如何评估与判断Capybara人工智能模型的优劣标准
时间:2026-05-22 | 作者:318050 | 阅读:0在人工智能浪潮席卷全球的今天,Capybara模型逐渐成为技术圈内热议的焦点。面对市场上琳琅满目的模型选项,一个核心问题浮出水面:究竟该如何判断一个Capybara模型的优劣?

准确性:不容有失的基石
评估模型,首当其冲要看准确性。一个真正出色的Capybara模型,其核心价值在于能在多样化的任务中交付高精度的结果。
无论是文本分类、情感分析,还是更具挑战性的机器翻译,它都必须精准地理解输入信息的细微之处,并输出符合甚至超越预期的答案。
简单说,错误率越低,模型的可靠性就越高。这是所有后续评估的起点。
泛化能力:从“考场”到“战场”
然而,只在熟悉的“考场”(训练数据)上得高分还不够。模型的泛化能力,即面对全新、未见过的数据时的表现,才是其真正实力的试金石。
优秀的模型能够将训练中学到的底层模式和知识,灵活地迁移到未知场景中,展现出强大的适应性和鲁棒性。这决定了它能否从实验室走向广阔的实际应用“战场”。

学习效率:平衡速度与效果的智慧
在算力宝贵的时代,模型的学习效率至关重要。一个好的Capybara模型应当能够快速地从海量数据中捕捉关键特征和规律,并在训练过程中高效地优化自身参数。
理想的状态是,用更短的训练时间、更少的计算资源,达到同样甚至更优的性能。这种高效率,直接关系到模型的开发成本和迭代速度。
稳定性:值得信赖的保证
稳定性是信任的基石。当多次处理相同或相似的任务时,模型应当给出一致、可靠的结果,避免出现难以预测的随机波动。
这种确定性对于实际部署至关重要。它确保了用户和开发者能够基于模型的输出做出稳健的决策,而无需担心结果朝令夕改带来的困扰。
可解释性:打开“黑箱”的钥匙
最后,对于金融、医疗等高敏感领域,模型的可解释性往往与性能同等重要。一个“好”的模型,不仅要给出答案,最好还能让人理解其决策背后的逻辑。
Capybara模型如果能够提供清晰的推理路径或依据,就能极大地增强用户的信任感,并便于在复杂业务中进行问题诊断与责任追溯,从而提升其实用价值。

总而言之,评估一个Capybara模型并非单一维度的考量,而需要从多个角度进行综合审视:
- 准确性
- 泛化能力
- 学习效率
- 稳定性
- 可解释性
把握住这些关键维度,我们才能更精准地甄别出真正优秀的模型,从而在推动各行业智能化升级的道路上,做出更明智的选择。

来源:整理自互联网
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-
- 准儿翻译机真实使用体验评测
- 时间:2026-07-04
-
- 热门行业指南是什么?高薪技术指南有哪些?一文看懂
- 时间:2026-06-28
-
- 人工智能Capybara模型质量评估方法
- 时间:2026-06-26
-
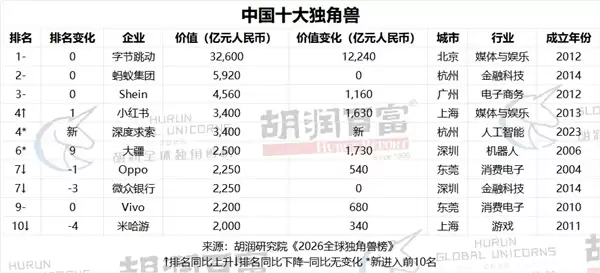
- 2026全球独角兽榜发布:1603家上榜 字节跳动居中国第一
- 时间:2026-06-25
-

- Patentics专利检索方法与实用技巧
- 时间:2026-06-23
-

- 不包括在华美资企业!财政部发文不得采购46家美国企业产品 包含通用、波音等
- 时间:2026-06-22
-

- 人工智能卡皮巴拉是否具备画画能力
- 时间:2026-06-18
-
- 人工智能训练自编码器的详细方法与实战技巧
- 时间:2026-06-07
精选合集
更多大家都在玩
大家都在看
更多-

- 高考志愿填报模板完整版附表格填写示例
- 时间:2026-07-04
-
- 2026好玩的挂机手游推荐
- 时间:2026-07-04
-

- 高考志愿填报规划师职业前景与报考指南
- 时间:2026-07-04
-
- 高考志愿填报实用指导与技巧
- 时间:2026-07-04
-
- 高考志愿填报时间安排
- 时间:2026-07-04
-
- 高考志愿填报系统使用技巧与注意事项
- 时间:2026-07-04
-

- 高考志愿填报模拟系统指南
- 时间:2026-07-04
-
- 高考志愿填报方法与技巧详解
- 时间:2026-07-04