中文语音数据集
时间:2025-04-09 | 作者: | 阅读:0childmandarin:专为3-5岁儿童打造的普通话语音数据集
智源研究院与南开大学计算机学院人类语言技术实验室(HLT Lab)联合推出ChildMandarin,这是一个针对3-5岁儿童普通话语音的大型数据集。它包含来自中国22个省份的397名儿童的41.25小时高质量语音数据,数据采集过程模拟真实自然对话场景,确保数据真实可靠,并平衡了性别分布。ChildMandarin的发布填补了低幼儿童语音数据领域的空白,将有力推动儿童语音识别、语言发展研究以及智能语音交互系统的发展。

ChildMandarin的核心应用:
- 提升儿童语音识别技术: ChildMandarin为自动语音识别 (ASR) 模型提供海量训练数据,显著提升模型对3-5岁儿童语音的识别准确率和鲁棒性。
- 儿童说话人识别: 该数据集支持说话人验证 (SV) 任务,有助于开发能够准确识别和区分不同儿童声音的系统,应用于儿童身份认证等场景。
- 儿童语言发展研究: ChildMandarin为儿童语言学研究提供宝贵的数据资源,有助于开发更有效的儿童语言学习工具和互动教育系统。
ChildMandarin的技术细节:
数据采集采用家长引导式对话,模拟自然交流,并使用智能手机(Android和iOS)进行录音,确保16kHz采样率和16位精度的高质量音频。专业人员对数据进行人工标注,包括发音、停顿、重复等语言现象,并记录说话人的年龄、性别、籍贯、录音设备和口音等级等元数据。模型训练和评估采用多种先进的ASR模型(如Transformer、Conformer、Paraformer)和技术(如CTC、AED、RNN-T),并对预训练模型(如HuBERT、Whisper)进行微调。说话人验证则采用说话人嵌入提取模型(如x-vector、ECAPA-TDNN、ResNet-TDNN)。数据集被划分为训练集、验证集和测试集,确保模型评估的科学性和有效性。
获取ChildMandarin:
- GitHub: https://www.php.cn/link/618b8f8031405754a8c4219c1b8c905e
- Hugging Face: https://www.php.cn/link/618b8f8031405754a8c4219c1b8c905e
- 论文: https://www.php.cn/link/618b8f8031405754a8c4219c1b8c905e
ChildMandarin的应用前景:
ChildMandarin的应用范围广泛,包括:
- 儿童语言学习应用: 开发智能语音辅助学习工具,提升儿童语言能力。
- 互动教育平台: 为儿童教育软件和互动学习平台提供更自然的语音交互功能。
- 智能玩具: 提升智能玩具的语音识别能力,增强互动体验。
- 儿童语音助手: 优化语音助手对儿童语音的识别和响应。
- 儿童语言发展监测: 辅助监测儿童语言发展和健康状况,支持早期干预。

福利游戏
相关文章
更多-

- 4月1-13日全国乘用车零售51.5万辆 同比增长幅度8%
- 时间:2025-04-17
-

- 东安动力:今年商用车产品销量预计达60万台,上半年将实现30+万台
- 时间:2025-04-17
-

- 适合小白的无代码开发平台有哪些优点?
- 时间:2025-04-17
-

- 软件开发外包相比自行开发有哪些优势?
- 时间:2025-04-17
-

- 物联网(IoT)应用开发是指什么?
- 时间:2025-04-17
-

- APP上线后还需要注意些什么?
- 时间:2025-04-17
-

- 如何做好APP推广?
- 时间:2025-04-17
-

- APP跳转到小程序怎么实现?
- 时间:2025-04-17
精选合集
更多大家都在玩








大家都在看
更多-
- 易校园怎么销户
- 时间:2025-04-17
-
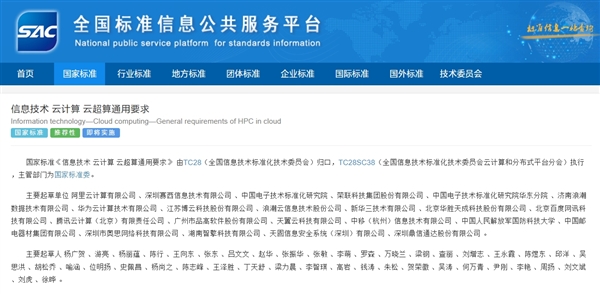
- 首个云超算国标正式发布:阿里云、华为云等联合起草
- 时间:2025-04-17
-
- 夸克浏览器如何观看片源
- 时间:2025-04-17
-
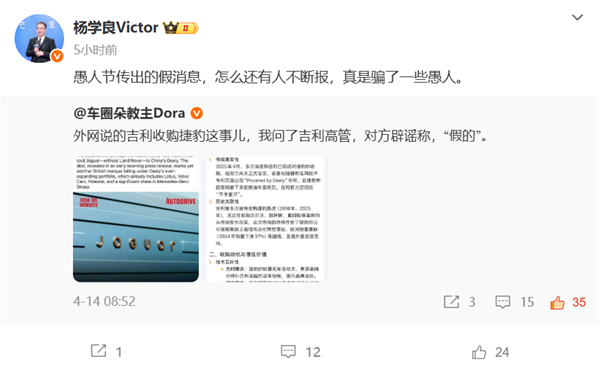
- 网传吉利已收购捷豹 总裁杨学良辟谣:愚人节传出的假消息
- 时间:2025-04-17
-
- 如何制作微信链接
- 时间:2025-04-17
-

- 博主质疑申请小米SU7订单延期需补齐尾款:王化回应
- 时间:2025-04-17
-

- NFT概念详解与龙头币AXS分析
- 时间:2025-04-17
-

- OPPO K12s官宣:千元续航小霸王 五年都流畅
- 时间:2025-04-17