NVIDIA要重塑AI:单用户速度可达2万Token每秒、能耗降1000倍
时间:2026-03-23 | 作者: | 阅读:03月23日消息,如果说前几年的AI重点是训练,那么现在的重点是推理,NVIDIA上周的GTC大会上已经发布了全新的LPU芯片,就是要重塑AI推理。
在GTC大会期间,NVIDIA首席科学家Bill Dally跟谷歌首席科学家Jeff Dean两位大神有了一番精彩的深度访谈,其中Dally就谈到了NVIDIA在做的一些研究进展。
AI推理对延迟的要求很高,Dally指出目前的瓶颈已经不是算力本身,瓶颈在通信开销上,NVIDIA正在研究片上通信的静态调度,将会彻底取消路由开销、排队和仲裁,通信速度接近光速本身。
目前的技术方案中,芯片从一角到另一角的延迟有几百纳秒之多,NVIDIA的技术方案可以做到30纳秒。
片外通信中,之前的方案是一步步提高带宽速率,现在做到了400Gbps甚至800Gbps,但这样的带宽也带来了复杂的信号处理及纠错机制,但速度如果从400Gbps降低到200Gbps,复杂问题反而会消失,只做序列化延迟的话,几个时钟周期就能完成。
Dally表示他有信心未来AI推理可以做到单用户每秒10000到20000Token的推理速度——作为对比,大家要知道目前很多人用在大模型AI推理速度,普遍在100Token每秒以内,甚至每秒60Token以上的速度就算高速了。

Dally表示做到这样的速度前提是用对了架构,他还以NVFP4精度做了例子对比,用这种精度做一次乘加运算需要消耗10飞焦的能量,但HBM4从外部读取数据大约消耗15皮焦能量,差距是1000倍以上。
改用SRAM缓存的话,读取数据的能耗也会变成10飞焦了,跟计算过程的消耗一个级别。
不过SRAM也不是没代价的,芯片成本比HBM还会高的,GTC大会上NVIDIA发布的LPU芯片LPU30也只能集成500MB SRAM缓存,跟GPU集成的288GB HBM4不是一个量级的。


来源:https://news.mydrivers.com/1/1111/1111093.htm
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-

- 吃灰老卡再战三年!大神魔改P100显卡:跑35B大模型提速88%
- 时间:2026-07-24
-
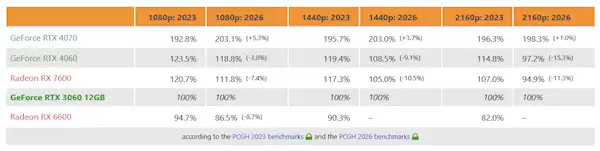
- RTX 3060 12GB越老越香!三年后竟反超RTX 4060和RX 7600
- 时间:2026-07-24
-

- 等等党彻底输了!NVIDIA显卡全线调涨价格:GDDR7和GDDR6无一幸免
- 时间:2026-07-23
-

- 警告:镓瓶当显卡支架如定时炸弹 漏液全毁
- 时间:2026-07-23
-

- 机箱内藏定时炸弹 玩家竟用镓瓶当显卡支架!漏了就全毁
- 时间:2026-07-22
-

- RGB灯区异常高温:RTX显卡背板直接融化!
- 时间:2026-07-21
-

- 不再靠低价抢市场 AMD AI显卡站稳了:比N卡贵40%还有人买
- 时间:2026-07-21
-

- GTX 1060问世整整十年了!曾霸榜Steam长达59个月
- 时间:2026-07-20
精选合集
更多大家都在玩
热门话题
大家都在看
更多-
- iOS 13.5.1电池续航差是电池耗电问题吗
- 时间:2026-07-25
-

- 苹果教育优惠开启 附购买攻略
- 时间:2026-07-25
-
- 苹果iOS 14 beta 2 测试版主要更新内容:除细节变化外修复多项Bug
- 时间:2026-07-25
-
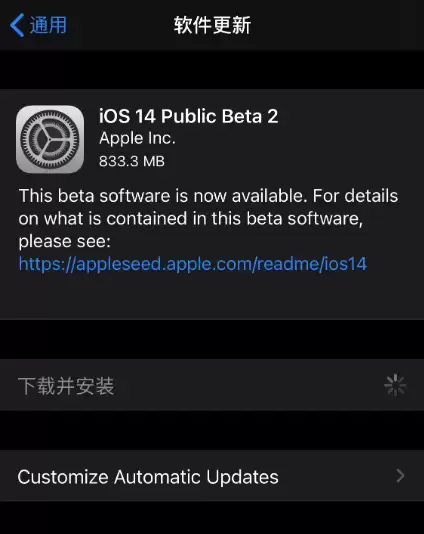
- iOS 14 beta 2 是否解决内存占用过多问题?
- 时间:2026-07-25
-

- 受欢迎的奥特曼游戏有哪些
- 时间:2026-07-25
-
- iOS 14信息应用5大更新变化
- 时间:2026-07-25
-

- iOS 14正式版上线时间公布 官方全新介绍
- 时间:2026-07-25
-

- 最新苹果iOS 14 Beta 2版本更新内容全解析与升级教程
- 时间:2026-07-25