



















Nanonets-OCR-s— Nanonets推出的OCR模型
时间:2025-06-27 | 作者: | 阅读:0Nanonets-OCR-s是什么
nanonets-ocr-s(nanonets ocr small)是nanonets推出的图像到 markdown 的 ocr 模型,支持将图像中的文档内容转换为结构化的 markdown 格式。模型能提取文本,支持智能识别并处理复杂的文档元素,如 latex 方程、图像描述、签名、水印、复选框和复杂表格。nanonets-ocr-s基于深度学习模型,经过大量数据训练,支持多种文档类型,包括研究论文、财务文件和医疗表格等。输出的 markdown 格式内容能直接被大型语言模型处理,广泛应用在学术、法律、金融和企业等领域,极大地提高文档处理的效率和准确性。

Nanonets-OCR-s的主要功能
- LaTeX方程识别:自动将数学方程和公式转换为正确格式的LaTeX语法,包括行内数学表达式和显示方程的转换。
- 智能图像描述:用结构化标签描述文档中的图像,使其能被大型语言模型处理。支持描述单个或多个图像(如徽标、图表、图形、二维码等)的内容、风格和上下文,并在
标签中预测图像描述,页码在
标签中预测。
- 签名检测与隔离:识别隔离文档中的签名,对于法律和商业文档处理至关重要。模会在
标签中预测签名文本。 - 水印提取:与签名检测类似,模型支持检测、提取文档中的水印文本,预测的水印文本位于
标签中。 - 智能复选框处理:将表单中的复选框和单选按钮转换为标准化的Unicode符号,实现一致的处理。模型在
标签中预测复选框的状态。 - 复杂表格提取:从文档中提取复杂表格,转换为Markdown和HTML表格。
Nanonets-OCR-s的技术原理
- 视觉-语言模型(VLM):Nanonets-OCR-s基于视觉-语言模型(VLM),模型同时理解和处理视觉信息(如图像、表格、图表等)和语言信息(如文本内容)。模型基于联合学习视觉和语言特征,更好地理解文档的结构和内容。
- 数据集策划与训练:为训练该模型,策划包含超过25万页的文档数据集,涵盖多种文档类型,如研究论文、财务文件、法律文件、医疗文件、税务表格、收据和发票等。文档中包含图像、图表、方程、签名、水印、复选框和复杂表格等元素。用合成数据集和手动标注数据集进行训练。首先在合成数据集上训练模型,然后在手动标注的数据集上进行微调。合成数据集支持提供大量的训练样本,手动标注的数据集能提高模型在真实文档上的性能。
- 基础模型选择:选择Qwen2.5-VL-3B模型作为视觉-语言模型(VLM)的基础模型,在策划的数据集上进行微调,提高其在文档特定的光学字符识别(OCR)任务上的性能。
- 智能内容识别与语义标记:Nanonets-OCR-s能识别文档中的各种元素,对其进行语义标记。基于这种方式,模型将非结构化的文档内容转换为结构化、上下文丰富的Markdown格式,为下游任务提供更高质量的输入。
- 模型优化与调整:在训练过程中,不断优化模型的参数和结构,提高在各种文档类型和场景下的性能。,针对不同的功能需求,对模型进行特定的调整和优化,确保其在实际应用中的准确性和可靠性。
Nanonets-OCR-s的项目地址
- 项目官网:http://nanonets.com/research/nanonets-ocr-s/
- HuggingFace模型库:http://huggingface.co/nanonets/Nanonets-OCR-s
Nanonets-OCR-s的应用场景
- 论文数字化:将包含LaTeX方程和表格的学术论文转换为结构化的Markdown格式,方便研究人员进行文献整理、引用和进一步分析。
- 研究资料整理:快速提取研究论文中的关键信息,如实验数据、图表和结论,便于研究人员进行快速查阅和对比。
- 学术出版:帮助出版社将纸质或PDF格式的学术文献转换为适合在线发布的格式,提高文献的可访问性和可搜索性。
- 法律文档分析:快速识别和提取法律文档中的重要条款、案例引用和法律条文,提高法律研究和案件分析的效率。
- 财务报表处理:从财务报表中提取数据,如收入、支出和资产负债表,便于进行财务分析和报告生成。
福利游戏
相关文章
更多-

- 出发吧麦芬魔法师天赋怎么搭配 魔法师天赋选择攻略
- 时间:2025-07-23
-
- 时隙之旅高级幻灵誓约获取方法分享
- 时间:2025-07-23
-

- 基于改进Efficientnet的植物病虫害检测
- 时间:2025-07-23
-

- 基于Albumentations库的目标检测数据增强
- 时间:2025-07-23
-

- 机器学习项目三:XGBoost人体卡路里消耗预测
- 时间:2025-07-23
-

- 【图像去噪】第六期论文复现赛——MIRNet
- 时间:2025-07-23
-

- 『行远见大』手把手教你学 Python:基础篇(二)
- 时间:2025-07-23
-
- 美团优惠券怎么使用才最省钱 美团外卖新人老用户通用技巧全攻略
- 时间:2025-07-23
大家都在玩









大家都在看
更多-
- 剑桥数字货币交易所:开启资产新纪元
- 时间:2025-07-22
-

- 称亲自开上了陡坡 余承东晒享界S9T实车:颜值与实力并存
- 时间:2025-07-22
-

- MSN币未来展望:机遇与挑战并存
- 时间:2025-07-22
-
- 电脑蓝屏时屏幕出现乱码 是显卡问题还是显示器故障
- 时间:2025-07-22
-

- Switch 2 OLED中框遭曝光:闲鱼惊现研发样品
- 时间:2025-07-22
-

- 电脑安装软件时提示 “权限不足”,怎么获取权限?
- 时间:2025-07-22
-

- 全球首架“三证齐全”吨级以上eVTOL交付:用于低空货运场
- 时间:2025-07-22
-
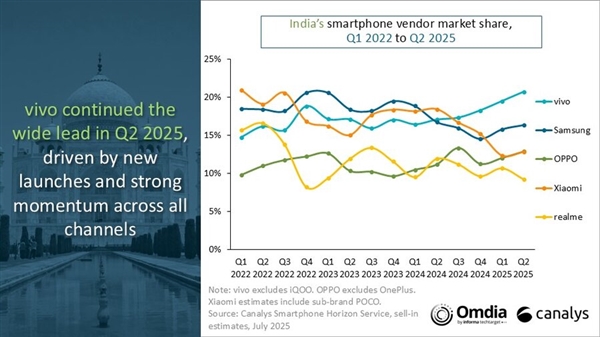
- vivo在印度市场连续4季度销量夺冠:Q2狂销810万台
- 时间:2025-07-22