人工智能训练自编码器的详细方法与实战技巧
时间:2026-06-07 | 作者:318050 | 阅读:0在人工智能领域,自编码器是一种相当实用的工具。它擅长对数据进行高效的编码与重构。通过训练自编码器,我们能够挖掘数据中隐藏的潜在特征,进而实现降维、异常检测等众多应用。那么,具体该怎么训练一个自编码器?下面从实操层面一步步拆解。
第一步:准备数据
训练的第一步,是收集并整理好数据集。数据质量的优先级很高,必要的清洗和预处理不能省。
比如归一化操作,把数据调整到合适的范围。这样后续训练才会更顺畅。


第二步:构建自编码器模型
接下来设计神经网络的结构。自编码器通常包含两个部分:
- 编码器:负责把输入数据映射到低维空间。
- 解码器:负责把低维表示还原回原始数据空间。
具体用什么层?全连接层、卷积层都可以,根据数据特点灵活选择。
第三步:定义损失函数
损失函数的选择很关键。最常用的是均方误差(MSE)。它衡量原始输入和经过编码-解码重构后数据之间的差异。
目标很明确:让损失值尽可能小,从而迫使自编码器学会高效编码和解码。
第四步:选择优化器
优化器负责调整模型参数,逐步降低损失函数的值。Adam、SGD等是常见选项,各有特点和适用场景。
具体选哪个?根据任务和数据量来定,没有绝对的标准答案。
第五步:训练模型
把准备好的数据喂进模型,用选好的优化器不断更新参数,让损失函数一点点降下来。过程中需要留意几个超参数:
- 训练轮数
- 批次大小
这些超参数会影响最终效果,值得反复调试。
第六步:评估模型
训练完成后,用测试集来检验自编码器的真实水平。可以通过以下方式直观判断:
- 计算重构误差
- 直接查看重构图像
如果重构误差偏大,就得考虑调整模型结构或者重新训练了。

第七步:应用与拓展
一个训练好的自编码器,后续可以应用到多个实际场景中,比如:
- 数据降维
- 特征提取
- 异常检测
除此之外,还可以继续拓展——比如和其他模型结合,进一步提升性能和应用范围。
掌握以上步骤,就能搭建出一个有效的自编码器,为人工智能的各项任务提供有力支撑。

来源:整理自互联网
免责声明:文中图文均来自网络,如有侵权请联系删除,心愿游戏发布此文仅为传递信息,不代表心愿游戏认同其观点或证实其描述。
相关文章
更多-
- 准儿翻译机真实使用体验评测
- 时间:2026-07-04
-
- 热门行业指南是什么?高薪技术指南有哪些?一文看懂
- 时间:2026-06-28
-
- 人工智能Capybara模型质量评估方法
- 时间:2026-06-26
-
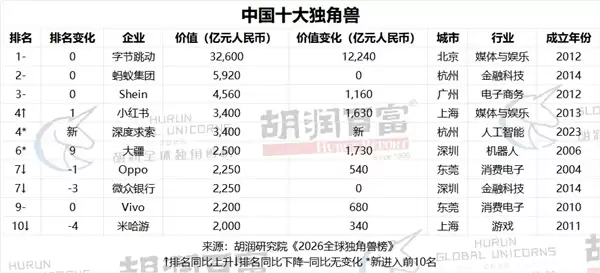
- 2026全球独角兽榜发布:1603家上榜 字节跳动居中国第一
- 时间:2026-06-25
-

- Patentics专利检索方法与实用技巧
- 时间:2026-06-23
-

- 不包括在华美资企业!财政部发文不得采购46家美国企业产品 包含通用、波音等
- 时间:2026-06-22
-

- 人工智能卡皮巴拉是否具备画画能力
- 时间:2026-06-18
-

- 2030年AI耗水量可达9.3 万亿升:够13亿非洲人用一年!
- 时间:2026-06-04
精选合集
更多大家都在玩
大家都在看
更多-

- 高考志愿填报模板完整版附表格填写示例
- 时间:2026-07-04
-
- 2026好玩的挂机手游推荐
- 时间:2026-07-04
-

- 高考志愿填报规划师职业前景与报考指南
- 时间:2026-07-04
-
- 高考志愿填报实用指导与技巧
- 时间:2026-07-04
-
- 高考志愿填报时间安排
- 时间:2026-07-04
-
- 高考志愿填报系统使用技巧与注意事项
- 时间:2026-07-04
-

- 高考志愿填报模拟系统指南
- 时间:2026-07-04
-
- 高考志愿填报方法与技巧详解
- 时间:2026-07-04