



















Kimi Chat网页总结不准?如何精准提取核心信息
时间:2025-06-25 | 作者: | 阅读:0kimi chat网页总结不准的原因及解决方法如下:1. 网页结构解析与数据清洗,使用beautiful soup、lxml等html解析库提取正文内容,并通过正则表达式去除噪声信息;2. 信息过滤与重要性排序,采用关键词提取、tf-idf、textrank等算法筛选关键信息,并结合自定义停用词表和关键词库提升准确性;3. 语义优化与摘要生成,通过prompt工程明确摘要目标和风格,或微调模型以适应特定领域任务,同时可融合多模型输出提高质量;4. 后处理与人工校对,确保最终摘要无误。此外,选择解析库时需综合考虑速度、容错性、易用性和功能性,而tf-idf的局限可通过引入词向量、bm25算法或主题模型进行改进。prompt工程在摘要生成中能有效引导模型输出符合要求的结果。

Kimi Chat网页总结不准,是因为AI模型在处理复杂信息时,容易受到网页结构、噪声信息和语义理解的限制。要精准提取核心信息,需要结合网页解析、信息过滤和语义优化等多种技术手段。
解决方案
网页结构解析与数据清洗: Kimi Chat依赖于网页的结构化信息进行总结,但很多网页结构复杂,存在大量与核心内容无关的元素(如广告、导航栏、侧边栏等)。第一步是使用HTML解析库(如Beautiful Soup、lxml)精准提取正文内容。同时,利用正则表达式或其他文本处理工具,去除HTML标签、特殊字符、多余空格等噪声信息,保证输入文本的纯净度。
from bs4 import BeautifulSoupimport redef clean_html(html_content): soup = BeautifulSoup(html_content, 'html.parser') # 移除 script, style, meta 标签 for tag in soup([”script“, ”style“, ”meta“]): tag.decompose() text = soup.get_text() # 使用正则表达式去除多余空格和特殊字符 text = re.sub(r's+', ' ', text).strip() return text# 示例html = ”“”<html><head><title>Example</title></head><body><h1>Main Content</h1><p>This is the main content.</p><div id=“ad”>Advertisement</div></body></html>“”“cleaned_text = clean_html(html)print(cleaned_text) # 输出:Main Content This is the main content.登录后复制
信息过滤与重要性排序: 清洗后的文本仍然可能包含大量冗余信息。可以采用关键词提取、TF-IDF、TextRank等算法,识别并筛选出文本中的关键信息。这些算法能够根据词频、词语之间的关系等指标,评估每个词或句子的重要性。此外,可以结合领域知识,构建自定义的停用词表和关键词库,进一步提高信息过滤的准确性。
语义优化与摘要生成: 将过滤后的关键信息输入到Kimi Chat或其他摘要生成模型中。为了提高摘要的质量,可以采用以下策略:
- Prompt工程: 优化输入模型的Prompt,明确指示模型需要提取的核心信息类型和摘要风格。例如,可以要求模型生成“包含关键数据和结论的简洁摘要”。
- 微调模型: 如果有足够的数据,可以对Kimi Chat或其他预训练模型进行微调,使其更适应特定领域的文本摘要任务。
- 多模型融合: 尝试使用不同的摘要生成模型,并对它们的输出进行融合,以获得更全面、准确的摘要。
后处理与人工校对: 即使经过上述优化,生成的摘要仍然可能存在错误或不准确之处。因此,建议对摘要进行人工校对,确保其符合实际情况。
如何选择合适的网页解析库?
选择网页解析库时,需要考虑以下因素:
- 解析速度: lxml通常比Beautiful Soup更快,尤其是在处理大型HTML文档时。
- 容错性: Beautiful Soup具有较强的容错性,能够处理不规范的HTML代码。
- 易用性: Beautiful Soup的API更简洁易懂,适合初学者使用。
- 功能性: lxml支持XPath,可以更灵活地定位HTML元素。
根据实际情况,可以选择最适合的网页解析库。如果需要处理大量HTML文档,并且对解析速度有较高要求,可以选择lxml。如果HTML代码不规范,或者需要快速上手,可以选择Beautiful Soup。
TF-IDF算法的局限性及改进方法
TF-IDF算法虽然简单有效,但也存在一些局限性:
- 忽略语义信息: TF-IDF只考虑词频和文档频率,忽略了词语之间的语义关系。
- 对短文本效果不佳: 在短文本中,词频信息可能不够充分,导致TF-IDF算法效果下降。
- 容易受到停用词的影响: 即使使用了停用词表,仍然可能存在一些与核心内容无关的高频词,影响TF-IDF算法的准确性。
为了克服这些局限性,可以采用以下改进方法:
- 结合词向量: 将词向量引入TF-IDF算法,考虑词语之间的语义相似度。
- 使用BM25算法: BM25算法对TF-IDF算法进行了改进,考虑了文档长度的影响,更适合处理不同长度的文本。
- 引入主题模型: 使用LDA等主题模型,提取文本的主题信息,并将其作为TF-IDF算法的补充。
Prompt工程在摘要生成中的作用
Prompt工程是指通过设计合适的Prompt,引导模型生成期望的输出。在摘要生成中,Prompt工程可以起到以下作用:
- 明确摘要目标: 通过在Prompt中明确摘要的目标,例如“生成包含关键数据和结论的简洁摘要”,可以引导模型生成更符合需求的摘要。
- 控制摘要风格: 通过在Prompt中指定摘要的风格,例如“生成客观、简洁的摘要”,可以控制摘要的语言风格和表达方式。
- 引入领域知识: 通过在Prompt中引入领域知识,例如“针对医疗领域的文本,提取疾病、症状和治疗方案等关键信息”,可以提高摘要的准确性和专业性。
Prompt工程是一种简单有效的优化摘要生成效果的方法,值得深入研究和应用。
福利游戏
相关文章
更多-

- 昇腾杯-变化检测赛道复赛方案分享——PaddleCD
- 时间:2025-07-22
-

- 【图像去噪】第七期论文复现赛——SwinIR
- 时间:2025-07-22
-

- 使用PaddleDetection2.0自定义数据集实现火焰识别预测
- 时间:2025-07-22
-

- 【遥感影像分类】使用PaddleAPI搭建ResNet50实现遥感影像分类任务
- 时间:2025-07-22
-

- 心音智能检测
- 时间:2025-07-22
-

- 电脑蓝屏后重启反复循环 无法进入系统如何处理
- 时间:2025-07-22
-

- 电脑打印文档时出现乱码,如何解决?
- 时间:2025-07-22
-

- “机器学习”系列之决策树
- 时间:2025-07-22
大家都在玩









大家都在看
更多-
- 剑桥数字货币交易所:开启资产新纪元
- 时间:2025-07-22
-

- 称亲自开上了陡坡 余承东晒享界S9T实车:颜值与实力并存
- 时间:2025-07-22
-

- MSN币未来展望:机遇与挑战并存
- 时间:2025-07-22
-
- 电脑蓝屏时屏幕出现乱码 是显卡问题还是显示器故障
- 时间:2025-07-22
-

- Switch 2 OLED中框遭曝光:闲鱼惊现研发样品
- 时间:2025-07-22
-

- 电脑安装软件时提示 “权限不足”,怎么获取权限?
- 时间:2025-07-22
-

- 全球首架“三证齐全”吨级以上eVTOL交付:用于低空货运场
- 时间:2025-07-22
-
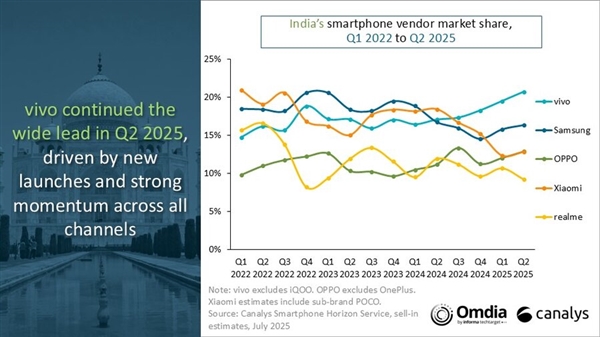
- vivo在印度市场连续4季度销量夺冠:Q2狂销810万台
- 时间:2025-07-22