



















大模型召回测试新困境:数据量激增下如何保障高精准率?
时间:2025-04-09 | 作者: | 阅读:0保障大模型召回测试高精准率可通过以下措施:1.提高向量质量:优化嵌入模型、微调模型、降维和正则化;2.改进索引结构:选择合适的索引方法、精细化调整索引参数;3.优化距离度量:选择适当的距离度量、进行距离度量标准化;4.改进查询策略:采用多轮查询优化、查询重排序;5.数据增强与处理:进行数据预处理、数据增强;6.通过反馈机制优化:利用用户反馈学习、引入主动学习;7.多模态融合:融合不同模态的向量进行检索。

- 提高向量质量
- 优化嵌入模型:采用高质量的嵌入模型,如 OpenAI 的 GPT 系列、CLIP、BERT、SimCSE 等,以生成语义更准确的向量。
- 微调模型:在特定领域的数据上对模型进行微调,使嵌入更契合数据特点。
- 降维和正则化:在向量数据存储前,对高维向量进行降维(如 PCA 或 t-SNE)和正则化处理,减少噪声干扰,确保数据分布均匀。
- 改进索引结构
- 选择合适的索引方法:根据数据量、查询实时性需求和计算资源,选择如 FAISS(适用于大规模向量搜索,支持多种索引结构)、HNSW(适合处理稀疏向量或大规模数据集,准确性较高)等合适的向量数据库索引方法。
- 索引的精细化调整:调整索引参数,如距离度量方式、候选列表大小等,提高搜索精度。
- 优化距离度量
- 选择适当的距离度量:依据数据集和应用场景,通过实验选择欧式距离、余弦相似度、曼哈顿距离等合适的距离度量方式。
- 距离度量标准化:对输入向量进行适当标准化(如 L2 归一化或 Z - score 标准化),避免特征对距离计算产生偏差。
- 改进查询策略
- 多轮查询优化:采用逐步筛选、分层查询的方式,先初步检索返回较多候选项,再对候选项深入搜索,精确定位最相关结果。
- 查询重排序:在初步检索后,使用更精确的排序算法,如结合传统的排名学习算法(如学习排序,RankNet)或深度学习模型来优化排序,提高检索结果的相关性。
- 数据增强与处理
- 数据预处理:对输入到向量数据库的数据进行有效清洗和规范化,如对文本数据去除停用词、进行分词、词干化等处理。
- 数据增强:通过引入额外语义信息或变换来增强数据集,增加训练和嵌入的多样性,减少模型在边缘情况的偏差。
- 通过反馈机制优化
- 用户反馈学习:根据用户的点击行为或反馈,利用机器学习模型调整向量权重或改进索引结构,使系统更准确地反映用户实际需求。
- 主动学习:引入主动学习机制,从少量标注数据中选择最能改进模型的样本进行训练,提高检索准确性。
- 多模态融合:若数据集包含多种类型(如文本、图片、音频等),考虑融合不同模态的向量进行检索,使用跨模态的嵌入模型来融合文本和图像等的向量,实现跨模态检索,提高准确性。

福利游戏
相关文章
更多-

- 4月1-13日全国乘用车零售51.5万辆 同比增长幅度8%
- 时间:2025-04-17
-

- 东安动力:今年商用车产品销量预计达60万台,上半年将实现30+万台
- 时间:2025-04-17
-

- 适合小白的无代码开发平台有哪些优点?
- 时间:2025-04-17
-

- 软件开发外包相比自行开发有哪些优势?
- 时间:2025-04-17
-

- 物联网(IoT)应用开发是指什么?
- 时间:2025-04-17
-

- APP上线后还需要注意些什么?
- 时间:2025-04-17
-

- 如何做好APP推广?
- 时间:2025-04-17
-

- APP跳转到小程序怎么实现?
- 时间:2025-04-17
精选合集
更多大家都在玩








大家都在看
更多-
- 易校园怎么销户
- 时间:2025-04-17
-
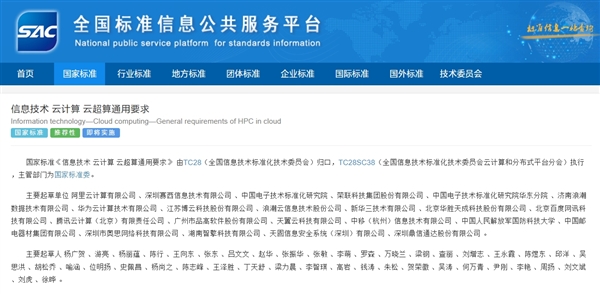
- 首个云超算国标正式发布:阿里云、华为云等联合起草
- 时间:2025-04-17
-
- 夸克浏览器如何观看片源
- 时间:2025-04-17
-
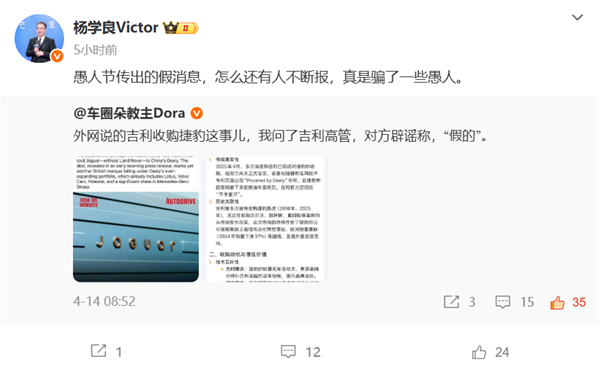
- 网传吉利已收购捷豹 总裁杨学良辟谣:愚人节传出的假消息
- 时间:2025-04-17
-
- 如何制作微信链接
- 时间:2025-04-17
-

- 博主质疑申请小米SU7订单延期需补齐尾款:王化回应
- 时间:2025-04-17
-

- NFT概念详解与龙头币AXS分析
- 时间:2025-04-17
-

- OPPO K12s官宣:千元续航小霸王 五年都流畅
- 时间:2025-04-17